




本文主要介绍了实际项目中对数据一致性的几种设计方案。
设计背景
数据一致性定义
数据不一致实际产生原因
无并发线程时数据不一致产生原因及解决方案
有并发线程时数据不一致产生原因及解决方案
总结
设计背景
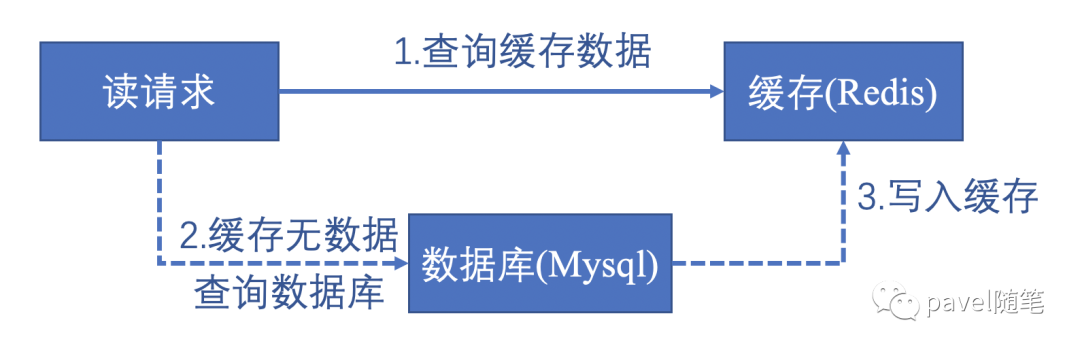
请求在读取数据时,会先读取缓存数据(加快请求查询速度),如果缓存无数据则请求查询mysql,再将值写入缓存中,方便后续请求查询。其中系统缓存一般分为以下两种:
只读缓存(新增数据时,直接写入数据库;更新(修改/删除)数据时,先删除缓存)
读写缓存(增删改在缓存中进行,并采取相应的回写策略,同步数据到数据库中)
本文解决了只读缓存(更新数据库 与 删除缓存 )数据一致设计方案,读写缓存的方案将在下一篇文章提及。
数据一致定义
可以发现,对系统数据读写必然涉及到Mysql(数据库)和Redis(缓存)两种。本文提到的数据一致性主要指:Redis中值 = Mysql中值。实际包含两种:
Redis含该数据,则 Redis中值 = Mysql中值 即可。
