




介绍
由于想写个工具,正好磐维也是基于opengauss的,所以研究了一下的底层存储结构。opengauss的存储结构和pg相差不大,只是多了几个结构体字段,下面就着代码来讲,也作为一个自己的记录。存储代码位于src/include/storage,page部分的代码位于buf/bufpage.h。
page结构
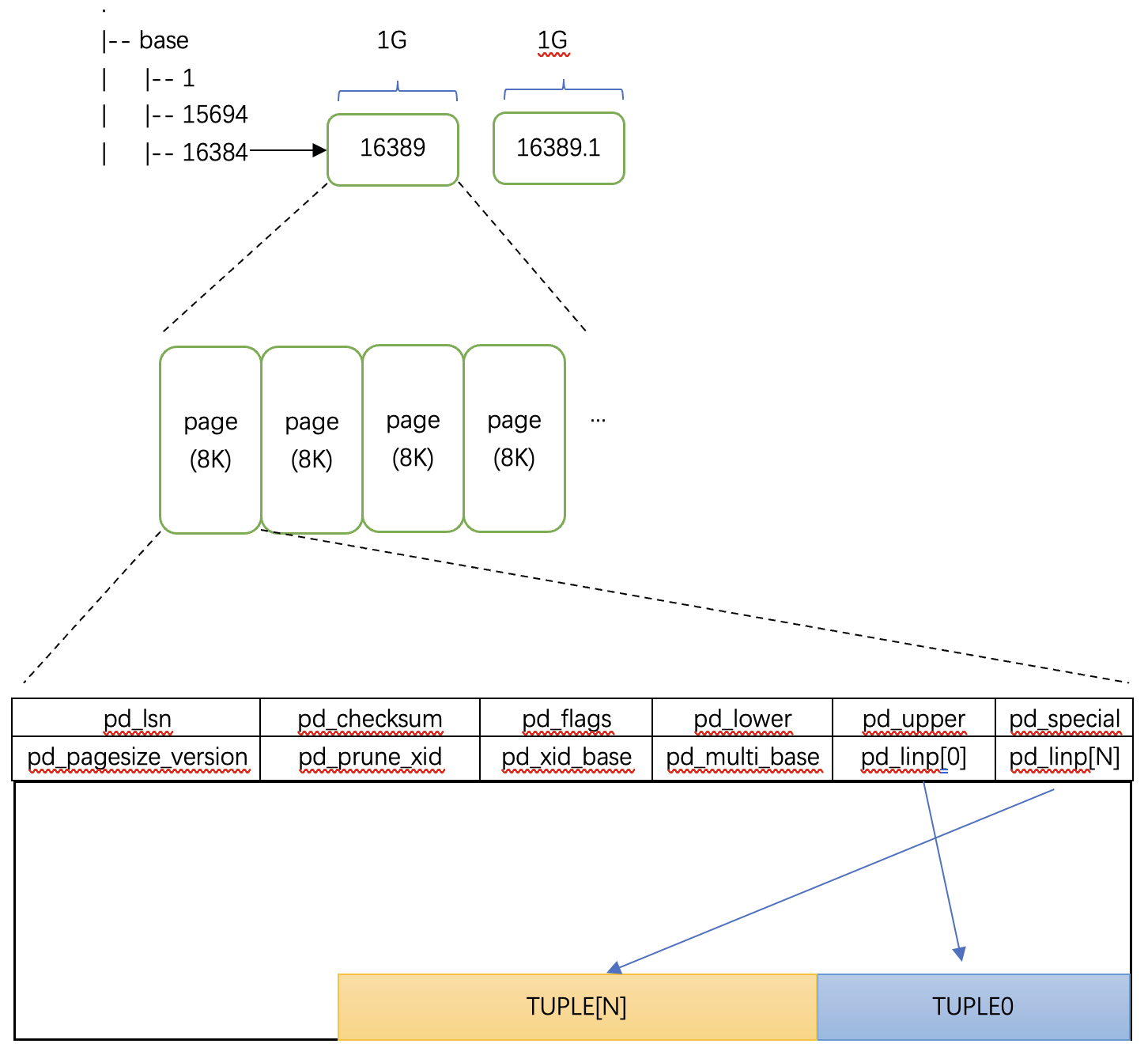
可以看到,page结构里,多了两个字段:pd_xid_base、pd_multi_base,这两个字段类型都是TransactionId,定义为:
typedef uint64 TransactionId;
总体结构体定义:
typedef struct {
/* XXX LSN is member of *any* block, not only page-organized ones */
PageXLogRecPtr pd_lsn; /* LSN: next byte after last byte of xlog
* record for last change to this page */
uint16 pd_checksum; /* checksum */
uint16 pd_flags; /* flag bits, see below */
LocationIndex pd_lower; /* offset to start of free space */
LocationIndex pd_upper; /* offset to end of free space */
LocationIndex pd_special; /* offset to start of special space */
uint16 pd_pagesize_version;
ShortTransactionId pd_prune_xid; /* oldest prunable XID, or zero if none */
TransactionId pd_xid_base; /* base value for transaction IDs on page */
TransactionId pd_multi_base; /* base value for multixact IDs on page */
ItemIdData pd_linp[FLEXIBLE_ARRAY_MEMBER]; /* beginning of line pointer array */
} HeapPageHeaderData;
typedef HeapPageHeaderData* HeapPageHeader;
各字段的解释
1、 pd_lsn记录了最后一次更改所写入的xlog的lsn号,共占用8个字节,定义:
typedef struct {
uint32 xlogid; /* high bits */
uint32 xrecoff; /* low bits */
} PageXLogRecPtr;
2、pd_checksum记录了这个page的校验值,占2个字节。
3、pd_flags设置标志位,相比于PG的4个标志位,opengauss多了很多。标志位定义如下,注释也说的很明白:
/*
* pd_flags contains the following flag bits. Undefined bits are initialized
* to zero and may be used in the future.
*
* PD_HAS_FREE_LINES is set if there are any LP_UNUSED line pointers before
* pd_lower. This should be considered a hint rather than the truth, since
