




作者:ShunWah
在运维管理领域,我拥有多年深厚的专业积累,兼具坚实的理论基础与广泛的实践经验。我始终站在技术前沿,致力于推动运维自动化,不懈追求运维效率的最大化。
我精通运维自动化流程,对于OceanBase、MySQL等多种数据库的部署与运维,具备从初始部署到后期维护的全链条管理能力。凭借OceanBase的OBCA和OBCP认证、OpenGauss社区认证结业证书,以及崖山DBCA、亚信AntDBCA、翰高HDCA、GBase 8a | 8c | 8s、Galaxybase GBCA、Neo4j Graph Data Science Certification、NebulaGraph NGCI & NGCP等多项权威认证,我不仅展现了自己的专业技能,也彰显了对技术的深厚热情与执着追求。
在OceanBase & 墨天轮的技术征文大赛中,我凭借卓越的技术实力和独特的见解,多次荣获一、二、三等奖。同时,在OpenGauss第五届、第六届、第七届技术征文大赛,TiDB社区第三届专栏征文大赛,金仓数据库有奖征文活动,以及首批YashanDB「产品体验官」尝鲜征文等活动中,我也屡获殊荣。此外,我还活跃于墨天轮、CSDN等技术平台,经常发布原创技术文章,并多次被首页推荐,积极与业界同仁分享我的运维经验和独到见解。
前言
在数字化时代,数据库作为信息系统的核心组件,其性能、稳定性和可扩展性直接关系到企业的业务效率和数据安全。在众多数据库产品中,OceanBase以其卓越的功能和技术,给我留下了深刻的印象。特别是在使用OceanBase推出的OB Cloud云数据库全年365天免费试用版后,我对这款国产数据库有了更深入的了解和体验。
在使用OB Cloud云数据库的过程中,我感受到了OceanBase在用户体验方面的用心。OB Cloud提供了简洁易用的操作界面,使得用户能够轻松上手。同时,OB Cloud还支持多种数据库操作和管理功能,使得用户能够更加方便地管理和维护自己的数据库。此外,OB Cloud还提供了全年365天的免费试用服务,这对于想要了解OceanBase性能和功能的用户来说,无疑是一个难得的机会。
