




 关注「Raymond运维」公众号,并设为「星标」,第一时间获取更多运维等文章,不再错过精彩内容。
关注「Raymond运维」公众号,并设为「星标」,第一时间获取更多运维等文章,不再错过精彩内容。
一、 背景
在非operator配置的普罗中我们监控k8s集群都是通过配置configmap进行服务发现和指标拉取。切换到prometheus-operator难免会有些使用问题。不少用户已经习惯底层配置自动发现的方式。当过渡到servicemonitor或者podmonitor或多或少不习惯。所以下面就为大家介绍一下Prometheus-Operator,以及servicemonitor的使用方法
二、 Prometheus-Operator介绍
Prometheus Operator 为 Kubernetes 提供了对 Prometheus 相关监控组件的本地部署和管理方案,该项目的目的是为了简化和自动化基于 Prometheus 的监控栈配置,主要包括以下几个功能:
kubernetes自定义资源:使用kubernetes CRD 来部署和管理Prometheus,Alertmanager和相关组件
简化的部署配置:直接通过kubernetes资源清单配置Prometheus,比如版本,持久化,副本,保留策略等等配置
Prometheus监控目标配置:基于熟知的kubernetes标签查询自动生成监控目标配置,无需学习prometheus特地的配置
2.1 架构
下图是 Prometheus-Operator 官方提供的架构图,各组件以不同的方式运行在 Kubernetes 集群中,其中 Operator 是最核心的部分,作为一个控制器,它会去创建 Prometheus、ServiceMonitor、AlertManager以及 PrometheusRule 等 CRD 资源对象,然后会一直 Watch 并维持这些资源对象的状态。
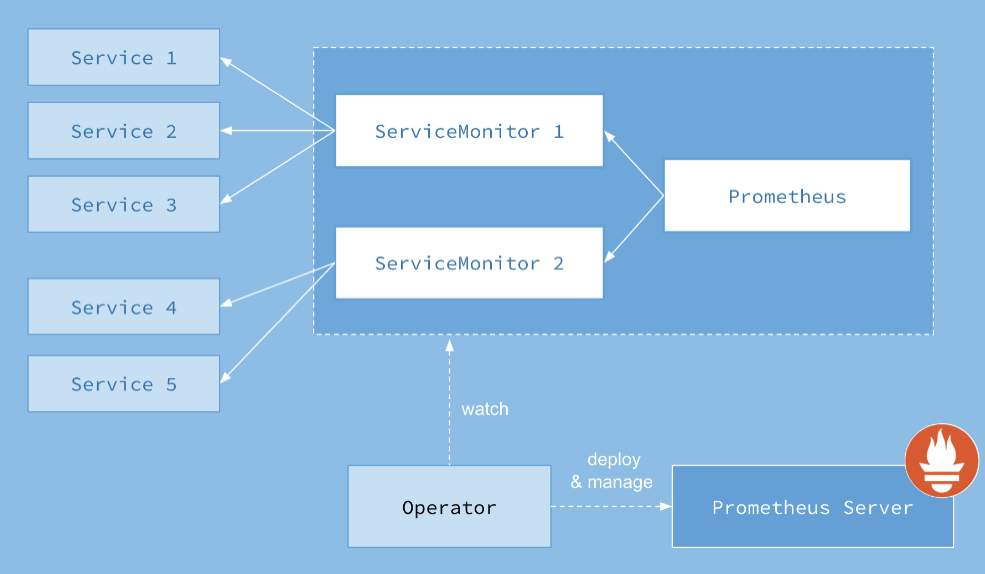
下面三个yaml文件 很好的表述了,prometheus 如何关联选择 servicemonitor,servicemonitor 如何关联选择目标service。
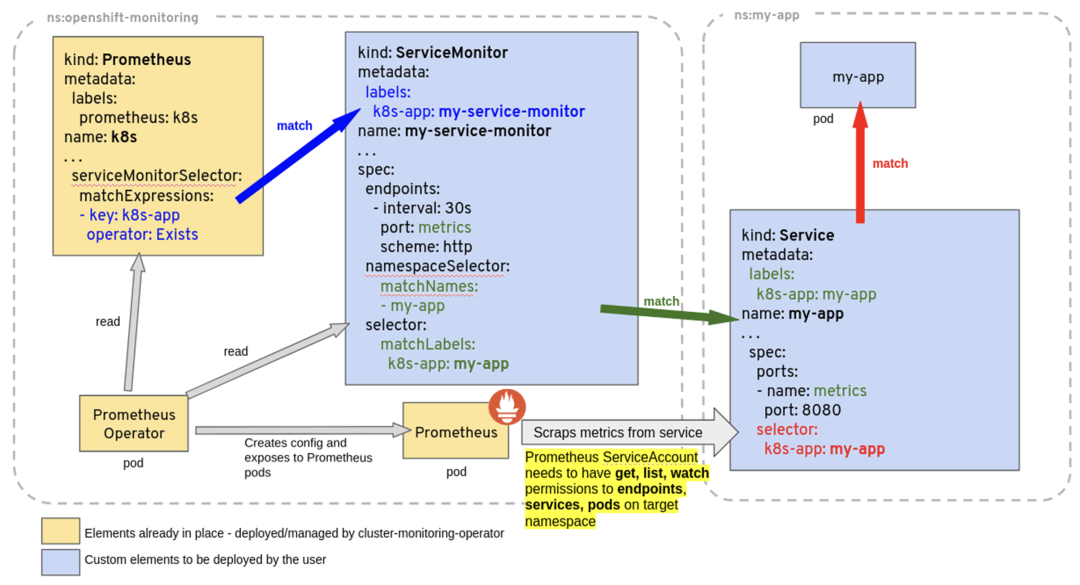