* changes to it are not WAL-logged.
*
* PD_PAGE_FULL is set if an UPDATE doesn't find enough free space in the
* page for its new tuple version; this suggests that a prune is needed.
* Again, this is just a hint.
*/
#define PD_HAS_FREE_LINES 0x0001 /* are there any unused line pointers? */
#define PD_PAGE_FULL 0x0002 /* not enough free space for new tuple? */
#define PD_ALL_VISIBLE 0x0004 /* all tuples on page are visible to everyone */
#define PD_COMPRESSED_PAGE 0x0008 /* compressed page flag */
#define PD_LOGICAL_PAGE 0x0010 /* logical page flag used by bulkload or copy */
#define PD_ENCRYPT_PAGE 0x0020 /* is a encryt cluster */
#define PD_CHECKSUM_FNV1A 0x0040 /* page checksum using FNV-1a hash */
#define PD_JUST_AFTER_FPW 0x0080 /* page just after redo full page write */
#define PD_EXRTO_PAGE 0x0400 /* is a rto file page */
#define PD_TDE_PAGE 0x0100 /* there is TdePageInfo at the end of a page */
#define PD_VALID_FLAG_BITS 0x01FF /* OR of all valid pd_flags bits */
4、pd_lower该指针指向了空闲也起始位置
5、pd_upper该指针指向了空闲页的终止位置
6、pd_special该指针指向了特殊空间的起始偏移量
7、pd_pagesize_version一个2字节的标识,标识了页面大小与版本号
8、pd_prune_xid标识了可删除的旧XID,如果没有则为零。
9、pd_xid_base标识了事物ID的基础值
10、pd_multi_base记录组合事物的ID的基础值
11、pd_linp记录一个指针,该指针指向具体的row,没有数据时为0。它包含了三个成员变量,lp_off标识了元组的偏移量,lp_flags标识了元组状态,lp_len标识了元组的长度,具体结构如下:
typedef struct ItemIdData {
unsigned lp_off : 15, /* offset to tuple (from start of page) */
lp_flags : 2, /* state of item pointer, see below */
lp_len : 15; /* byte length of tuple */
} ItemIdData;
typedef ItemIdData* ItemId;
其中,lp_flags状态定义如下:
/*
* lp_flags has these possible states. An UNUSED line pointer is available
* for immediate re-use, the other states are not.