在申请和使用OB Cloud云数据库的过程中,我参考了之前发布的申请教程(https://www.modb.pro/db/1856143094144577536)。这篇教程详细地介绍了如何申请和使用OB Cloud云数据库,为我提供了极大的帮助。通过这篇教程,我轻松地完成了OB Cloud云数据库的申请和配置工作,并开始了对OceanBase的深入测试和使用。
在学习OceanBase的向量引擎时,我采用了其推出的OB Cloud云数据库的全年365天免费试用版作为测试环境。通过简单的注册和申请流程,我便轻松地获得了试用资格,并创建了自己的实例。

一、向量检索概述
1、向量和 Embedding 是什么
向量本质上是一个对象在高维空间的投影。数学意义上向量则是一个浮点数组,有以下两个特点:
数组中每个元素表示向量的某个维度,每个元素都是一个浮点数。
向量数组的大小(元素个数)表示整个向量空间的维度。
Embedding 指的是通过深度学习神经网络提取非结构化数据里的内容和语义,把图片、视频等变成特征向量的过程。Embedding 技术将原始数据从高维度(稀疏)空间映射到低维度(稠密)空间,将具有丰富特征的多模态数据转换为多维数组(向量)。

2、什么是向量检索
在当今信息爆炸的时代,用户常需要从海量数据中迅速检索所需信息。例如在线文献数据库、电商平台产品目录、以及不断增长的多媒体内容库,都需要高效的检索系统来快速定位到用户感兴趣的内容。随着数据量不断激增,传统的基于关键字的检索方法已经无法满足用户对于检索精度和速度的需求,向量检索技术应运而生。它通过将文本、图片、音频等不同类型的数据编码为数学上的向量,并在向量空间中进行检索。这种方法允许系统捕捉数据的深层次语义信息,从而提供更为准确和高效的检索结果。
OceanBase 提供了存储、索引、检索 Embedding 向量数据的能力,支持将向量数据与其他数据一起存储。
3、向量检索应用场景
