





为什么大模型这么火
AI大模型是近两年兴起的一项非常火热的技术,相比于之前的人机对话,AI大模型的智能度非常高。在人机对话阶段人和机器的交流还比较生硬,机器基本是按照设定好句型来检索答案,问一句答一句,事先录入的句型越多机器能回答的问题就越多。
2022年11月30日,OpenAI发布ChatGPT后,彻底颠覆了人机自然语言对话这个场景,并且大大的扩展了人工智能的应用范畴,也让更多了人认识到AI真的会而且已经在快速的改变我们的工作和生活。据外界的报道,ChatGPT发布后仅5天注册用户就超过100万,创下了互联网的历史记录,到了2023年1月,发布刚1个多月的ChatGPT月活跃用户数量更是达到惊人的1亿。
之所以能在短时间内取得这么高的热度,主要来自于ChatGPT颠覆性的技术创新。
生成式人工智能,ChatGPT对话内容不在局限于事先设定好的对话句型,而是能够基于大模型中已经学习到的知识,结合对话场景创造并生成全新的内容,这是技术上的重大突破;
Transformer架构,ChatGPT基于深度学习模型Transformer,通过注意力机制学习语言中的语义关系,从而拥有强大的语言理解与生成能力;
人类反馈优化语言模型(RLHF),ChatGPT使用RLHF技术进行训练,通过人类训练师的反馈来优化模型,使其能够更准确地生成对话内容。
Kimi如何改变我的搜索习惯
Kimi是由月之暗面科技有限公司(Moonshot AI)开发的智能助手产品,公司创始人杨植麟毕业于清华大学计算机系,本科毕业后获得了前往卡内基梅隆大学攻读博士学位的机会,师从苹果公司AI负责人Ruslan Salakhutdinov和Google AI首席科学家William Cohen,是中国35岁以下NLP领域引用最高的研究者,Transformer-XL和XLNet两篇论文的第一作者,是大语言模型领域的核心技术。另外两位联合创始人周昕宇和吴育昕,也同样毕业于清华大学,具有丰富的学术和技术背景。
Kimi产品发布于2023年10月份,最核心的技术是长文本处理能力,产品发布之初支持20万汉字的长文本输入,2024年3月份,已经能够支持200万字的无损上下文窗口长度。这个功能对我来说比较有用的地方在于,可以快速将论文内容提炼出来,便于我评估这篇论文是否适合我深入的去研读。数据库论文都是英文写的,动辄10万字的英文论文,对于我来说需要专注的读6~7小时,可能还不能很好的理解其中的意思。而对于Kimi来说,这篇86000+字的论文不用了1分钟即可以提炼出其中的核心思想,这样我可能根据其中的核心点来进行针对性的阅读,大大提高了论文的阅读效率和学习效果。

