




《MySQL中的clustered索引为什么特别》描述了聚集索引,本文描述secondary index,两者之间关系很大!
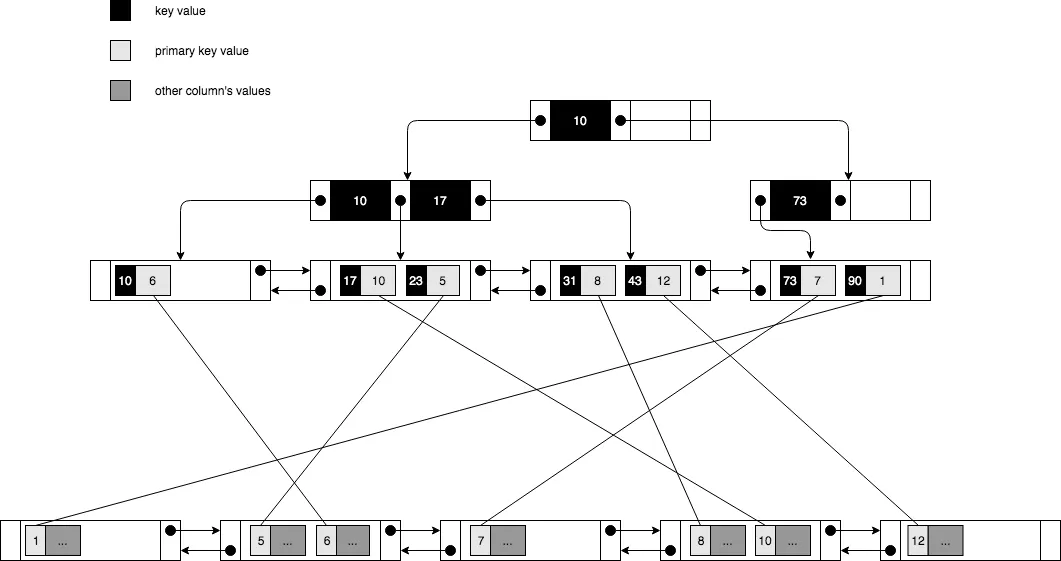
secondary index也采用B-Tree,区别就是叶子节点只存key值和clustered key的值,secondary索引结构图:
secondary inedex和聚集索引关系图:
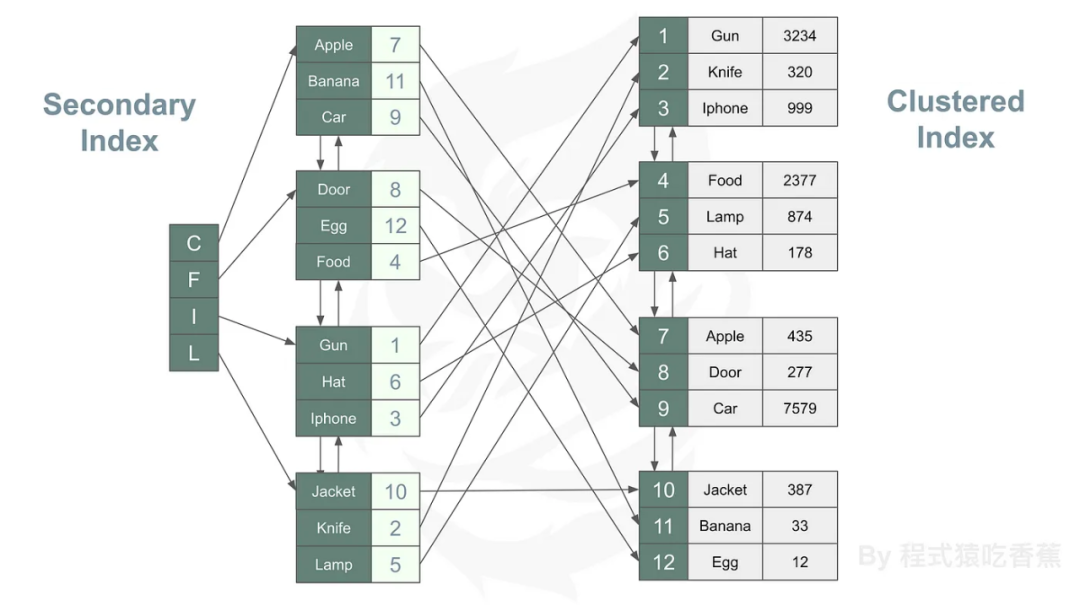
主要核心点:
secondary index查询后还要根据clustered key去拿最后的数据 secondary index range query的时候,拿数据的时候因为clustered key不确定(page不确定,且要最终排序),所以性能没有clustered index好 secondary index会包含clustered key,如果clustered key值比较大,第二索引也会比较大 如果sql语句被secondary index覆盖,就不用去拿实际的数据,直接从叶子节点获取就行,性能比较好
如何判断是否是使用覆盖索引?explain 命令:
如果extra显示using index condition,表示还是要取row data 如果extra显示using index,表示使用了覆盖索引
文章转载自虞大胆的叽叽喳喳,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
