




PolarDB 是阿里云推出的云原生数据库产品,提供MySQL和PostgreSQL两种引擎,支持单机、主备以及分布式的架构PolarDB-X。由于其良好的MySQL兼容性,显著优于MySQL单机数据库的性能处理能力,较低的使用成本,受到业界的广泛关注和众多用户的好评。
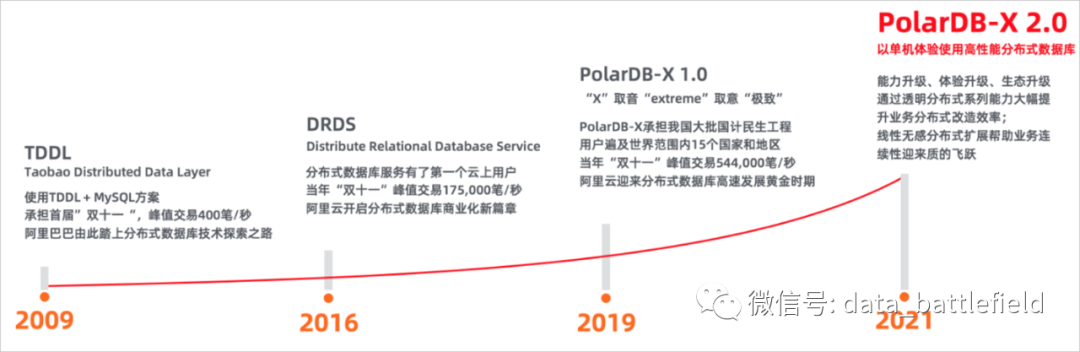
在国内,阿里是比较早开始探索分布式数据库的厂商之一,PolarDB-X的发展也在一定程度上代表国内分布式数据库技术的发展,我们从PolarDB-X的发展轨迹来探究国产分布式的进化历程。
DRDS阶段
随着TDDL的不断成熟,阿里云发布了第二代产品DRDS (Distributed Relational
Database Service),其本质上仍然是一个中间件,除了将后端数据库聚合成一个逻辑库,提供数据垂直拆分、水平拆分、读写分离等功能外,还具备功能比较齐全的分布式SQL查询、优化、执行引擎,提供分布式事务管理方案,等等。
分布式中间件虽然在一定程度上解决了扩展性的问题,但始终没有解决业务的耦合性问题,分库分表之前必须要规划好分区键选择。要求查询SQL带上具有业务特征的分区键,从高吞吐、高并发的角度是非常合理的事情,但对于开发人员来说成本太高。而且不同的业务类型需要用到不同的查询条件,一旦分区键规划不合理,后期的改造成本也会非常高。
PolarDB-X
鉴于分库分表中间件对于业务的侵入性,PolarDB提出了“透明分布式”的概念,并在2019年发布的PolarDB-X产品中,通过支持分布式事务、全局二级索引、异步DDL等功能特性来逐步实现这一目标。
与集中式数据库索引中的数据均来自同一个数据节点不同,分布式系统包含多个数据节点,全局二级索引上记录了表数据在所有数据节点的分布情况,因此应用查询能够通过全局索引获取到相应的数据。从实现目标上看,和分库分表中间件并没有太大的差别,但是有一个非常关键的差别。分库分表中间件是实现设定好规则,让应用来被动遵守的;而全局索引和数据的更新是同步的,数据的分布变化会实时反应到全局索引中。所以在实现了全局索引的分布式数据库中,不再需要刻意强调分区键,这是从中间件进化到分布式数据库的一个重要里程碑。
小结
通过PolarDB的演进可以看到,国产分布式数据库技术走过了一条从分布式插件到分布式中间件,再到分布式数据库的发展路线,每一次蜕变都基于上一代的积累,变得更加优秀更加实用,更能够让用户充分享受到分布式带来的优点,又尽量减少因为分布式的引入而带来的额外的工作。
传统集中式数据库经过30多年的发展,各个场景的应用已经变得非常成熟,分布式作为近些年才开始流行的架构,使用上对底层表设计和应用开发还有着诸多的要求。从分布式插件到中间件再到全新的分布式引擎, 分布式架构的易用性得到了显著的提升,未来“透明分布式”仍然是分布式数据库重要的发展方向。
写在最后
目前国内有200多种不同的国产数据库,粗看起来都差不多,或兼容MySQL、Oracle、PG等主流的国外数据库,或采用开源的数据库作为自己的存储引擎。但仔细研究就会发现存在很大的差异,这些差异既体现在系统架构、存储引擎、分布式协议等技术层面,也体现在生态建设、市场策略等非技术层面。透过这些不同,能够感受到这家公司的企业文化,甚至是这支开发团队的精神面貌。
PolarDB团队将自己的数据库产品开源,并提供了详尽的产品文档和使用介绍,更难能可贵的是,他们将产品发展路线和设计思路也分享出来,让使用者不仅能够学习到产品的功能特性,更能够深入的了解为什么要这样做,这些“血和泪”的经验教训能让人更加收益良多。透过这些字里行间,你能够感受到这是一支充满激情的团队,他们把数据库作为一件艺术品来精心打磨。我们有理由相信未来PolarDB将会更加优秀,同时也希望能够涌现更多更加优秀的国产数据库开发团队和产品!