Redis不含该数据,Mysql值为执行写操作后的新数据。(此时,请求会查询Mysql,会将数据写入Redis,变为1的状态)
一致性的强度也分为以下几种:
强一致性:要求系统写入什么,读出来的也会是什么,用户体验好,但实现起来往往对系统的性能影响大。
弱一致性:系统在写入成功后,不承诺立即可以读到写入的值,也不承诺多久之后数据能够达到一致,但会尽可能地保证到某个时间级别(比如秒级别)后,数据能够达到一致状态。
最终一致性:最终一致性是弱一致性的一个特例,系统会保证在一定时间内,能够达到一个数据一致的状态。这里之所以将最终一致性单独提出来,是因为它是弱一致性中非常推崇的一种一致性模型,也是业界在大型分布式系统的数据一致性上比较推崇的模型。
涉及的缓存名词解释
缓存穿透,查询一个不存在的数据,不能命中缓存,导致每次请求都要到Mysql去查询,可能导致数据库崩溃。
解决方法:1.查询返回的数据为空,仍把这个空结果进行缓存,但过期时间会比较短;2.布隆过滤器:将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被这个bitmap拦截掉,从而避免了对Mysql的查询。
缓存雪崩,设置缓存时采用了相同的过期时间,缓存在某一时刻同时失效,导致大量请求访问数据库。与缓存击穿的区别:雪崩是多key,击穿是单key缓存。
解决方法:1.使用互斥锁:当缓存失效时,先使用如Redis的setnx去设置一个互斥锁,当操作成功返回时再进行数据库操作并回设缓存,否则重试get缓存的方法;2.永远不过期:物理不过期,但逻辑过期(后台异步线程去刷新)。
缓存击穿,对于设置了过期时间的key,缓存在某个时间点过期的时候,恰好有大量对这个key的并发请求,可能导致大量并发的请求瞬间把数据库压垮。
解决方法:1.分散缓存失效时间:在原有的失效时间基础上增加一个随机值;2. 使用互斥锁,当缓存数据失效时,保证只有一个请求能够访问到数据库,并更新缓存,其他线程等待并重试。
数据不一致实际产生原因
实际系统请求可分为新增数据和更新数据两种操作,具体情况复原如下:
新增数据操作。
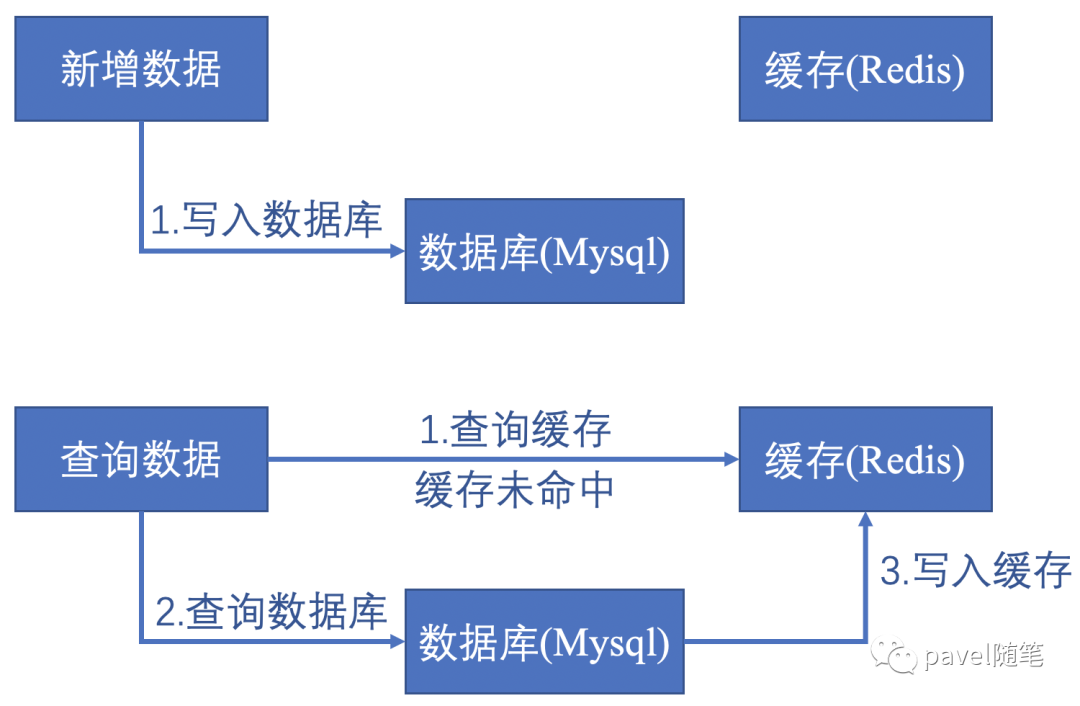