*/
#define LP_UNUSED 0 /* unused (should always have lp_len=0) */
#define LP_NORMAL 1 /* used (should always have lp_len>0) */
#define LP_REDIRECT 2 /* HOT redirect (should have lp_len=0) */
#define LP_DEAD 3 /* dead, may or may not have storage */
#define LP_INDEX_FROZEN 2 /* index tuple's xmin is frozen (used for multi-version btree index only) */
tuple元组
上面有个pd_linp的成员,它就是直接指向元组(tuple)的起始地址,先来看看tuple相关的定义:
typedef struct HeapTupleHeaderData {
union {
HeapTupleFields t_heap;
DatumTupleFields t_datum;
} t_choice;
ItemPointerData t_ctid; /* current TID of this or newer tuple */
/* Fields below here must match MinimalTupleData! */
uint16 t_infomask2; /* number of attributes + various flags */
uint16 t_infomask; /* various flag bits, see below */
uint8 t_hoff; /* sizeof header incl. bitmap, padding */
/* ^ - 23 bytes - ^ */
bits8 t_bits[FLEXIBLE_ARRAY_MEMBER]; /* bitmap of NULLs -- VARIABLE LENGTH */
/* MORE DATA FOLLOWS AT END OF STRUCT */
} HeapTupleHeaderData;
typedef HeapTupleHeaderData* HeapTupleHeader;
各字段的解释
1、开始就有一个t_choice成员体的结构,这里主要用到了HeapTupleFields,来看看结构:
typedef struct HeapTupleFields {
ShortTransactionId t_xmin; /* inserting xact ID */
ShortTransactionId t_xmax; /* deleting or locking xact ID */
union {
CommandId t_cid; /* inserting or deleting command ID, or both */
ShortTransactionId t_xvac; /* old-style VACUUM FULL xact ID */
} t_field3;
} HeapTupleFields;
typedef uint32 ShortTransactionId;
typedef uint32 CommandId;
这里就很明确了,t_xmin,t_xmax,t_cid都是事物相关的
2、t_ctid保存指向自身或是新元组的元组表示符。当该元组被更新时,该元组的t_ctid指向新的元组;否则,t_ctid指向自身。
3、t_infomask2表示当前元组的属性个数。t_infomask用于标识元组的当前状态,比如是否空属性、是否具有对象id、是否具有外部存储属性等等。具体定义如下:
/*
* information stored in t_infomask:
*/
#define HEAP_HASNULL 0x0001 /* has null attribute(s) */
#define HEAP_HASVARWIDTH 0x0002 /* has variable-width attribute(s) */
#define HEAP_HASEXTERNAL 0x0004 /* has external stored attribute(s) */
#define HEAP_HASOID 0x0008 /* has an object-id field */
#define HEAP_COMPRESSED 0x0010 /* has compressed data */
#define HEAP_COMBOCID 0x0020 /* t_cid is a combo cid */
#define HEAP_XMAX_EXCL_LOCK 0x0040 /* xmax is exclusive locker */
#define HEAP_XMAX_SHARED_LOCK 0x0080 /* xmax is shared locker */
/* xmax is a key-shared locker */
#define HEAP_XMAX_KEYSHR_LOCK (HEAP_XMAX_EXCL_LOCK | HEAP_XMAX_SHARED_LOCK)
#define HEAP_LOCK_MASK (HEAP_XMAX_EXCL_LOCK | HEAP_XMAX_SHARED_LOCK | HEAP_XMAX_KEYSHR_LOCK)
#define HEAP_XMIN_COMMITTED 0x0100 /* t_xmin committed */
#define HEAP_XMIN_INVALID 0x0200 /* t_xmin invalid/aborted */
#define HEAP_XMIN_FROZEN (HEAP_XMIN_INVALID | HEAP_XMIN_COMMITTED)
#define HEAP_XMAX_COMMITTED 0x0400 /* t_xmax committed */
#define HEAP_XMAX_INVALID 0x0800 /* t_xmax invalid/aborted */
#define HEAP_XMAX_IS_MULTI 0x1000 /* t_xmax is a MultiXactId */
#define HEAP_UPDATED 0x2000 /* this is UPDATEd version of row */
#define HEAP_HAS_8BYTE_UID (0x4000) /* tuple has 8 bytes uid */
#define HEAP_UID_MASK (0x4000)
#define NDP_HANDLED_TUPLE (0x8000) /* tuple is from ndp backend */
#define HEAP_XACT_MASK (0x3FE0) /* visibility-related bits */
/*
* information stored in t_infomask2:
*/
#define HEAP_NATTS_MASK 0x07FF /* 11 bits for number of attributes */
#define HEAP_XMAX_LOCK_ONLY 0x0800 /* xmax, if valid, is only a locker */
#define HEAP_KEYS_UPDATED 0x1000 /* tuple was updated and key cols modified, or tuple deleted */