同时,Kimi具有无损记忆功能,能够根据每轮对话的内容处理更多的上下文信息。从下图可以看到同样的问题”2023年它的营收是多少“,根据上下文的不同Kimi给出了不同的回答。
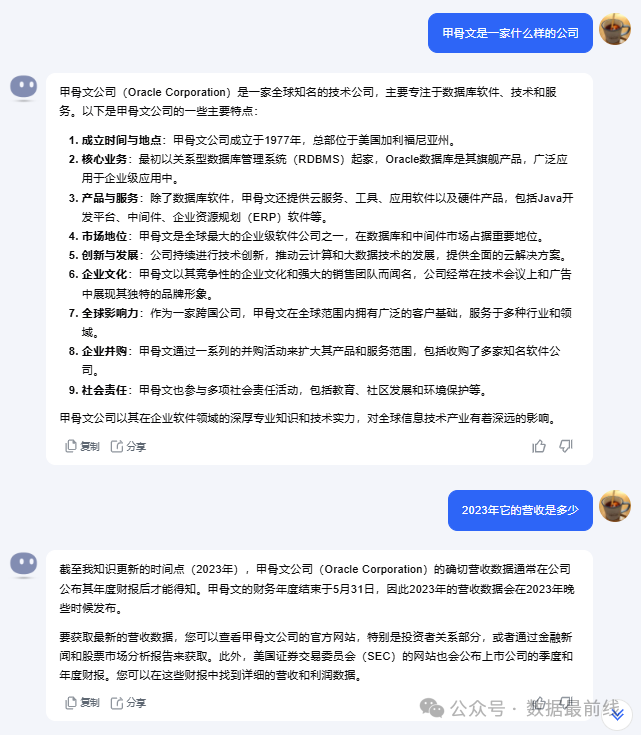
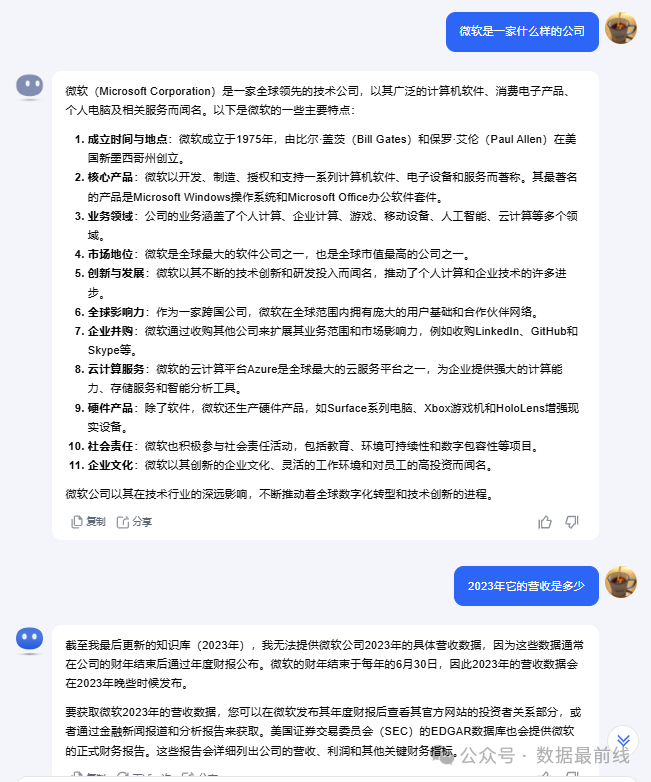
不过仔细看过上图输出结果的同学应该会发现,关于2023年的营收,Kimi给出的答案是”我最后更新的知识库(2023年) ......“。为此我又特意用通义千问查了下,发现通义给出的微软2023年营收是2119亿美元。最终我在同花顺软件中查证到,微软2023年的财报发布于2023年的7月30日,总的营收是2119亿美元。
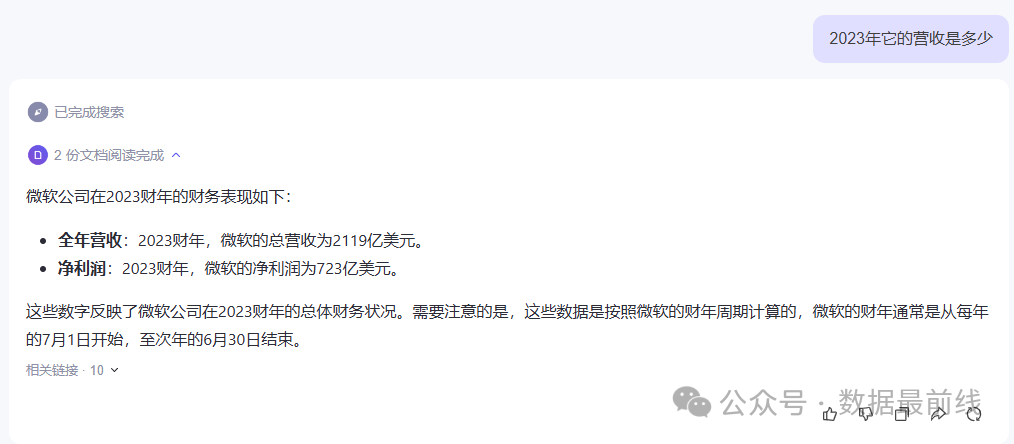
从上述的查询我们可以看到,Kimi的知识库只更新到了2023年,所以对于这类时效性比较强的话题,Kimi目前还没能给出具体的答案,而通义千问在这方面则要强的多。大模型的训练是非常烧钱的,作为创业公司的月之暗面比不上财大气粗的阿里,也在情理之中。
所以对于大模型给出的搜索结果我们也要甄别之后加以利用,不能无脑接收。尽管如此,大模型对我搜索习惯的改变仍然是颠覆性的,由于有上下文的关联,我可以在一个对话窗口中系统的回顾针对某个问题的搜索结果,工具中还会保留历史会话记录,通过历史会话也能回顾我们曾经对这个问题的搜索过程,以及大模型给出的搜索结果。
此外,Kimi的网页版还新增了搜索结果的数字脚注功能,聊天窗口中会列出10个引用的相关的网页,方便用户核实和获取更多信息。
总结
AI大模型对人们的工作和生活的改变都是颠覆性的,而且这种颠覆是全面的、彻底的。Ta不再是个大号的搜索引擎,也不是个简单的根据预定义好的句型来对话的聊天工具,而是可以被广泛使用在高效阅读、资料整理、辅助创作等一系列领域提供支持的强大助手。
不论大家的接受度如何,Ta都已经来了,如果不能回避,我们就学习Ta研究Ta利用Ta!

数据最前线
身边的数据架构师