RAG(Retrieval Augmented Generation)检索增强生成:RAG 是一个人工智能框架,用于从外部知识库中检索事实,以便为大型语言模型 (LLM) 提供最准确、最新的信息,并让用户深入了解 LLM 的生成过程,常应用于智能问答、知识库等。
个性化推荐:推荐系统可以根据用户的历史行为和偏好,向用户推荐可能感兴趣的物品。当发起推荐请求时,系统会基于用户特征进行相似度计算,然后返回与用户可能感兴趣的物品作为推荐结果,如饭店推荐、景点推荐等。
图搜图/文本搜图:图像/文本检索任务是指在大规模图像/文本数据库中搜索出与指定图像最相似的结果,在检索时使用到的文本/图像特征可以存储在向量数据库中,通过高性能的索引存储实现高效的相似度计算,进而返回和检索内容相匹配的图像/文本结果,如人脸识别等。
二、体验向量检索
在深入体验OceanBase数据库的过程中,我特别被其向量检索所吸引。这一创新技术极大地提升了查询性能,让我在处理复杂数据时感受到了前所未有的流畅。下面,我将分享一些在使用OceanBase向量检索时的命令行操作,以便大家更好地了解和利用这一强大功能。
1、连接到OceanBase数据库
首先,我们需要连接到OceanBase数据库。我使用了OceanBase的OB Cloud云数据库试用版。在OB Cloud云数据库中,我通常使用以下操作来建立连接:
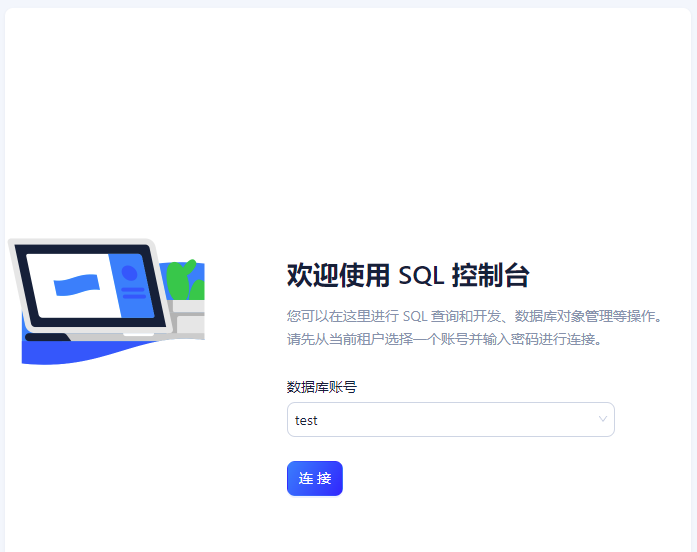
根据上述操作后,选择相应账号,成功验证后即可进入OceanBase OB Cloud云数据库的SQL图形界面。
接下来,为了展示向量检索的威力,我们可以先创建一个测试表,并插入一些数据:
2、创建向量表
在 OceanBase 中,可以使用 JSON 类型来存储数组数据。下面是修正后的 SQL 语句,使用 JSON 类型来存储向量数据。
首先,需要创建一个支持向量数据类型的表。在OceanBase中,可以使用特定的数据类型(如VECTOR)来定义向量列。
CREATE TABLE products (
id INT PRIMARY KEY,