查询数据时,缓存必然无新增数据,只能从数据库查询,再写入缓存(此时数据始终一致)。
更新(删除/修改)数据,更新数据库与删除缓存两命令先后顺序会导致数据不一致。
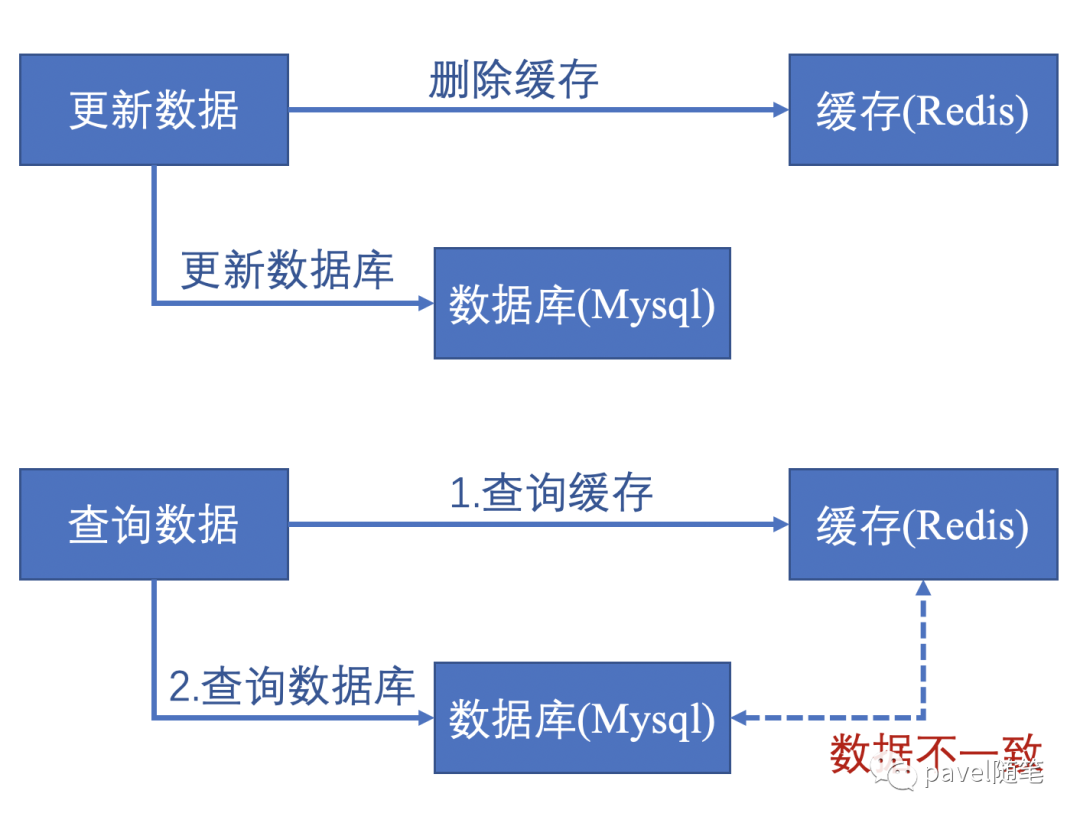
可以看到,更新数据时必会形成数据不一致:
无并发时,更新数据库与删除缓存两命令其中一个失败会使数据不一致;
有并发时,一些线程可能读取到未删除前的缓存,数据不一致;
无并发线程时数据不一致产生原因
先更新数据库,再删除缓存
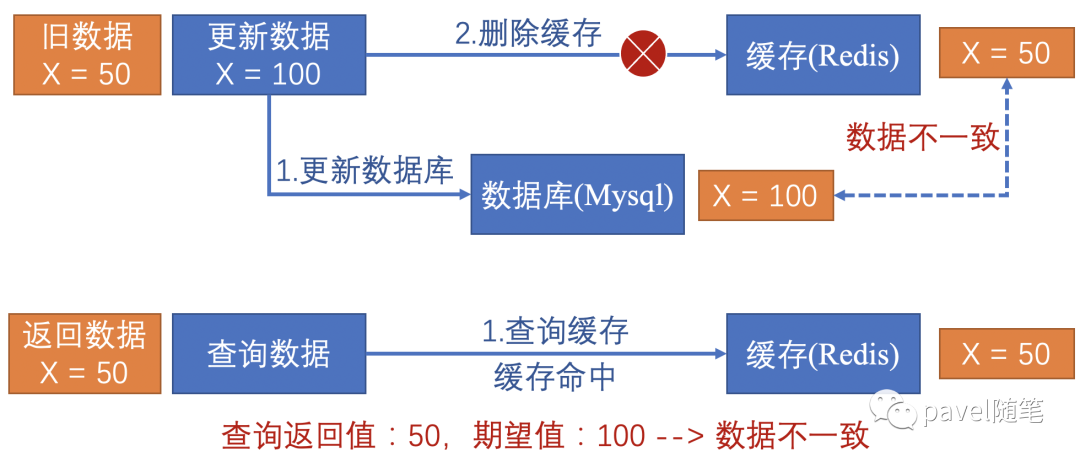
先删除缓存,再更新数据库
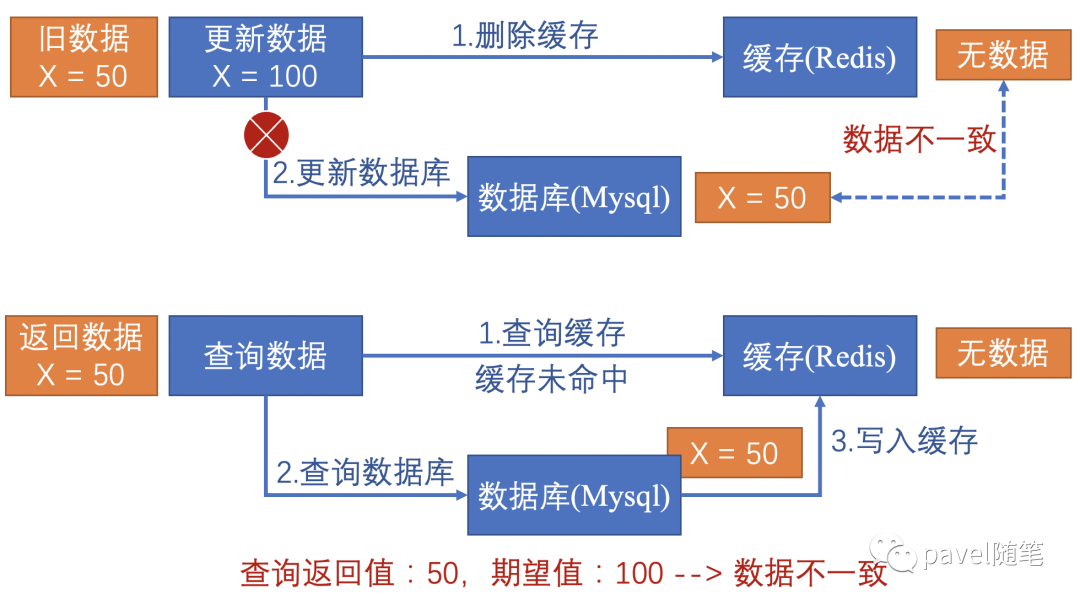
无并发时,在更新数据库和删除缓存值的过程中,因为两个命令不具有原子性,存在“命令1成功,命令2失败” 的情况发生(由于单线程中命令1和命令2是串行执行的,几乎不会发生 “命令2成功,命令1失败” ),形成数据不一致。
解决方法
利用消息队列 和 异步重试机制