#define HEAP_HAS_REDIS_COLUMNS 0x2000 /* tuple has hidden columns added by redis */
#define HEAP_HOT_UPDATED 0x4000 /* tuple was HOT-updated */
#define HEAP_ONLY_TUPLE 0x8000 /* this is heap-only tuple */
#define HEAP2_XACT_MASK 0xD800 /* visibility-related bits */
4、t_hoff标识该元组头的大小。成员t_bits数组用于标识当前元组哪些字段是空。
5、t_bits,比特map,标识NULL值
6、后面就是具体的数据
实例
具体说了这么多概念,下面来用实例来印证一下
首先创建数据库和表,然后插入数据,再看一下表文件是哪个文件,可以看到创建到24604这个文件里了
postgres=# CREATE DATABASE test;
CREATE DATABASE
test=#
test=# CREATE TABLE t1(id int, name VARCHAR(20), age int);
CREATE TABLE
test=# insert into t1 values(9009,'xiaoming1',100);
INSERT 0 1
test=#
test=#
test=# select pg_relation_filepath('t1');
base/16389/24604
接下来,我们直接vim打开24604这个文件,进入后,用:%!xxd转换成16进制查看。先摘取头几行的内容来印证,也就是对应到HeapPageHeaderData这个结构体的内容
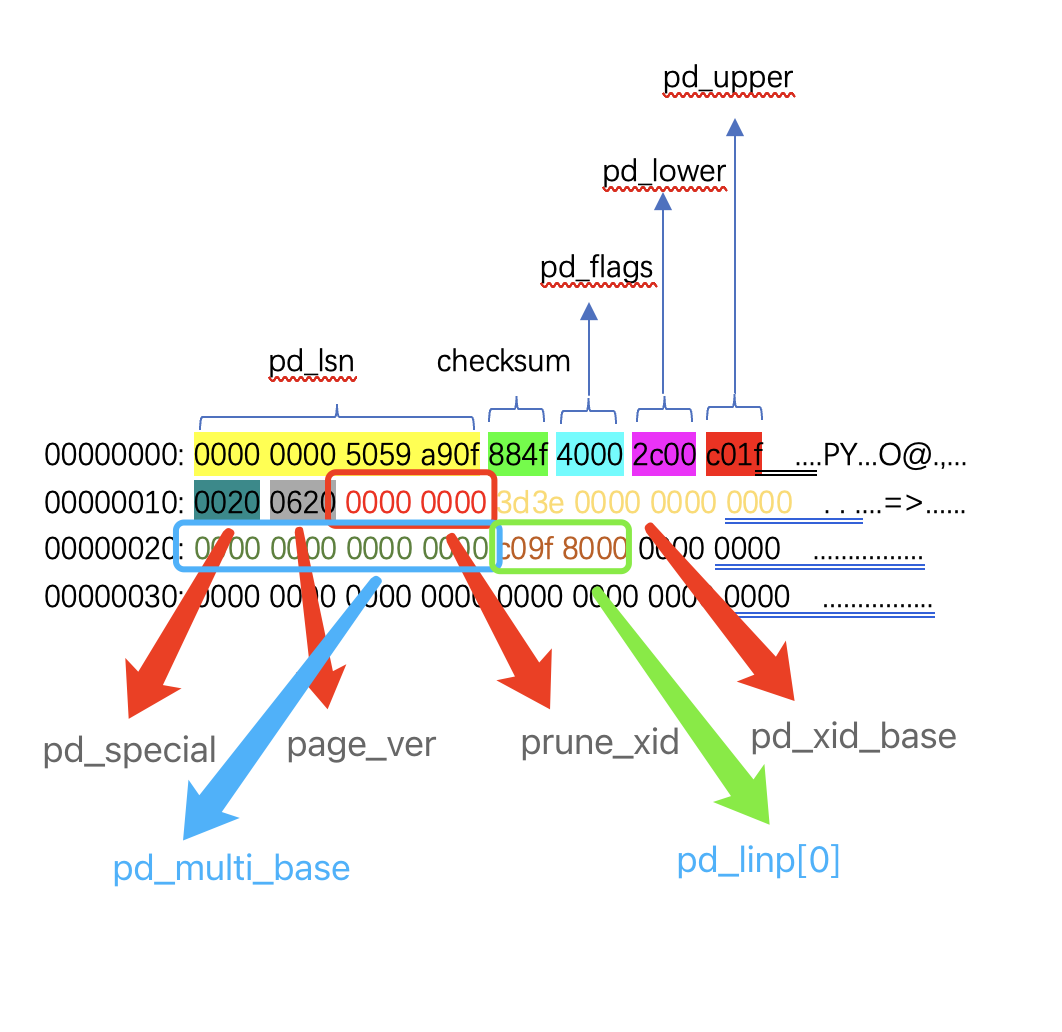
00000000: 0000 0000 5059 a90f 884f 4000 2c00 c01f ....PY...O@.,... 00000010: 0020 0620 0000 0000 3d3e 0000 0000 0000 . . ....=>...... 00000020: 0000 0000 0000 0000 c09f 8000 0000 0000 ................ 00000030: 0000 0000 0000 0000 0000 0000 0000 0000 ................
为了方便查看,画了个图更直观些,这个就是解析到的Header。
如何计算
上图很直观的可以看出结构体每个成员所对应的16进制字符,那么如何计算出具体的数据内容所在位置及其含义呢?上图里,最重要的就是pd_upper、pd_lower、pd_linp这三个数值
-
pd_lower
前面说过,pd_lower是指向了空闲页起始的地址。将2c00按照小端序排序为002c,转换为十进制后是44,说明其实地址在第44个字节的地方,正好指向到了8000, -
pd_upper
pd_upper是指向到空闲页的结尾,也就是说指向了元组开始的地址,按小端序排序为:1fc0这个地址,后续我们再做解析 -
pd_linp
pd_linp表示的4字节(c09f 8000)是指向元组的行指针pd_linp,按照小端序排序后:00809fc0,转换为二进制后为:100000001001111111000000
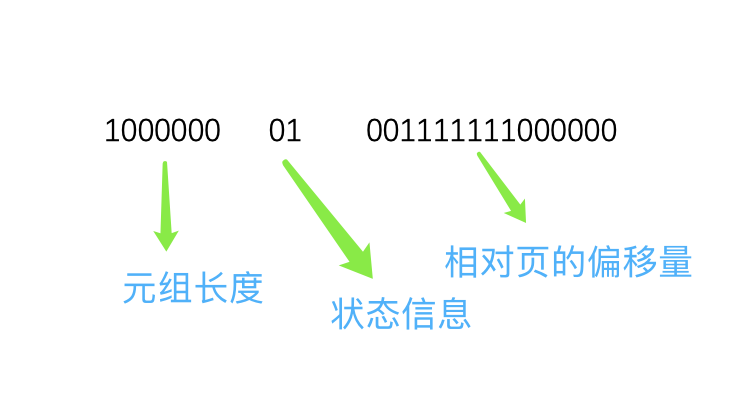
相对页的偏移量,这个很好理解就是相对于page,元组所在的偏移量地址。元组状态上面有定义,可自行查看。元组长度代表了整个元组的长度大小。到了这里,基本的Header信息已经解析完毕,下面解析具体的tuple信息,首先我们找到00001fc0的地址:
00001fc0: 0300 0000 0000 0000 0000 0000 0000 0000 ................
