




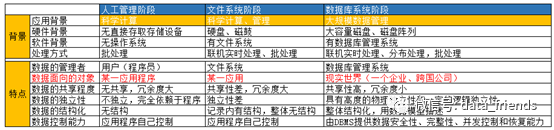
数据管理阶段
信息系统产生了海量的数据,为了提升数据管理效率,数据管理技术也在持续发展,历经了以下的几个阶段:
人工管理阶段
20世纪50年代之前,这个阶段没有直接的存储设备,数据的计算和保存是分开的,数据的存取一一对应,无共享,各自单独数据定义、处理。
文件管理阶段
20世纪50年代末-60年代中,文件系统提供了一些存取方法,如随机存取方法、顺序存取方法、hash存取方法等,但本质上应用程序和文件还是一一对应,某一个应用程序要应用某个文件,是由程序员在程序中定义。
数据库管理阶段
20世纪60年代末-现在,由数据管理系统统一管理数据,数据通过某个数据模型模型化数据化,应用程序通过数据库管理系统存取数据库里的特定数据,数据之间是共享的,如应用程序1可以存取数据库第一个方块的数据,应用程序2可以存取1,2方块的数据。
数据库发展阶段
层次数据库
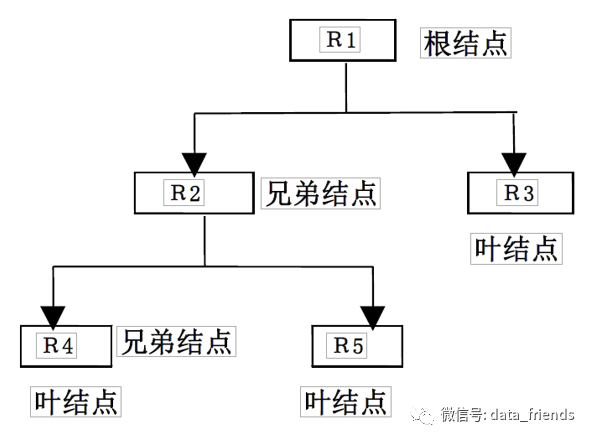
层次数据模型是数据库系统最早使用的一种模型,它用“树”结构表示实体集之间的关联,其中实体集(用矩形框表示) 为结点,而树中各结点之间的连线表示它们之间的关联。
层次数据模型中的数据需要满足以下两个要求:
1. 有且只有一个结点没有双亲结点,这个结点称为根结点
2. 根以外的其它结点有且只有一个双亲结点
层次模型数据库系统是最早研制成功的数据库系统,典型代表是IBM公司的IMS(Information Management System)数据库管理系统。
IMS的全称是Information Management System,于1969年投入运行,最早的版本有IMS/360-1和IMS/360-2。较近的版本有IMS/VSDL/1,它是在操作系统DOS/VS(DiskOperation System/Virtual Storage)支持下运行。
层次数据库虽然在性能上要优于关系型数据库,但对插入和删除操作的限制比较多,应用程序的编写比较复杂,尤其是现实中存在大量的多对多的联系,层次数据模型难以很好的表示这种关系。
因此在随后又出现了网状数据模型和基于该模型构建出来的网状数据库。
网状数据库
1959年美国国防部美国国防部组织召开一个有政府机关、企业、计算机厂商参加的会议,会议上大家认为有必要设计一种数据处理专用的语言。这就是著名的数据系统语言会议CODASYL(Conference on Data Systems Languages)。
1969年美国的CODASYL组织提出了一份“DBTG报告”,以后根据DBTG报告实现的系统一般称为DBTG系统。现有的网状数据库系统大都是采用DBTG方案。
DBTG系统是典型的三级结构体系:子模式、模式、存储模式。相应的数据定义语言分别称为子模式定义语言SSDDL,模式定义语言SDDL,设备介质控制语言DMCL,另外还有数据操纵语言DML。
网状数据模型用有向图表示实体和实体之间的联系,其数据集合需要满足下面两个条件的基本层次联系:
1. 允许一个以上的结点无双亲;
2. 一个结点可以有多于一个的双亲。
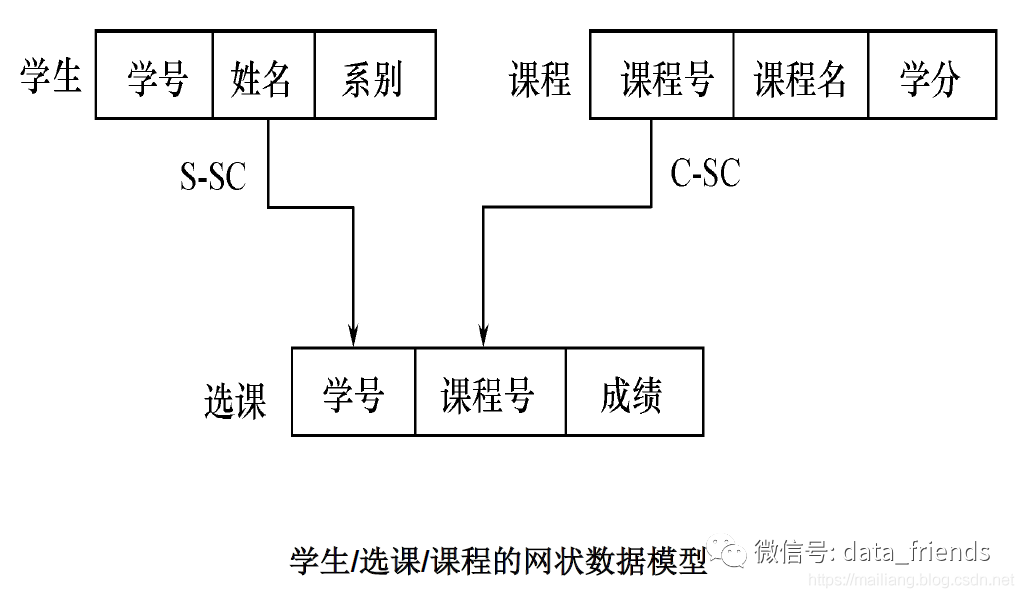