两个命令不论先后次序,当执行命令2失败时,将命令2的具体参数写入消息队列,异步重试执行操作,对命令2进行 “补偿”。需注意应设置重试最大次数Max,重试Max后如依旧没成功,应发送微信报警通知。
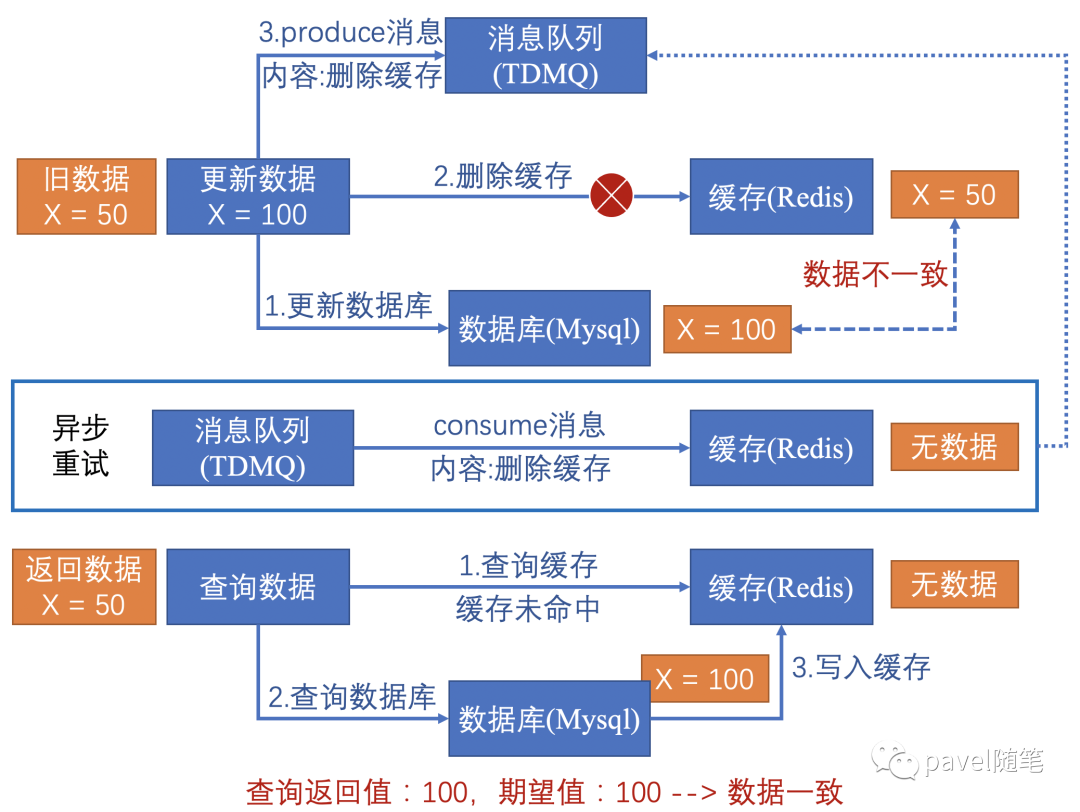
订阅Binlog变更日志(没用过。。。)
使用 Binlog 实时更新缓存。利用Canal,将负责更新缓存的服务伪装成一个 MySQL 的从节点,从 MySQL 接收 Binlog,解析 Binlog 之后,得到实时的数据变更信息,然后根据实时信息去更新缓存;
MQ+Canal策略,将Canal Server接收到的Binlog数据生产MQ,使用MQ异步消费Binlog日志,以此进行数据同步。
异步更新缓存方法对整个更新服务的数据可靠性和实时性要求都比较高,如果产生数据丢失或者更新延时情况,会造成MySQL和Redis 中的数据不一致。因此,使用这种策略时,需要考虑出现不同步问题时的降级或补偿方案。
有并发线程时数据不一致产生原因
