




去年写了两篇关于presto的文章,得到公众号的推荐,大家还挺喜欢的,今天换个角度介绍下presto,能让大家快速了解它是个什么软件。
它是什么?它擅长做什么?它不适合做什么?它由什么组件组成,它的安全性怎么样?
这篇文章就会告诉你,其实大部分软件,其设计理念还是很类似的,分布式、组件化、标准化!
如果你的公司有大量的分析任务,又不想构建大数据集群,那presto真的很适合!
presto是一个开源的分布式SQL引擎,它能给各种数据源提供统一的查询接口,脑洞开一下,是不是说什么数据都能查?
它通过大量的内存计算减少I/O压力,一般和Hadoop服务部署在一起,一个吃内存,一个吃硬盘。
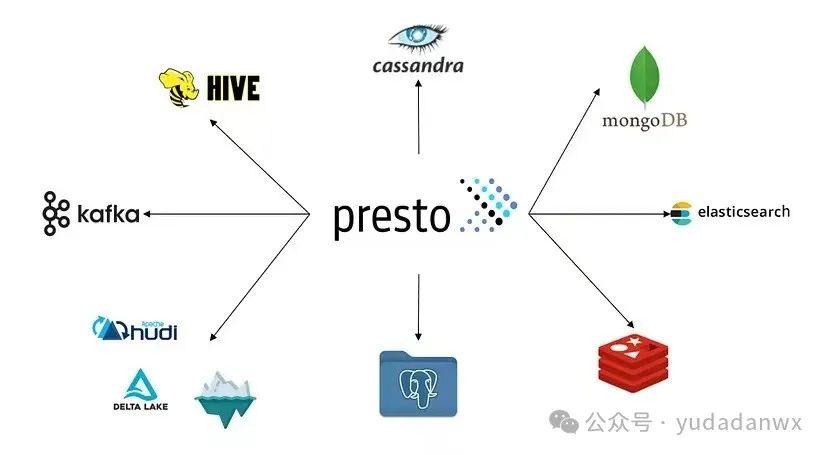
它是一个分布式计算服务,可以并行读取数据并执行,分类了存储和计算,两者可以独立扩展。
1:特性
能够查询不同的源数据,比如mysql、hive、hdfs、kafka等等 统一的SQL查询接口,比如查询kafka数据,也能使用SQL presto的后端是可扩展的,通过插件可以支持不同的数据源 设计理念就是查询即数据,不用依赖任何的数据源,也不用将数据导入到presto 动态生成加速执SQL执行的字节码,能够有效利用硬件资源 presto属于列式查询,能够提高查询速度 对ORC和Parquet做了查询优化
2:对于presto可能的误解
它和Hadoop、YARN、SPARK这些大数据组件没有任何关系 它也不是数据库 它不擅长OLTP处理
3:什么地方可以用上pressto
交互式查询 数据分析或者Dashboards 跨数据源查询 数据湖
4:presto有哪些组件组成
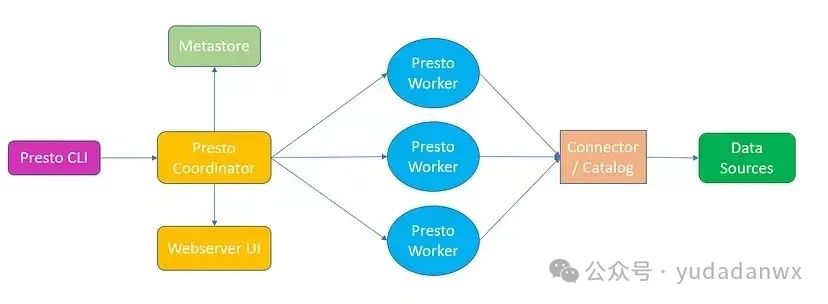
(1)客户端
CLI JDBC接口 PyHive(可以翻翻我以前的文章)
(2)协调者(Coordinators)
解析、分析、计划、调度查询人物 监控Workers运行状况 提供Webserver/UI
(3)Discover服务
worker启动的时候能够将它们自己进行注册,从而Coordinators能够发现并调度它们
(4)Worker
负责并行执行具体的SQL任务 向Coordinators注册自己(见上面的Discover服务)
(5)Connectors
后端数据源或存储的驱动器 Metadata API(供Coordinators中的解析器和分析器使用) Data Location API(供Coordinators中的调度器使用) Data Stream API(供Worker使用) Data Stats API(供Worker使用) 各种java写的插件
(6)Metastore
hive
(7)WebUI
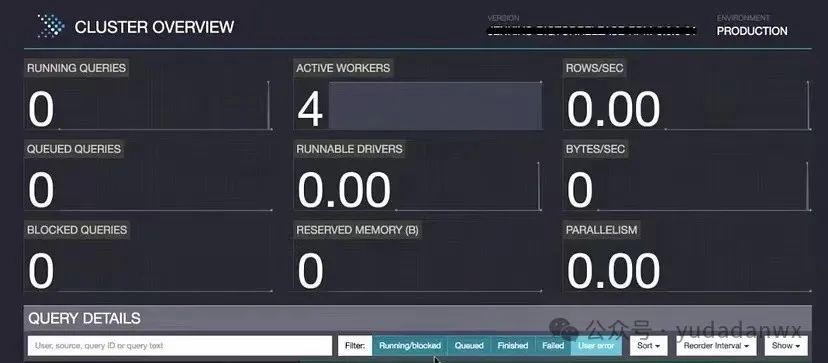
展示集群状态和查询细节 展示目前执行的计划、性能情况等等
5:安全性
presto支持各种验证(Authentication)方式(Kerberos,LDAP) connectior支持的验证方式取决于具体的实现 presto支持基于角色的授权(RBAC) presto连接数据源,使用service user的身份进行验证(比如查询hive要给当前用户授权) Rnager和HTTPS的支持
6:一些限制
查询失败是没有容错的,需要重新发起查询 对内存要求很高,比如聚合、joins、窗口函数等操作 并不支持完全的SQL语言 Coordinators是单点,不过最新版有了资源管理器的概念,可以翻我以前的文章
文章转载自虞大胆的叽叽喳喳,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