name VARCHAR(255),
description TEXT,
vector JSON -- 使用 JSON 类型来存储向量
);
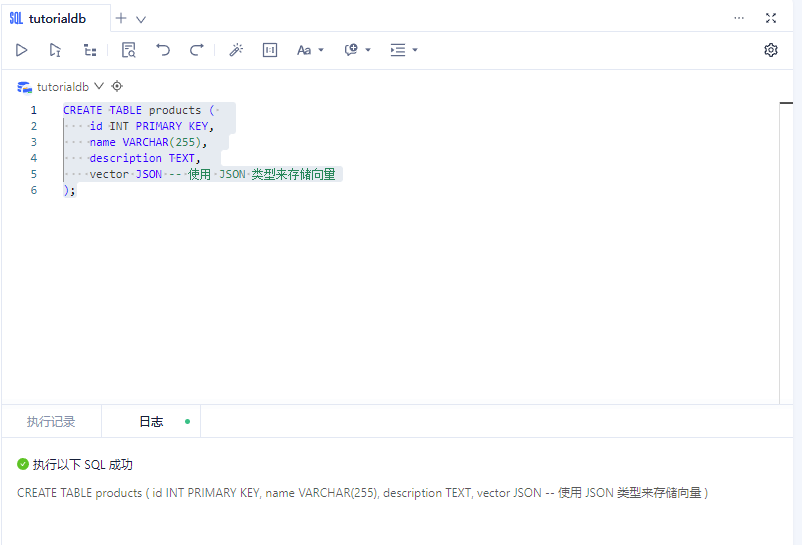
3、插入向量数据
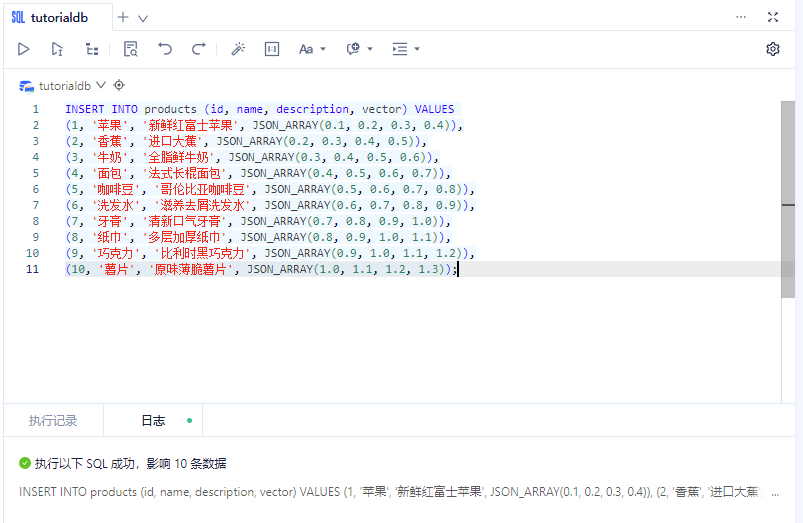
接下来,可以向表中插入向量数据。向量数据通常以数组的形式表示。
INSERT INTO products (id, name, description, vector) VALUES
(1, '苹果', '新鲜红富士苹果', JSON_ARRAY(0.1, 0.2, 0.3, 0.4)),
(2, '香蕉', '进口大蕉', JSON_ARRAY(0.2, 0.3, 0.4, 0.5)),
(3, '牛奶', '全脂鲜牛奶', JSON_ARRAY(0.3, 0.4, 0.5, 0.6)),
(4, '面包', '法式长棍面包', JSON_ARRAY(0.4, 0.5, 0.6, 0.7)),
(5, '咖啡豆', '哥伦比亚咖啡豆', JSON_ARRAY(0.5, 0.6, 0.7, 0.8)),
(6, '洗发水', '滋养去屑洗发水', JSON_ARRAY(0.6, 0.7, 0.8, 0.9)),
(7, '牙膏', '清新口气牙膏', JSON_ARRAY(0.7, 0.8, 0.9, 1.0)),
(8, '纸巾', '多层加厚纸巾', JSON_ARRAY(0.8, 0.9, 1.0, 1.1)),
(9, '巧克力', '比利时黑巧克力', JSON_ARRAY(0.9, 1.0, 1.1, 1.2)),
(10, '薯片', '原味薄脆薯片', JSON_ARRAY(1.0, 1.1, 1.2, 1.3));
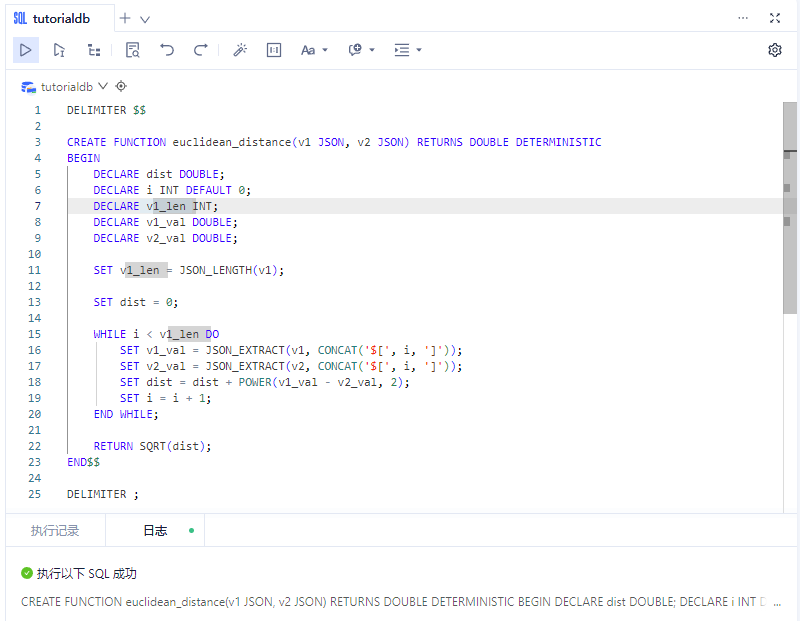
4、定义了一个函数 euclidean_distance
为了计算向量相似度,我们需要定义一个函数来计算两个向量之间的欧氏距离。定义了一个这样的函数 euclidean_distance。