为了能让prom监控k8s内的应用,Prometheus-Operator通过配置servicemonitor匹配到由service对象自动填充的Endpoints,并配置prometheus监控这些Endpoints后端的pods,ServiceMonitor.Spec的Endpoints部分就是用于配置Endpoints的哪些端口将被scrape指标。
servicemonitor对象很巧妙,它解耦了“监控的需求”和“需求的实现方”。servicemonitor 只需要用到label-selector 这种简单又通用的方式声明一个 “监控需求”,也就是哪些Endpoints 需要搜集,怎么收集就行了。让用户只关心需求,这是一个非常好的关注点分离。当然servicemonitor 最后还是会被operator转化为原始的复 杂的scrape config,但这个复杂度已经完全被operator屏蔽了。
下图很好的展现了prometheus在配置报警时需要操作哪些资源,及各资源起到的作用
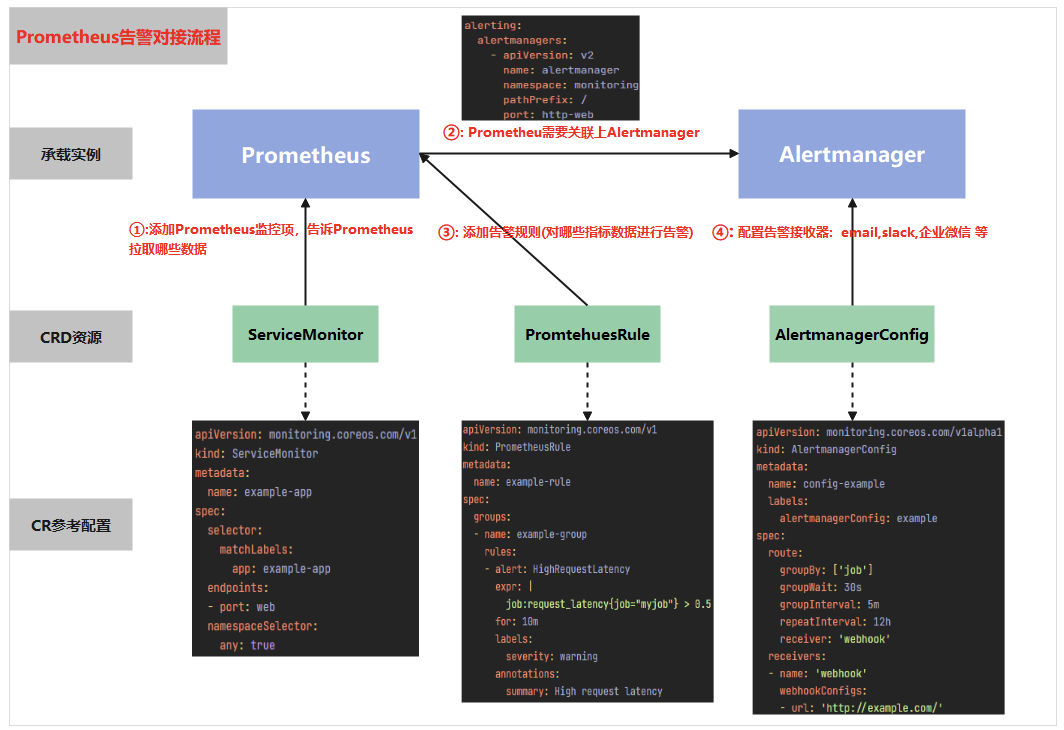
首先通过配置servicemonitor/podmonitor来获取应用的监控指标;
Prometheus.spec.alerting字段会匹配Alertmanager中的配置,匹配到alertmanager实例
然后通过prometheusrule对监控到的指标配置报警规则;
最后配置告警接收器,配置alertmanagerconfig来配置如何处理告警,包括如何接收、路由、抑制和发送警报等;
2.2 常见CRD
Prometheus,定义了所需的 Prometheus 部署。
ServiceMonitor,以声明方式指定应如何监控 Kubernetes 服务组。Operator 根据 API 服务器中对象的当前状态自动生成 Prometheus 抓取配置。
PodMonitor,以声明方式指定应如何监控 pod 组。Operator 根据 API 服务器中对象的当前状态自动生成 Prometheus 抓取配置。
PrometheusRule,定义了一组所需的 Prometheus 警报和/或记录规则。Operator 生成一个规则文件,可供 Prometheus 实例使用。
Alertmanager,定义了所需的 Alertmanager 部署。
