





StarRocks是Linux基金旗下的开源项目,专注于打造世界顶级分析型数据库,以帮助企业建立“极速统一”的湖仓新范式。
作为新一代极速全场景 MPP数据库,StarRocks采用了全面向量化引擎,配备全新设计的 CBO优化器,用户可以灵活构建包括大宽表、星型模型、雪花模型在内的各类模型,能很好地支持实时数据分析,及对实时更新数据的高效查询,查询速度(尤其是多表关联查询)远超同类产品。
StarRocks 兼容 MySQL 协议,支持标准 SQL 语法,易于对接使用,全系统无外部依赖,高可用,易于运维管理。同时还兼容Tableau、Power BI、FineBI 和 Smartbi等多种主流 BI 产品,用户无需经过复杂的预处理,就可以用 StarRocks 来支持多种数据分析场景的极速分析。
系统架构
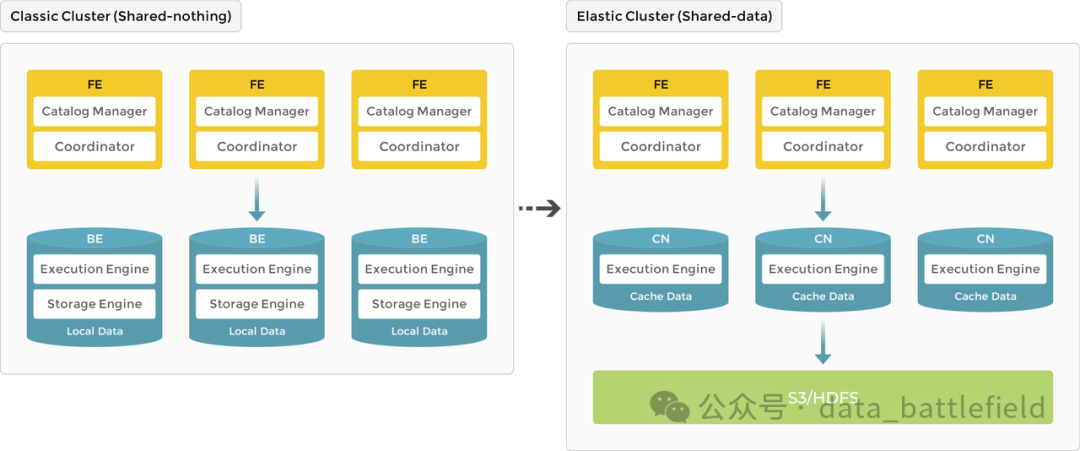
StarRocks 架构简洁,整个系统的核心只有 FE(Frontend)、BE (Backend) 或 CN (Compute Node) 两类进程。StarRocks 3.0 版本之前使用存算一体架构,BE 同时负责数据存储和计算,数据访问和分析都在本地进行;3.0 版本开始引入存算分离架构,数据存储功能从原来的 BE 中抽离,BE 节点升级为无状态的 CN 节点,支持动态增删计算节点,实现秒级的扩缩容能力。数据可持久存储在远端对象存储或 HDFS 上,CN 本地磁盘只用于缓存热数据来加速查询。
存算分离架构的远端存储,支持兼容 AWS S3 协议的对象存储系统、Azure Blob Storage以及传统数据中心部署的 HDFS。
为了提升存算分离架构的查询性能,StarRocks 构建了分级的数据缓存体系,查询时,热数据通常会直接从缓存中命中,而冷数据则需要从对象存储中读取并填充至本地缓存,以加速后续访问。通过内存、本地磁盘、远端存储,StarRocks 存算分离构建了一个多层次的数据访问体系,用户可以指定数据冷热规则以更好地满足业务需求,让热数据靠近计算,真正实现高性能计算和低成本存储。
数据管理
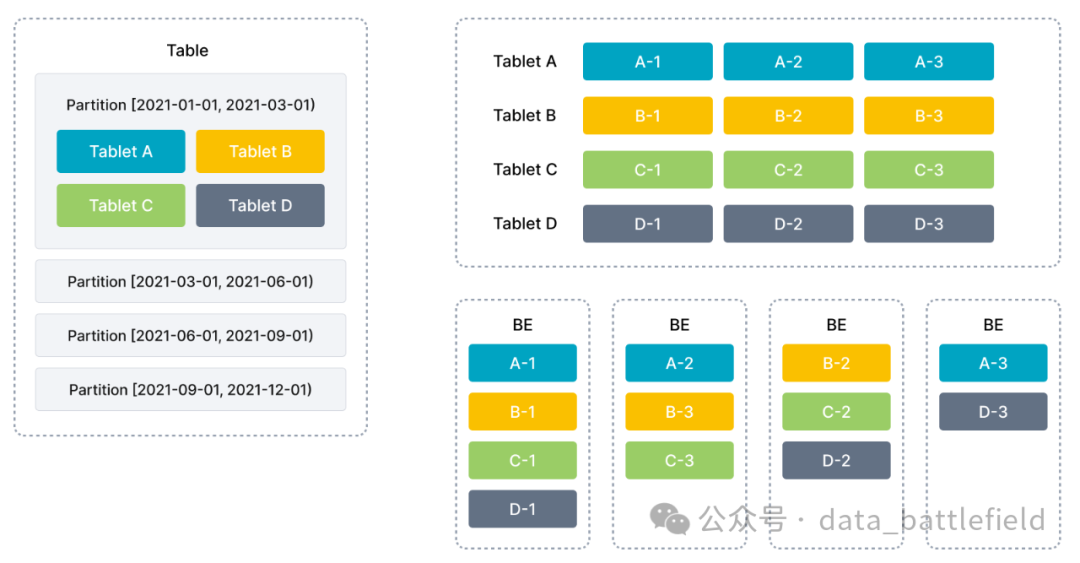
StarRocks 使用列式存储,采用分区分桶机制进行数据管理。一张表可以被划分成多个分区,一个分区内的数据可以根据一列或者多列进行分桶,将数据切分成多个 Tablet。Tablet 是 StarRocks 中最小的数据管理单元,每个 Tablet 都会以多副本 (replica) 的形式存储在不同的 BE 节点中。
产品特性
作为一款优秀的MPP数据库,相比于传统的MPP架构产品,StarRocks有其独特之处。
全面向量化执行引擎
StarRocks 的数据存储、内存中数据的组织方式,以及 SQL 算子的计算方式,都是列式实现的。全面向量化引擎按照列式的方式组织和处理数据,StarRocks 通过实现全面向量化引擎,充分发挥 CPU 的处理能力。
CBO优化器
