




在做业务架构的过程中,你是否遇到过类似的痛点?
(1)数据量太大,容量复杂性上移到业务层;
(2)并发量太大,性能复杂性上移到业务层;
(3)前台与后台存储异构,满足不同查询需求;
(4)线上与线下存储异构,满足大数据需求;
(5)存储系统迁移成本高,不敢轻易做重构;
(6)...
职业生涯十五年,基本都在使用MySQL做线上业务的存储。最近这几年,遇到的问题慢慢多起来,严重影响了研发效率。TiDB近年甚火,于是最近做了一些调研,与大家分享。
如一贯风格,更多的聊:TiDB究竟解决什么问题,以及为什么这么设计,体现什么架构思想。
问题的引出,MySQL体系结构存在什么问题?
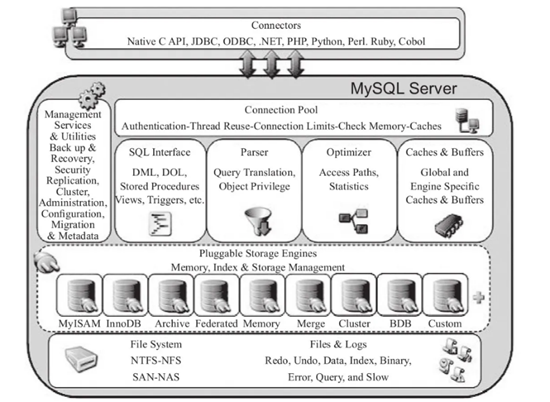
上面这幅MySQL体系结构图,相信很多人都见过:
(1)上游:MySQL客户端;
(2)下游:MySQL服务端,又包含连接池,语法分析,语义分析,查询优化,缓冲池,存储引擎,物理存储,管理功能… 等诸多模块;
画外音:太复杂了,字都看不清了。
对MySQL体系结构做了一个简化:
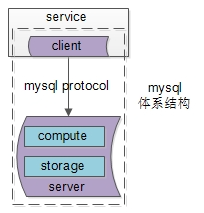
如上图所示:
(1)上游:MySQL客户端;
(2)中间:通过MySQL协议通讯;
(3)下游:MySQL服务端;
画外音:对不起,忍一下我画的丑图。
核心的服务端,又主要分为两层:
一层,计算层;
一层,存储层;
MySQL如此这般,存在什么天然的问题?
【1】计算与存储天然耦合。
计算层和存储层,既然都在一个MySQL进程里,所有的CPU资源,内存资源都是共享的,势必存在资源争抢的耦合。
除了天生的不足,在数据量大,并发量大的典型互联网业务场景里,对于MySQL的使用,还有哪些痛点呢?
我们都知道,当读写量增加的时候,通常会对MySQL做主从分组集群:
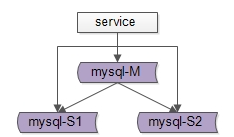
如上图所示:主从同步,读写分离,通过线性增加从库来线性扩展系统的读性能。
画外音:大部分业务,读容易成为主要矛盾。
我们也知道,当存储容量增加的时候,通常会对MySQL做水平切分集群:
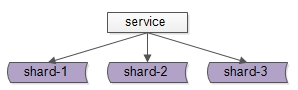
如上图所示:用一个键值进行数据分片,以实现更大的存储容量。
所以,实际上线上的MySQL集群是这样的:
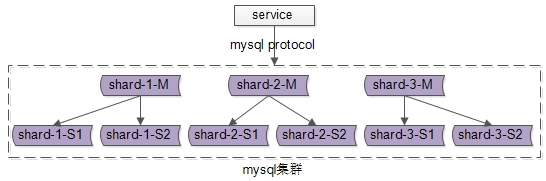
(1)既有水平切分,多个分片;
(2)又有主从分组,每个分片有一个主从集群;
而分片和分组,都是调用方微服务需要关注的,这就引出了下一个痛点:
【2】调用方需要关注存储细节,底层存储的复杂性转移到了上层应用。
另外,除了在线应用,绝大部分互联网公司都有各类大数据处理的需求:
(1)离线分析:例如,经营日报;
(2)在线分析:例如,分析师取数;
(3)实时处理:例如,实时报表;
为了满足这类需求,又需要将MySQL中的数据同步到各类大数据体系的集群中:
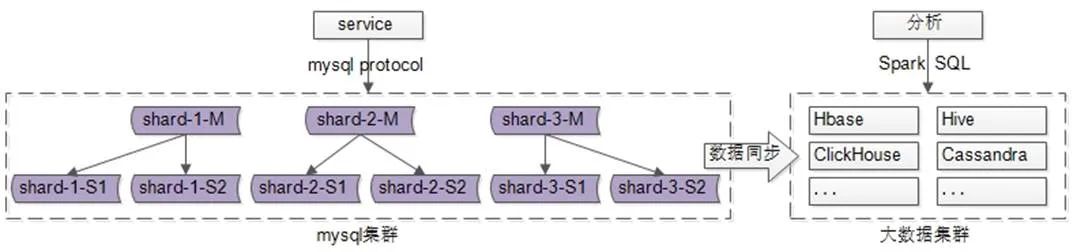
用一系列大数据的技术体系,去解决各类大数据处理的需求。
这就引出了另一个痛点:
【3】技术侧需要关注数据同步,数据一致性,大数据集群的复杂性。
当然,很多技术管理者也会调研各类替代产品,以解决上述1-3的问题,例如NoSQL的代表之一MongoDB,无奈【4】升级迁移需要大量的系统改造,综合评估之后,往往不得不放弃迁移方案,继续忍受MySQL带来的各种问题。
历史的痛点,往往是创新的机会。
TiDB,它来了!