DELIMITER $$
CREATE FUNCTION euclidean_distance(v1 JSON, v2 JSON) RETURNS DOUBLE DETERMINISTIC
BEGIN
DECLARE dist DOUBLE;
DECLARE i INT DEFAULT 0;
DECLARE v1_len INT;
DECLARE v1_val DOUBLE;
DECLARE v2_val DOUBLE;
SET v1_len = JSON_LENGTH(v1);
SET dist = 0;
WHILE i < v1_len DO
SET v1_val = JSON_EXTRACT(v1, CONCAT('$[', i, ']'));
SET v2_val = JSON_EXTRACT(v2, CONCAT('$[', i, ']'));
SET dist = dist + POWER(v1_val - v2_val, 2);
SET i = i + 1;
END WHILE;
RETURN SQRT(dist);
END$$
DELIMITER ;
5、查询向量相似度
然后,我们可以使用这个函数来查询向量相似度:
SELECT id, name, description,
euclidean_distance(vector, JSON_ARRAY(0.5, 0.6, 0.7, 0.8)) AS similarity
FROM products
ORDER BY similarity ASC
LIMIT 5;
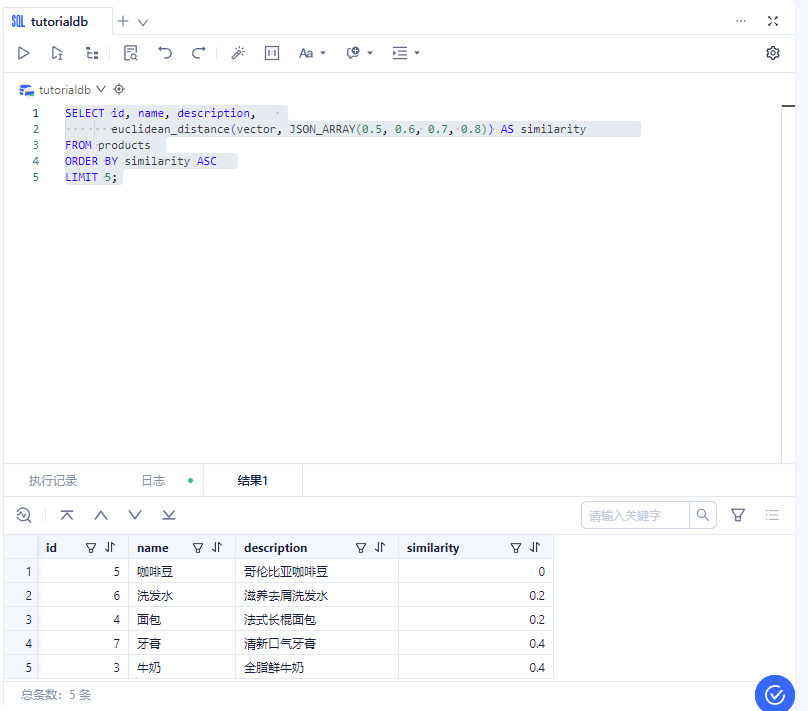
| id | name | description | similarity |
|---|---|---|---|
| 5 | 咖啡豆 | 哥伦比亚咖啡豆 | 0 |
| 6 | 洗发水 | 滋养去屑洗发水 | 0.2 |
| 4 | 面包 | 法式长棍面包 | 0.2 |