在多表关联查询场景下,仅靠优秀的执行引擎没有办法获得最极致的执行性能。因为这类场景下,不同执行计划的复杂度可能会相差几个数量级。查询中关联表的数目越大,可能的执行计划就越多,只有优秀的查询优化器,才能选择出相对最优的查询计划,从而实现极致的多表分析性能。
StarRocks 从零设计并实现了一款全新的,基于代价的优化器 CBO。该优化器是 Cascades Like的,设计时针对 StarRocks 的全面向量化执行引擎进行了深度定制,并进行了多项优化和创新,内部实现了公共表达式复用、相关子查询重写、Lateral Join,Join Reorder,Join 分布式执行策略选择、低基数字典优化等重要功能和优化。目前,该优化器已可以完整支持 TPC-DS 99 条 SQL 语句。
可实时更新的列式存储引擎
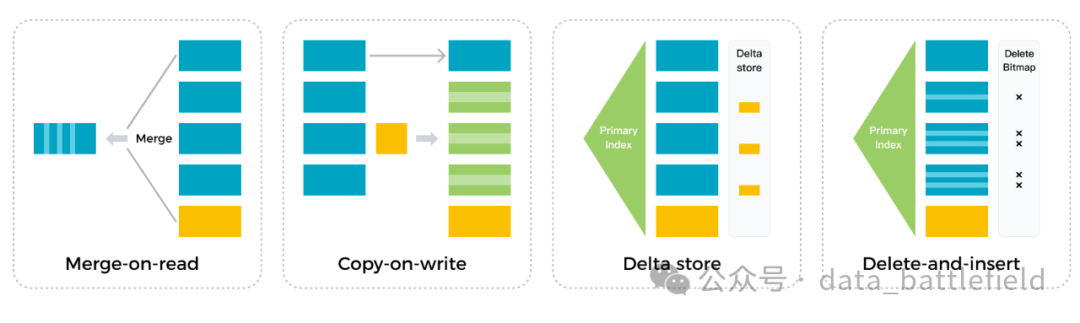
StarRocks 存储引擎不仅能够提供高效的 Partial Update 操作,也能高效处理 Upsert 类操作。使用 Delete-and-insert 的实现方式,通过主键索引快速过滤数据,避免读取时的 Sort 和 Merge 操作,同时还可以充分利用其他二级索引,在大量更新的场景下,仍然可以保证查询的极速性能。
智能的物化视图
StarRocks 支持用户使用物化视图(materialized view)进行查询加速和数仓分层。StarRocks 的物化视图可以自动根据原始表更新数据,只要原始表数据发生变更,物化视图的更新也同步完成,不需要额外的维护操作就可以保证物化视图能够维持与原表一致。
数据湖分析
StarRocks不仅能高效的分析本地存储的数据,也可以作为计算引擎直接分析数据湖中的数据。用户可以通过 StarRocks 提供的 External Catalog,轻松查询存储在 Apache Hive、Apache Iceberg、Apache Hudi、Delta Lake 等数据湖上的数据,无需进行数据迁移。
写在最后
StarRocks最初的名称是DorisDB,不知道大家看到这个名字是否有些似曾相识,没错就是你知道的Apache Doris。2020 年 2 月,百度 Doris 团队的个别同学离职创业,基于 Apache Doris 之前的版本做了自己的商业化闭源产品 DorisDB ,这就是 StarRocks 的前身。作为 Fork 自 Apache Doris 的项目,StarRocks没有再向社区贡献代码,甚至还修改了开源协议,使得上游引入不了任何StarRocks代码。
诚然,StarRocks的做法并没有违反相关的法律,Apache License也约束不了这样的行为,但多少有些违背开源精神。如果大家都只从开源汲取而不贡献,开源软件也不可能发展成今天如此欣欣向荣的景象。
我们希望能从开源软件中诞生出更多的优秀商业产品,更希望能做好开源的回馈,“吃水不忘挖井人”,也只有这样才能让开源软件体系更加繁荣,形成良性循环。

数据最前线
身边的数据架构师