TiDB是如何设计,以解决:
【1】计算与存储耦合;
【2】存储底层的复杂性转移;
【3】大数据体系复杂性转移;
【4】系统迁移成本高;
等问题的呢?
首先,TiDB在诞生之初,就确定了:
(1)复用MySQL协议;
(2)计算与存储分离;
的设计大方向。
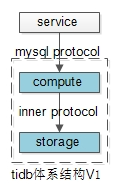
如上图所示:
(1)上游:不需要做任何改动,可以使用MySQL的各类driver,访问TiDB;
(2)中间:通过MySQL协议通讯;
(3)下游:将计算层与存储层拆分到两个进程里,解除资源争抢的耦合,而这两层的通讯则使用内部协议,对调用方透明;
如此一来,难题【1】和【4】就得到了解决。
如何解决读写量扩展,存储量扩展等“底层复杂性转移”等问题呢?
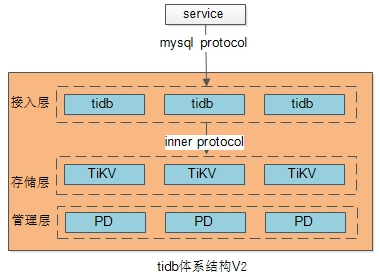
对于计算层,实现连接池,语法分析,语义分析,查询优化等模块,做到无状态,并通过集群的方式扩展,这就是TiDB体系结构中的“计算引擎tidb-server”集群。对于调用方,接入层TiDB集群就是入口,其背后的复杂性对上游不可见。上图中,简记为【接入层(计算层)】。
画外音:微服务架构中,站点应用和微服务层也必须无状态化,以实现轻易的集群扩展,也是一个道理。
对于存储层,实现一致性算法,分布式事务,MVCC并发控制,算子下推等模块,实现原子KV存储,也能通过集群的方式自动扩展,这就是TiDB体系结构中的“存储引擎TiKV-server” 集群。上图中,简记为【存储层】。
画外音:这与GFS中的chunk-server很像,有了它,不再需要手动水平切分扩容了。
除此之外,需要一个拥有全局视野,实现元数据存储,ID分配(key-id,事务ID),时间戳生成,心跳检测,集群信息收集等模块的master,这就是TiDB体系结构中的“PD-server”集群。上图中,简记为【管理层】。
画外音:这与GFS中的master-server很像。
如此一来,难题【2】存储底层读写容量与存储容量的复杂性转移问题,也得到了解决。
大数据体系的复杂性,TiDB也将其屏蔽在了内部:
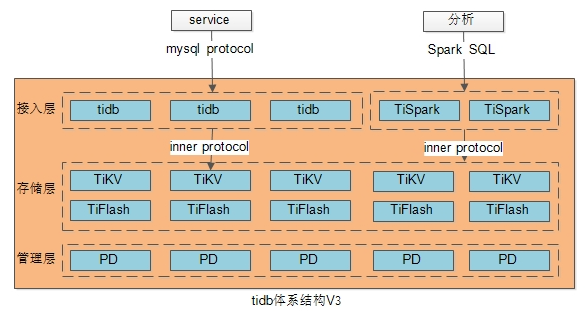
(1)扩展接入层,让大数据有独立的接入,如上图中的TiSpark;
(2)扩展存储层,匹配以适合大数据的存储,如上图中的TiFlash;
画外音:TiKV和TiFlash分别独立存储,且进行异步数据同步,彼此解耦。
(3)扩展管理层,同时管理大数据的部分;
如此一来,难题【3】大数据数据同步,数据一致性,大数据集群的复杂性的问题,也得到了解决。
TiDB的架构,无处不体现着这样的设计原则:使用者简单易用,复杂麻烦的地方,都屏蔽到TiDB的内部。
(版权归原作者所有,侵删)
