





TDengine 是一款开源云原生时序数据库, 专为物联网、车联网、工业互联网、金融、IT 运维等场景优化设计,具有内建的缓存、流式计算、数据订阅等系统功能,能大幅减少系统设计的复杂度,降低研发和运营成本,是一款极简的时序数据处理平台。
TDengine 在墨天轮国产数据库流行度排名14,是排名最高的时序数据库,也是所有非关系型数据库中排名最高的。在DBEngine流行度排名上,位居时序数据库全球第九,github 上 23.1k Star,可见其在国际和开源领域也有不小的影响力。
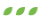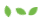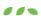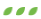
数据库架构
作为一款时序数据库,TDEngine在整个时序大数据平台中扮演数据存储的核心作用。Kafka、Telegraf等各种数据采集或消息队列将采集到的数据源源不断的写入到TDEngine,通过BI工具、Grafana等图形展示工具以及应用程序对采集到的数据进行处理和展现。
写入方面,支持SQL写入和无模式写入,可以与多种第三方工具无缝集成,仅通过配置而无需任何代码即可将数据写入TDengine;
查询方面,支持标准SQL查询,并且支持时序数据特色的函数和查询,如降采样、时间加权平均等,支持事件驱动的流式计算,这样在处理时序数据时就无需 Flink 或 Spark 这样流式计算组件;
开发方面,TDengine提供了多种语言的连接器,如C/C++、C#、Java、Go、Python等,支持REST接口;
架构上,TDengine采用云原生的分布式存算分离架构,通过RAFT协议实现数据分区分片,支持水平扩展和自动故障转移;
管理上,TDEngine提供了基于Web页面的管理控制台,对运行中的TDEngine实例进行监控和滚利,也提供了交互式的命令行程序,便于管理集群,检查系统状态以及数据查询。
数据组织
TDengine 采用传统的关系型数据库模型管理数据,用户需要先创建库,然后创建表,之后才能插入或查询数据。
作为一款时序数据库, 追求的是极致的数据写入能力,其设计理念和传统数据库有较大的差异。
TDengine采用一个数据采集点一张表的策略,对每个数据采集点单独建表(比如有一千万个智能电表,就需创建一千万张表),用来存储这个数据采集点所采集的时序数据。同时为了解决采集表数量过多带来的管理问题,TDengine为某一特定类型的数据采集点创建集合,称为超级表。超级表除需要定义采集量的表结构之外,还需要定义其标签的 Schema。
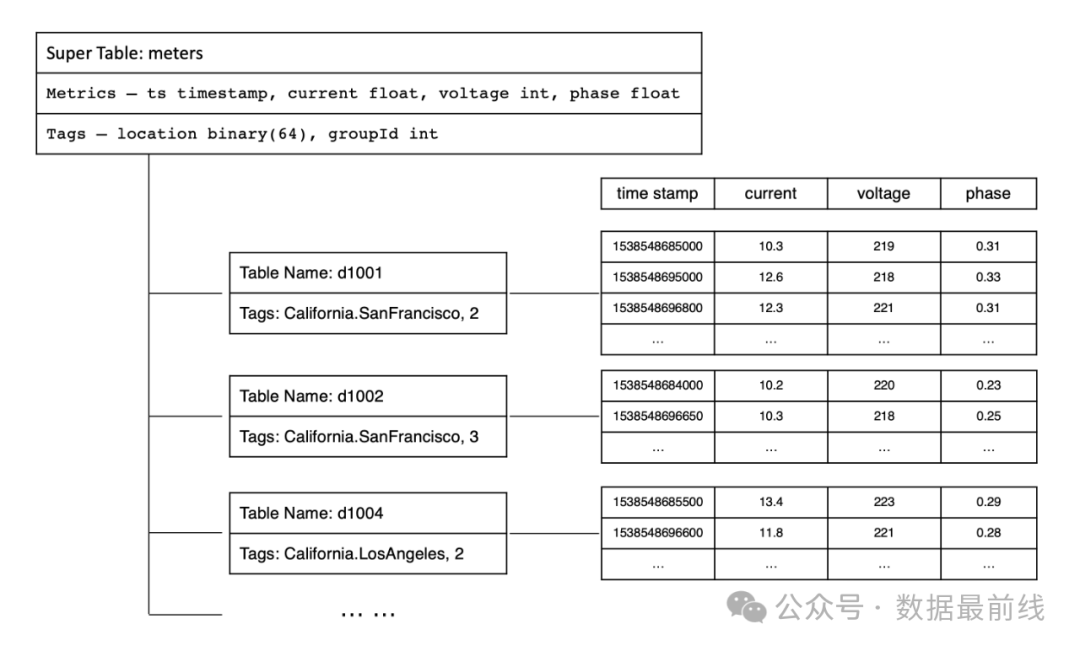
这种设计具有以下的优点:
每个数据采集表都是独立的,可以采用无锁方式写入,相互之间不存在干扰;
数据是按照时间排序的,可用追加的方式写入,提升写入速度;
数据内部采用列存储,不同的列采用不同的压缩算法,提供更好压缩比例的同时也能提升数据写入性能;
数据以块为单位连续存储,能够提升读取和查询效率。
高可用
TDengine 通过多副本的机制来提供系统的高可用性,包括 vnode 和 mnode 的高可用性。
mnode负责管理TDengine 集群,为保证 mnode 的高可用,可以配置多个 mnode 副本,数据采用RAFT协议进行同步,副本数量通常设置为1或者3个。
vnode 的副本数是与 DB 关联的,一个集群里可以有多个 DB,每个 DB 可以配置不同的副本数。一个 DB 里的数据会被切片分到多个 vnode group,vnode group 里的 vnode 分布在不同的数据节点 dnode 上,只要一个 vnode group 里超过半数的 vnode 处于工作状态,这个 vnode group 就能正常的对外服务。
写在最后
时序数据用于描述某个被测量主体在一个时间范围内的每个时间点上的测量值,常见的监控数据,股票交易数据,物联网、工业物联网等上传的实时数据等,都是时序数据的典型应用场景。
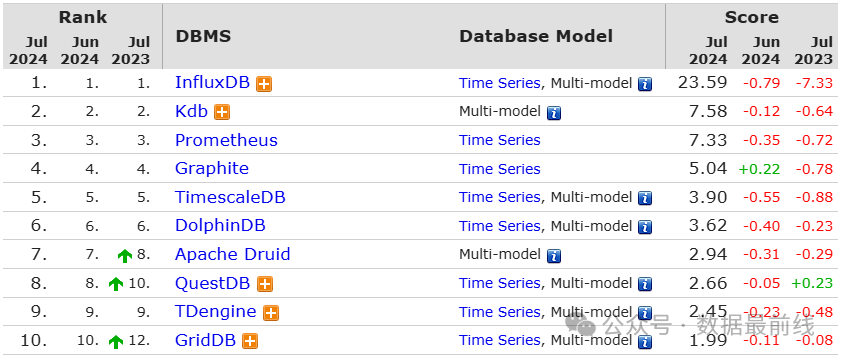
随着万物互联的时代到来,广泛的应用场景让时序数据得到了迅速发展。DBEngine自2015年开始将时序数据库纳入流行度排行,在2020年后成为流行度增加最多的数据库品类。
DBEngine当前共收录40个产品,墨天轮则收录国产时序数据库42个,数量上竟然超过了国际榜单。虽然总量比关系型还是要少不少,但考虑到其应用场景限制,国内竞争激烈程度一点也不弱于关系型!

数据最前线
关注数据生态 讲述科技故事
