




在当今数据驱动的时代,数据管道作为现代系统中高效管理和处理数据的基础组件,扮演着至关重要的角色。数据管道通常包括五个阶段:收集、摄入、存储、计算和消费,每个阶段都有其特定的组件和功能,确保数据从获取到最终使用的整个过程顺利进行。
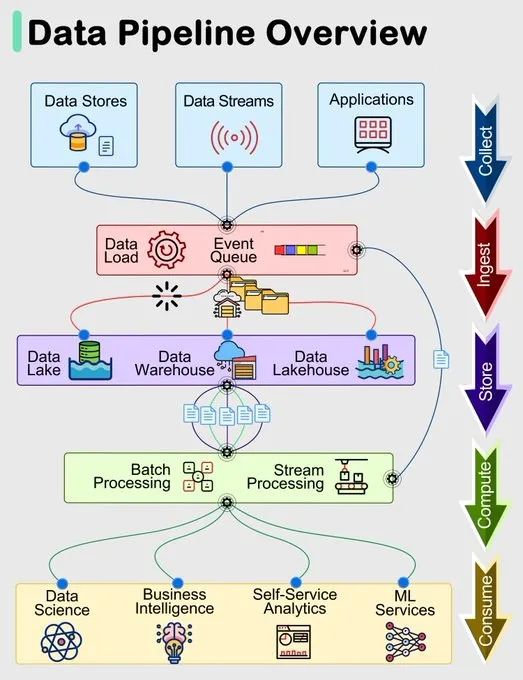
1:采集
数据收集是数据管道的第一个阶段,数据从多个来源获取,这些来源包括数据存储(数据库、文件系统)、数据流(传感器、日志)和应用程序(APP、商业系统)。
2:摄入
在摄入阶段,数据被加载到系统中并组织到事件队列中,这一阶段的组件包括Apache Kafka、Sqoop、Flume等,这些工具帮助管理和处理大量实时数据流,确保数据以有序、高效的方式进入下一个阶段。
这一阶段涉及到的关键操作是保证数据的实时性与可靠性,尤其在大规模数据场景下,队列系统需要具备高并发和低延迟的特性。
3:存储
数据存储阶段涉及将组织好的数据存储在数据仓库、数据湖和数据湖仓中,比如数据湖可以使用Hadoop HDFS存储原始数据,数据仓库可以使用Apache Hive存储结构化数据,而数据湖仓可以使用Delta Lake。
常见的组件包括HDFS、Hive、Delta Lake、Snowflake、Amazon S3。
特别说明Hive虽然是查询工具,但其本质上也具有数据schema,可以认为是HDFS存储。
4:计算
数据处理不仅仅是简单的查询操作,更多时候还包括清洗、聚合、格式转换等操作,这一阶段主要对数据进行处理,分为批处理和流处理。
批处理如MapReduce、Spark有用于处理大规模的离线数据,流处理如Flink、Spark用于实时处理数据流,前者处理的数据可以放到HDFS(文件系统)、Hive(数据仓库)、MySQL(关系数据库)、Cassandra(NoSQL数据库),后者处理的数据可以放到实时数据存储系统(Kafka、Cassandra)、消息队列(Kafka)、文件系统(HDFS)、仪表盘数据(Grafana)等。
流处理还能直接在摄取阶段进行,从而提高效率;计算阶段完成后也包括存储阶段,所以对于数据管道来说,整个流程也是比较灵活的。
5:消费
处理完成后的数据可以被用于多种场景,包括数据科学(比如机器学习),业务分析(BI工具进行报表分析)等等,工具包括Tableau、Power BI、Jupyter Notebook、TensorFlow等。
数据管道的高效运行不仅依赖于每个阶段的组件和工具,还需要整体的协调和优化。通过标准化数据收集、高效的消化机制、适当的存储解决方案、灵活的计算框架和多样化的数据消费方式,可以确保数据在整个过程中保持一致性和高质量。