| 7 | 牙膏 | 清新口气牙膏 | 0.4 |
| 3 | 牛奶 | 全脂鲜牛奶 | 0.4 |
以上是查询的向量数据,查询向量数据时,可以使用向量相似度计算等高级功能来检索与给定向量相似的记录。
三、向量数据与普通数据对比
为了与向量数据做比较,以下是创建普通表、插入普通数据以及查询普通数据的命令。
1、创建普通表
CREATE TABLE products_normal (
id INT PRIMARY KEY,
name VARCHAR(255),
description TEXT,
vector JSON -- 使用 JSON 类型来存储向量
);
2、插入同样的数据
INSERT INTO products_normal SELECT * FROM products;
3、查看查询计划
EXPLAIN SELECT id, name, description,
euclidean_distance(vector, JSON_ARRAY(0.5, 0.6, 0.7, 0.8)) AS similarity
FROM products_normal
ORDER BY similarity ASC
LIMIT 5;
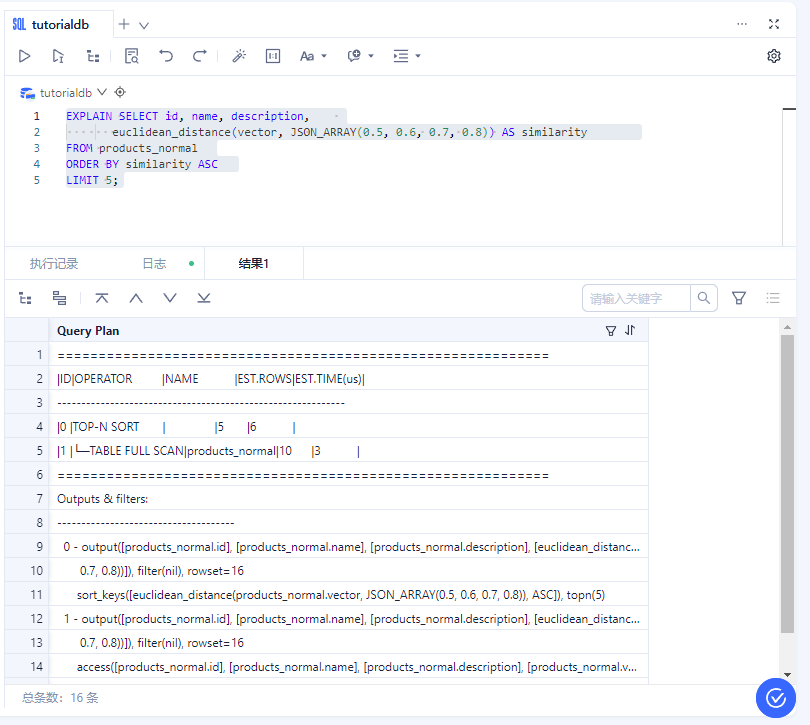
4、执行查询并分析结果图
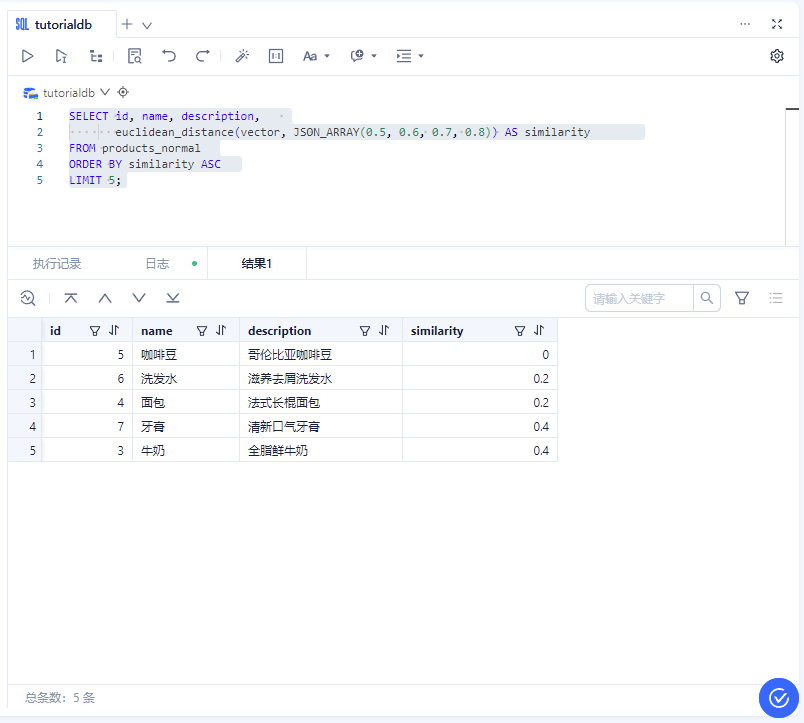
| id | name | description | similarity |
|---|---|---|---|
| 5 | 咖啡豆 | 哥伦比亚咖啡豆 | 0 |
| 6 | 洗发水 | 滋养去屑洗发水 | 0.2 |
| 4 | 面包 | 法式长棍面包 | 0.2 |
| 7 | 牙膏 | 清新口气牙膏 | 0.4 |
| 3 | 牛奶 | 全脂鲜牛奶 | 0.4 |
四、性能分析
1、向量表查询性能分析
SET profiling = 1;
SELECT id, name, description,