AlertmanagerConfig,以声明方式指定 Alertmanager 配置的子部分,允许将警报路由到自定义接收器并设置禁止规则。
Probe,以声明方式指定应如何监视入口组或静态目标。Operator 根据定义自动生成 Prometheus scrape 配置。配合blackbox exporter使用。
ThanosRuler,定义了所需的 Thanos Ruler 部署。
三、 Prometheus-Operator安装
Prometheus-Operator对K8S集群的版本有要求,请参照集群版本选择对应Prometheus-Operator版本代码库:https://github.com/prometheus-operator/kube-prometheus
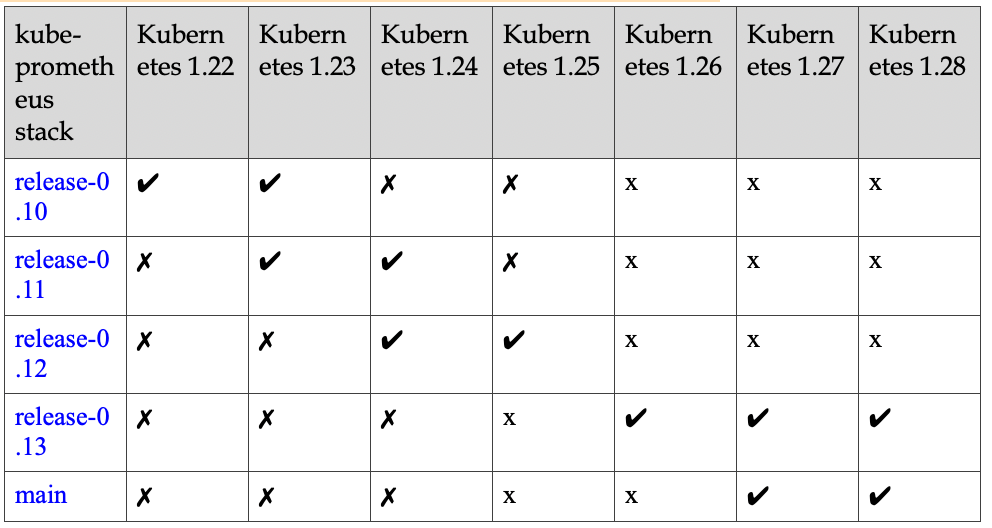
本文档所用环境为1.25k8s集群对应0.12.0版本https://github.com/prometheus-operator/kube-prometheus/archive/refs/heads/release-0.12.zip
3.1 安装
wget https://github.com/prometheus-operator/kube-prometheus/archive/refs/heads/release-0.12.zipunzip release-0.12.zipcd kube-prometheus-release-0.12kubectl apply --server-side -f manifests/setupkubectl wait \--for condition=Established \--all CustomResourceDefinition \--namespace=monitoringkubectl apply -f manifests/
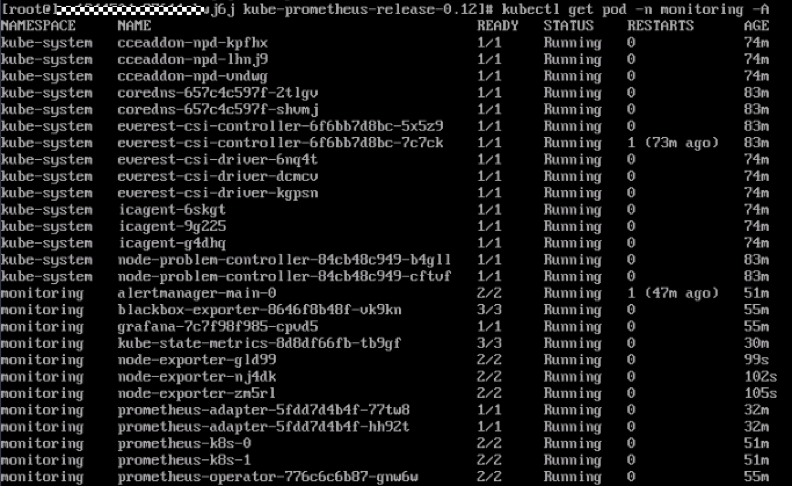
#注意:kube-state-metrics和prometheus-adapter的镜像为谷歌官方库的镜像,国内可能存在拉取不到的问题,如果由于镜像拉取不到导致pod pending,请将其替换成可获取到的镜像地址。
3.2 卸载