00001fd0: 0100 0300 0208 1800 3123 0000 2b78 6961 ........1#..+xia
00001fe0: 6f6d 696e 6731 2020 2020 2020 2020 2020 oming1
00001ff0: 2000 0000 0000 0000 6400 0000 0000 0000 .......d.......
来看一下具体的结构,如图:
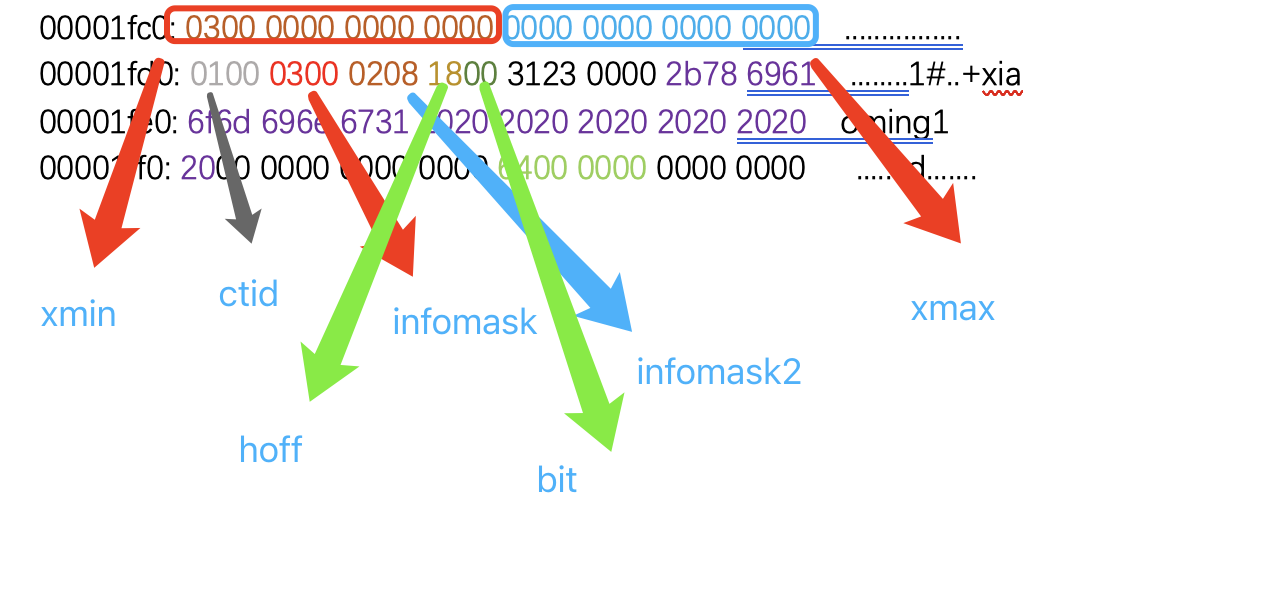
这里可以看到,总长度正好是64,也就能对应上pd_linp中15位的信息,也就是1000000
具体的数据从3123 0000这里开始,对应了ID的值
varchar类型需要注意一下,如果小于127byte,会用varattrib_1b结构存储,具体的规则会用另一篇文章具体讲述,varattrib_1b的存储规则如下:
| tag | length |
|---|---|
| 1 bit | 7 bit |
那2b转换成二进制的话,就是0010 1011,低一位存储tag,也就是1,长度保存在高7位,也就是10 101,转换十进制是21,这21里包含了标志位本身,完整的长度内容:
2b78 6961 6f6d 696e 6731 2020 2020 2020 2020 2020 20
转换完varchar,那剩下最后的6400 0000,就是数值类型,十进制就是100了
结语
了解磐维的底层存储结构,有利于帮助DBA了解数据类型是如何存储的,加深对磐维数据库的深层次的了解。有时间的话,会开一个MySQL系列的数据类型解析,解析各个数据类型是如何用16进制存储,以及如何转换为可以显示的内容。这篇就到这里吧。
最后附上我自己写的解析工具,可以直接从数据文件中解析出明文,用作数据还原、研究等,欢迎使用。
Github: pg_snapdump
Gitee: pg_snapdump