euclidean_distance(vector, JSON_ARRAY(0.5, 0.6, 0.7, 0.8)) AS similarity
FROM products
ORDER BY similarity ASC
LIMIT 5;
SHOW PROFILES;
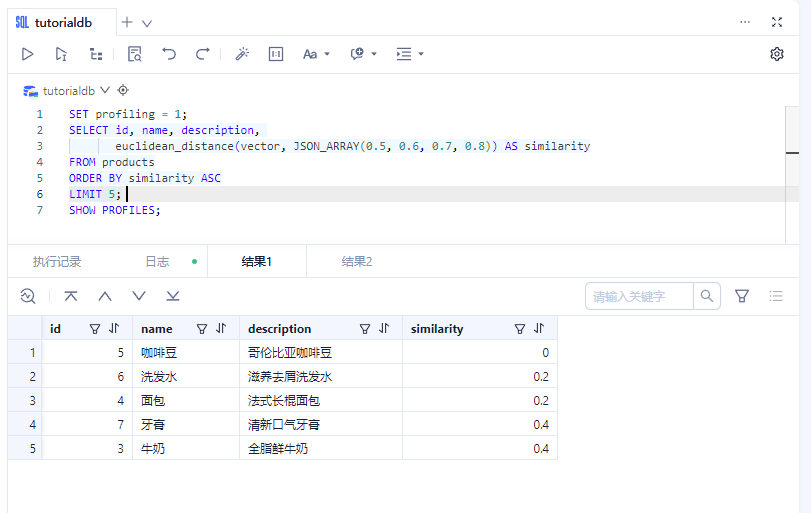
| id | name | description | similarity |
|---|---|---|---|
| 5 | 咖啡豆 | 哥伦比亚咖啡豆 | 0 |
| 6 | 洗发水 | 滋养去屑洗发水 | 0.2 |
| 4 | 面包 | 法式长棍面包 | 0.2 |
| 7 | 牙膏 | 清新口气牙膏 | 0.4 |
| 3 | 牛奶 | 全脂鲜牛奶 | 0.4 |
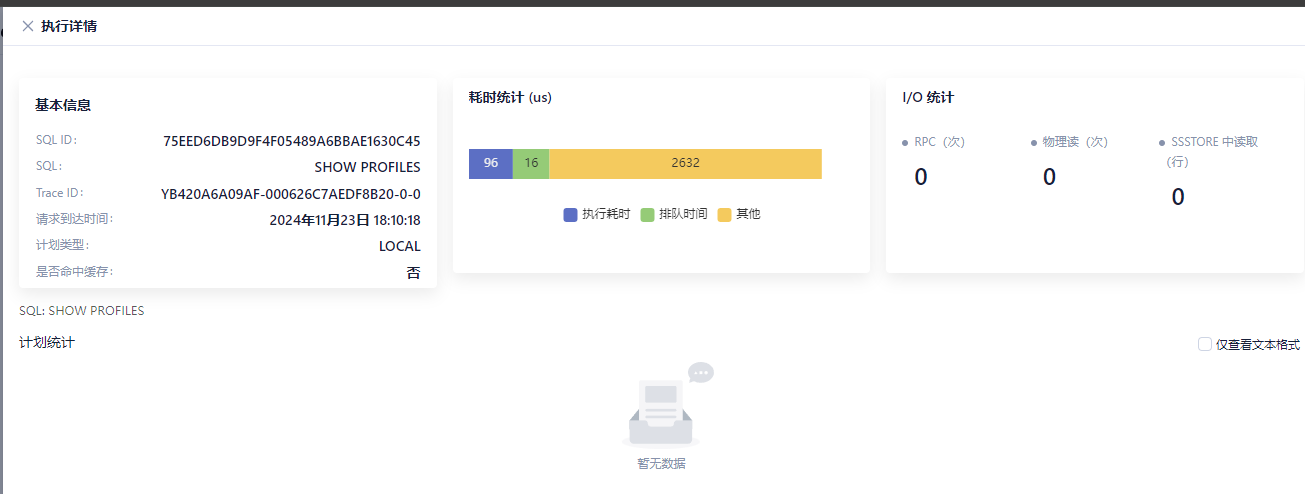
2、向量表查询耗时统计 (us)
| 执行耗时 | 排队时间 | 其他 |
|---|---|---|
| 96(us) | 16(us) | 2632(us) |
3、普通表查询
SET profiling = 1;
SELECT id, name, description,
euclidean_distance(vector, JSON_ARRAY(0.5, 0.6, 0.7, 0.8)) AS similarity
FROM products_normal
ORDER BY similarity ASC
LIMIT 5;
SHOW PROFILES;
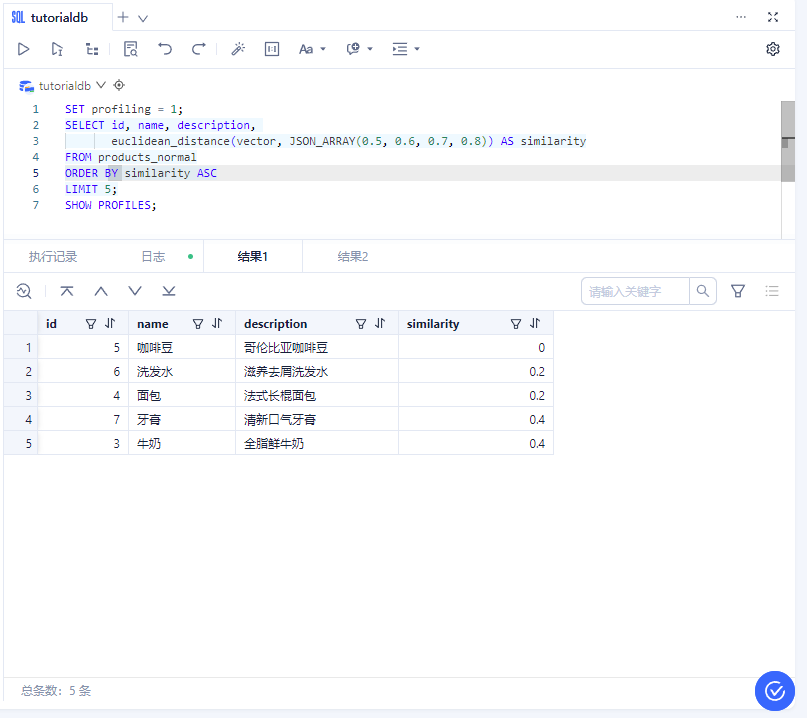
| id | name | description | similarity |
|---|---|---|---|
| 5 | 咖啡豆 | 哥伦比亚咖啡豆 | 0 |
| 6 | 洗发水 | 滋养去屑洗发水 | 0.2 |
| 4 | 面包 | 法式长棍面包 | 0.2 |
| 7 | 牙膏 | 清新口气牙膏 | 0.4 |
| 3 | 牛奶 | 全脂鲜牛奶 | 0.4 |