注意:此步骤为卸载步骤,如果想继续保留Prometheus-Operator,请不要执行此步骤kubectl delete --ignore-not-found=true -f manifests/ -f manifests/setup
四、使用servicemonitor监控应用暴露的指标
创建deployment对象和service资源,该服务8080端口会暴露自身指标。
apiVersion: apps/v1kind: Deploymentmetadata:labels:app: sample-metrics-appname: sample-metrics-appspec:replicas: 2selector:matchLabels:app: sample-metrics-apptemplate:metadata:labels:app: sample-metrics-appspec:tolerations:- key: beta.kubernetes.io/archvalue: armeffect: NoSchedule- key: beta.kubernetes.io/archvalue: arm64effect: NoSchedule- key: node.alpha.kubernetes.io/unreachableoperator: Existseffect: NoExecutetolerationSeconds: 0- key: node.alpha.kubernetes.io/notReadyoperator: Existseffect: NoExecutetolerationSeconds: 0containers:- image: luxas/autoscale-demo:v0.1.2name: sample-metrics-appports:- name: webcontainerPort: 8080readinessProbe:httpGet:path: /port: 8080initialDelaySeconds: 3periodSeconds: 5livenessProbe:httpGet:path: /port: 8080initialDelaySeconds: 3periodSeconds: 5---apiVersion: v1kind: Servicemetadata:name: sample-metrics-applabels:app: sample-metrics-appspec:ports:- name: webport: 80targetPort: 8080selector:app: sample-metrics-app
