





HashData是国内最早专注于云端数据仓库的初创公司,核心团队主要由来自Pivotal、Teradata、IBM、Yahoo!、Oracle和华为等公司资深的云计算、分布式数据库和大数据专家组成。凭借深厚的技术积累以及极具前瞻性的产品理念,自创立之初就获得了包括经纬创投、国科嘉和以及金沙江创投等知名投资机构的多轮融资,累积融资额超千万美元。公司的目标愿景是为金融、电信、能源、交通等重要行业头部客户解决PB级数据量、千万级数据库对象、数千高并发以及每天1亿+复杂SQL查询等最具挑战性的难题。
系统架构
数据仓库典型应用场景的特点是数据量大、查询复杂度高、并发访问高和系统可用性高。作为公司旗舰产品,HashData数据仓库融合了MPP数据库的高性能和丰富分析功能、大数据平台的扩展性和灵活性,以及云计算的弹性和敏捷性,以创新性的元数据、计算和存储三者分离的架构,提供了传统解决方案无法比拟的高并发、弹性、易用性、高可用性、高性能和扩展性。
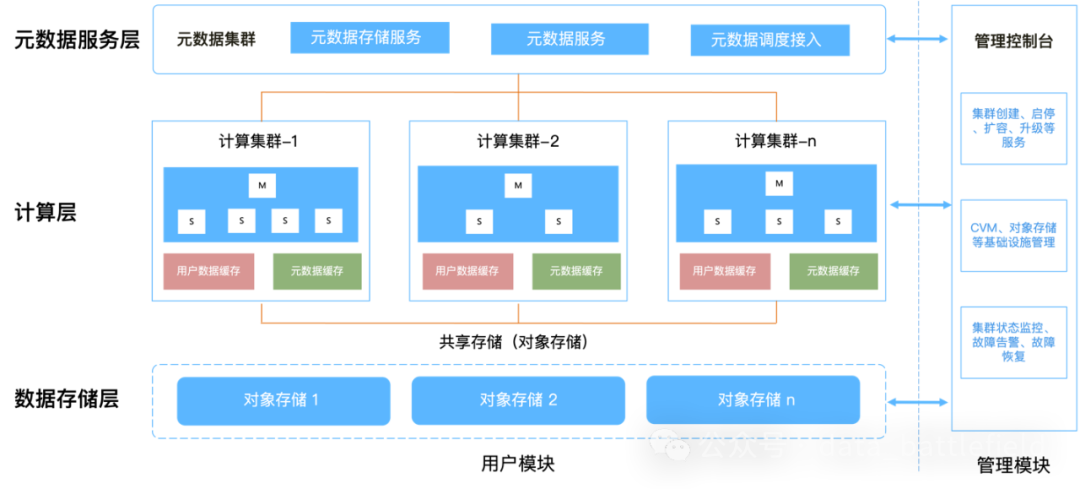
完整的HashData 云数仓分为两个大的模块:管理控制台及租户集群,其中租户集群包括:元数据服务、计算集服务和数据存储服务等模块。
管理模块
管理模块主要是管理控制平台(Cloudmanager),负责所有元数据集群、计算集群的管理,包括集群创建、启停、资源管理、监控告警等。作为云数仓的重要组件,管理控制台能够对各类云平台资源进行统一管理,整合数据库集群的监控、运维、管理等功能,建立统一的数字化管理、运维平台,实现图形化、自动化操作,达到“所见即所得”的效果,极大地降低了数据仓库集群的运维管理成本,让企业用户能够高效、便捷管理上万节点的数据仓库集群。
用户模块
用户模块主要分为三个层次:元数据服务层、计算层以及数据存储层,每层之间完全解藕。
元数据服务层
元数据服务层负责整体集群的的元数据管理和事务管理,通过全局事务性分布式KV数据库进行持久化,在KV数据库之上构建无状态服务节点,用于接受来自计算层的、对于系统元数据的访问请求,同时确保数据的高可用性。
计算资源层
计算层主要是负责具体的接收用户查询请求、查询协调、查询调优和计算工作。通过基于UDP的高速数据传输协议进行数据交换,查询在每个计算节点上面流水式并行执行,大大提升了查询效率。计算节点是纯粹的计算资源单元,按需创建删除和纵向伸缩,同时提供缓存功能的本地SSD存储。
数据存储层
数据存储层提供持久化数据服务,计算集群所有节点都可以访问数据存储层。按需付费和低单位容量的存储成本,使得基于对象存储的云端数据仓库的使用成本大幅降低,此外HashData数据仓库技术还支持独有的压缩算法,可进一步提升2~3倍的存储空间利用率。
写在最后
HashData背后的公司北京酷克数据成立于2016年,作为一家成立8年的公司,在数据库圈的知名度并不高,公开披露的资料中其客户主要分布在金融、运营商和石油等国央企。
或许是为了尽快适应数千高并发等目标愿景,HashData采用公有云服务和企业级云数据平台两条腿走路的策略,公有云服务未必能赚钱,但是能够企业带来不少的好处。
云端产品体验非常方便,相当于是一个无人值守的售前窗口。客户能够自助体验到产品功能特性,为下一步的决策提供充足的依据;
云端试错成本相对较低,新的功能特性可以先更新到云端,同时也能够将大量中小客户汇聚到云端,形成海量数据和大量访问压力,从而更好的打磨自己的产品;
云端引流的客户也可以逐步培养的到线下,金融、运营商等行业对数据保密性有很高的要求,发展这部分客户选择企业级云平台。
线下产品面临代价高昂的推广获客和后期运维成本,云上同样也面临非常大的竞争压力,阿里云ADG、华为云DWS等都是这个领域的头部玩家,HashData在竞争更加充分的云端和互联网大厂PK,胜算几何还有待进一步观察,况且当前产品线还比较单一,客户会为了HashData将自己的数仓搬迁到云上吗?数据导入的成本、外围周边系统的对接,这些HashData的资料中也没有给出解决方案。
HashData的产品线以及所面向金融和国央企客户群体,决定了其必然还是要走向线下,未来发展如何我们会持续观察。

数据最前线
身边的数据架构师