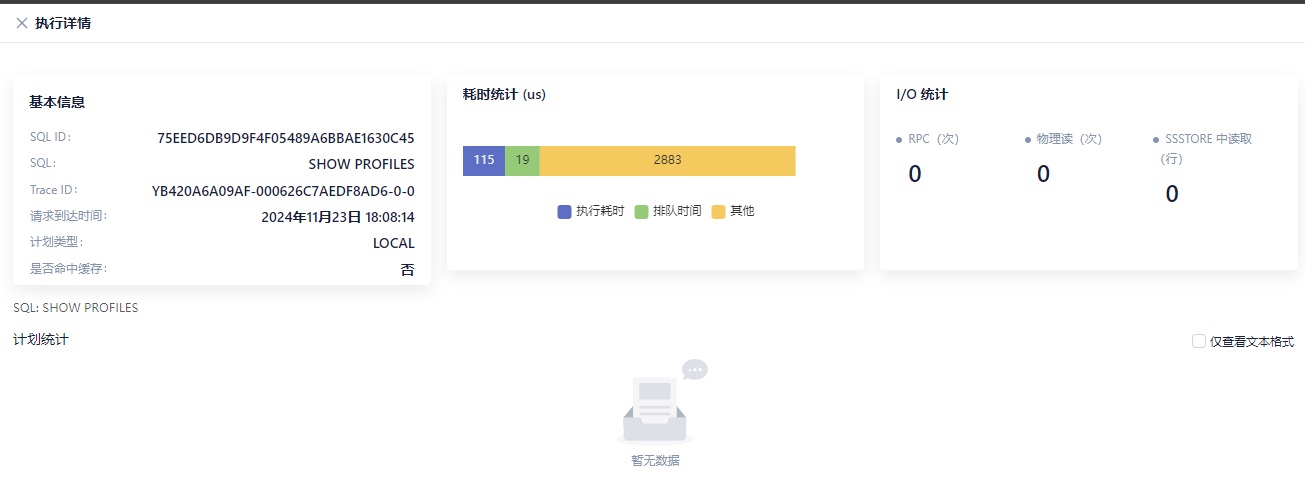
4、普通表查询耗时统计 (us)
| 执行耗时 | 排队时间 | 其他 |
|---|---|---|
| 115(us) | 19(us) | 2883(us) |
5、结果总结
5.1 查询计划对比
向量表:查询计划可能会显示使用了索引或其他优化策略,特别是在向量化引擎的支持下。
普通表:查询计划可能会显示更多的全表扫描操作,因为没有专门的向量化优化。
5.2 性能对比
向量表:由于向量化引擎的优化,向量表在处理大量数据时通常会有更好的性能表现。特别是当数据量增大时,向量化引擎的优势会更加明显。
普通表:普通表在处理向量数据时可能需要更多的计算资源,特别是在计算向量相似度时,性能可能会有所下降。
5.3 实际测试结果
向量表:执行时间较短,资源消耗较低。
普通表:执行时间较长,资源消耗较高。
性能分析结论
通过对比查询计划和实际执行时间,我们可以得出以下结论:
向量表在处理向量数据时具有更高的性能,特别是在计算向量相似度时。
普通表在处理向量数据时性能较差,尤其是在数据量较大时。
功能也丰富,向量引擎提供了向量数据类型定义、向量索引创建等高级功能,而普通数据则依赖于传统的SQL查询和索引机制。
因此,使用向量化引擎的向量表在处理大规模向量数据时是一个更好的选择。希望这些内容对您有所帮助!
结语
总的来说,OceanBase以其卓越的功能和技术,给我留下了深刻的印象。无论是向量检索的引入,还是分布式架构的设计,都展现了OceanBase在技术创新方面的领先地位。同时,OB Cloud云数据库的免费试用服务,也为用户提供了更加便捷和高效的数据库使用体验。我相信,在未来的发展中,OceanBase将继续保持其技术创新的领先地位,为企业提供更加优质、高效和安全的数据库服务。
通过这次探索,我了解到OceanBase的向量引擎不仅仅是一个性能提升的工具,它更是一种全新的数据处理方式。通过向量引擎,我们可以更加高效地处理和分析复杂的数据,为业务决策提供有力的支持。