创建servicemonitor对象采集应用指标
apiVersion: monitoring.coreos.com/v1kind: ServiceMonitormetadata:name: sample-metrics-applabels:service-monitor: sample-metrics-appspec:selector:matchLabels:app: sample-metrics-app # 匹配标签为app:sample-metrics-app的serviceendpoints:- port: web #Promethues采集指标的端口为service中portName表示的端口
查看新建的service,在集群内节点上通过service IP访问应用kubectl get service

通过访问service IP的metrics接口可以查看到应用暴露的指标curl 10.247.227.116/metrics

可以看到,应用暴露的指标是 “http_requests_total” ,且监控采集到的数量是805
浏览器访问Prometheus UI界面查看指标通过IP和端口访问prometheus-server,查看servermonitor及指标监控情况
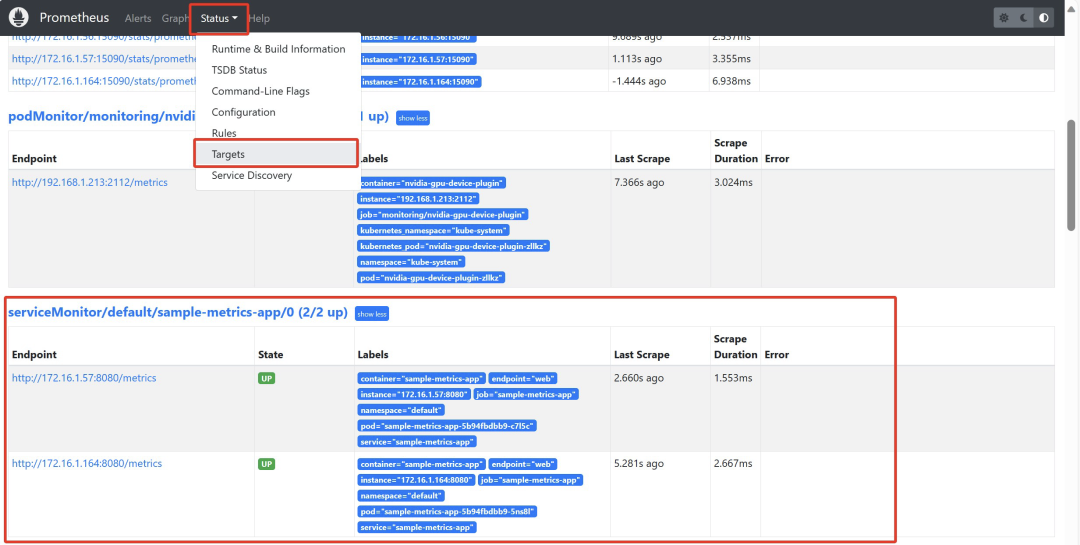
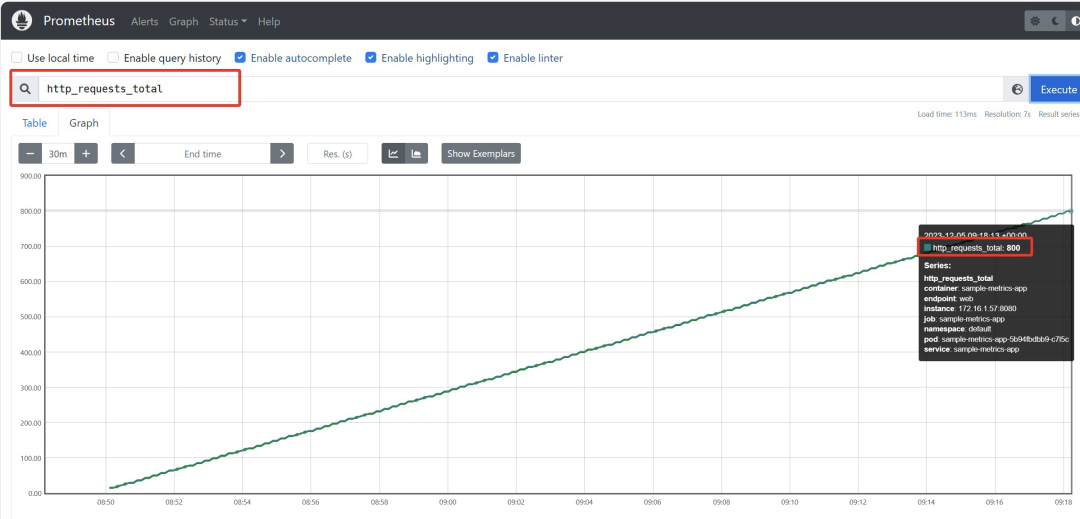
可以看到应用暴露的指标已成功采集,由于指标采集时间间隔的原因,prometheus采集的指标数为800,而应用的metrics接口暴露出的数量为805。
链接:https://www.cnblogs.com/arthinking/p/14450337.html
(版权归原作者所有,侵删)
微
信
群
WeChat group

为方便大家更好的交流运维等相关技术问题,特创建了微信交流群。需要加群的小伙伴们在关注微信公众号后,点击底部菜单关于→联系我,即可获取加群方式。
博客
客
Blog

CSDN博客

掘金博客
长按识别二维码访问博客网站,查看更多优质原创运维等文章。