网状数据模型可以看做是放松层次数据模型的约束性的一种扩展。网状数据模型中所有的节点允许脱离父节点而存在,也就是说说在整个模型中允许存在两个或多个没有根节点的节点,同时也允许一个节点存在一个或者多个的父节点,成为一种网状的有向图。因此节点之间的对应关系不再是1:n,而是一种m:n的关系,从而克服了层次状数据模型的缺点。
DBTG系统亦称为CODASYL系统,相应的数据库产品有:Cullinet Software公司的IDMS、Univac公司的DMS1100、Honeywell公司的IDS/2、HP公司的IMAGE。
虽然网状数据模型可以很方便的表示现实世界中的复杂关系,但是其结构复杂,插入和删除操作成本非常高,尤其是随着应用环境的扩展,数据结构越来越复杂,整个数据库的维护成本非常高。
关系型数据库
关系型数据库的发展,大致可分为理论奠基、SQL标准、商用成型、多家发展等几个阶段,在每个阶段都有对应的重要人物与贡献。
1970年6月,数学家E.F.Codd发表了数学论文《用于大型共享数据库的关系数据模型》,提出关系和关系运算的概念,奠定了关系型数据库的理论模型;
1973年,Codd的同事Don Chamberlin将Codd的论文和关系运算,转换成为比较容易理解和使用的SQL语言,并且在后面成为所有关系型数据库的标准;
1978年,基于数据理论和SQL基础,Larry Elision和他的同事看到商机,开发出第一个商用大型关系型数据库Oracle;
IBM也在1982年开发出了DB2数据库,虽然IBM早在1972年就启动了关系型数据库研发项目——SystemR,但最先的产品产品却是Oracle在1978年发布的Oracle 1,开启了两个巨头在随后的数十年时间里数据库产品领域的不断竞争序幕。
随后的20世纪80年代,大量的关系型数据库涌现,如微软SQL Server、Sybase、Informix,以及现在流行的开源数据库PostgresSQL。而这些主流的关系型数据库产品都和MichaelStonebraker有关,关于他的传奇故事,我们以后再细说。
关系数据模型,以二维表格为基础,通过实体和关系来表示现实世界。其理论一经面世便得到了Don Chamberlin等人的热烈追捧,并开发的后来的SQL语言,也进一步推动了关系型数据库的发展。
非关系型数据库
为适应水平扩展性和处理超大量的数据环境,近几年发展非常迅速的发展,衍生类型非常多。
NoSQL,泛指非关系型的数据库。随着互联网行业的兴起,传统的关系数据库在处理这类超大规模和高并发的业务类型时显得力不从心,出现了很多难以克服的问题,而非关系型的数据库则由于其数据之间无关系易于扩展的特点得到了非常迅速的发展。
区别于关系数据库,它们不保证关系数据的ACID特性。同时又由于非关系型数据库中的数据之间没有关系,使得扩展非常容易,这对于互联网行业海量数据的处理场景非常有优势。
非关系型数据库种类繁多,典型的数据库分类有:
键值(Key-Value)存储数据库,如Redis、AmazonDynamoDB;列存储数据库,如Cassandra、HBase;文档型数据库,如Mongodb、CouchDB;图形(Graph)数据库,如Neo4j。
非关系型数据库优点突出,同样缺点也很明显。通常来说,非关系型数据库在以下的这几种情况下比较适用:
数据模型比较简单;
需要灵活性更强的IT系统;
对数据库性能要求较高;
不需要高度的数据一致性;
对于给定key,比较容易映射复杂值的环境。
因此在选择非关系型数据库时需要明确所选择的产品能够满足业务的需求,选择适合自己的产品才是王道。