在高并发的情况下,会发生读请求(后时序)快于写请求先返回,查询缓存得到旧数据,形成数据不一致情况。
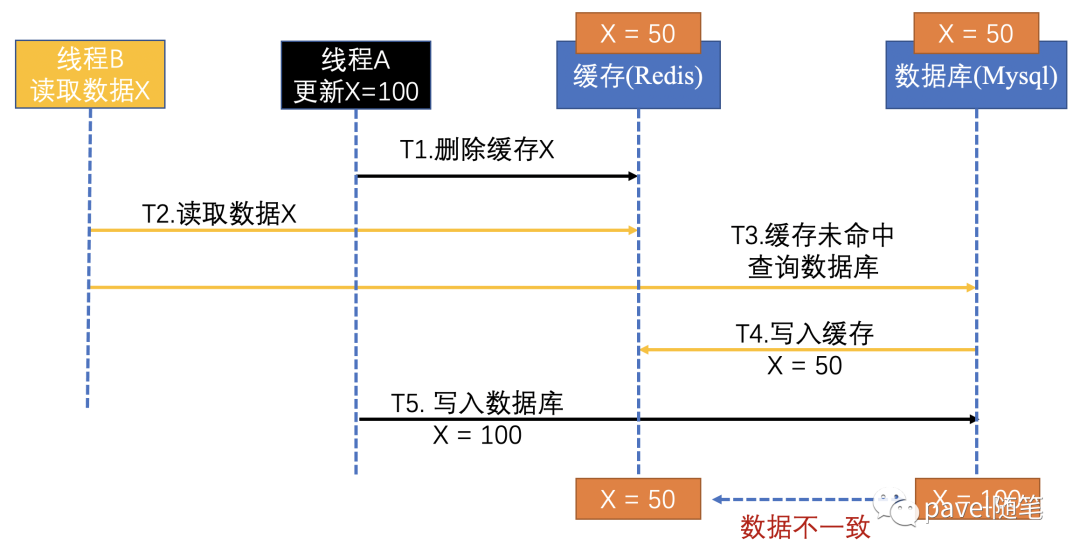
先删除缓存,再更新数据
线程 A 更新数据,线程 B 读取数据。当A与B线程的时序图如以下两种情况时,则缓存中数据为旧值,数据库中存储新值,形成了数据不一致。
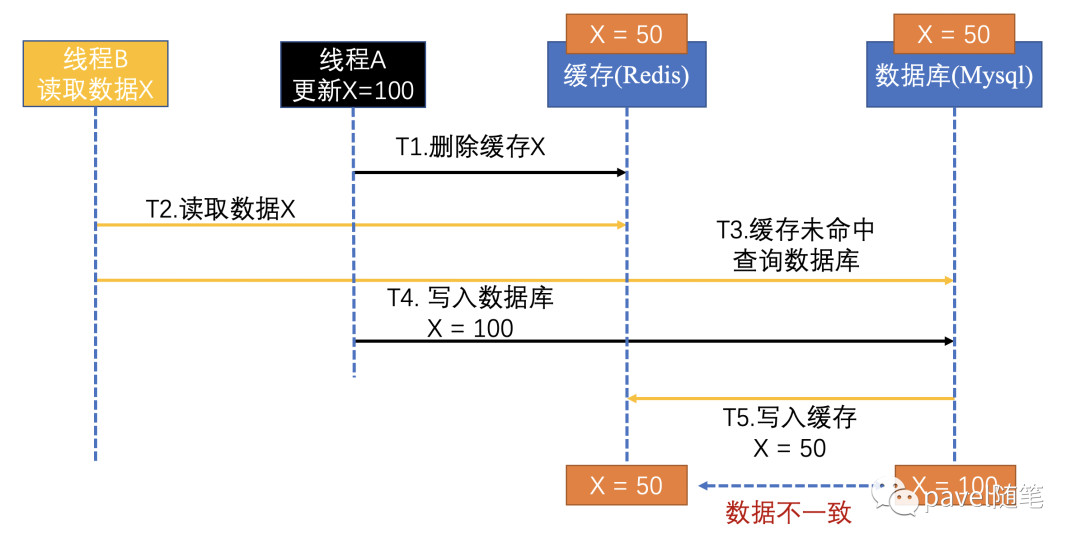
或者线程A和线程B的时序为:
解决方法
设置缓存过期时间 与 延时双删
在发生上述情况时,如设置了缓存过期时间,则缓存过期后,读请求仍可从Mysql中读取到最新数据并更新缓存,减小了数据不一致的影响范围。虽然在一定时间范围内数据有差异,确保证了数据的最终一致性。
同时设置延时双删,在线程 A 更新完数据库值后,可先sleep时间T(确保线程 B 能够先从数据库读取数据,再把缺失的数据写入缓存的总时间)或用延时队列来实现。然后,线程 A 再进行删除。则其它线程再读取数据时,缓存缺失,从数据库中读取最新值。具体时序图如下:
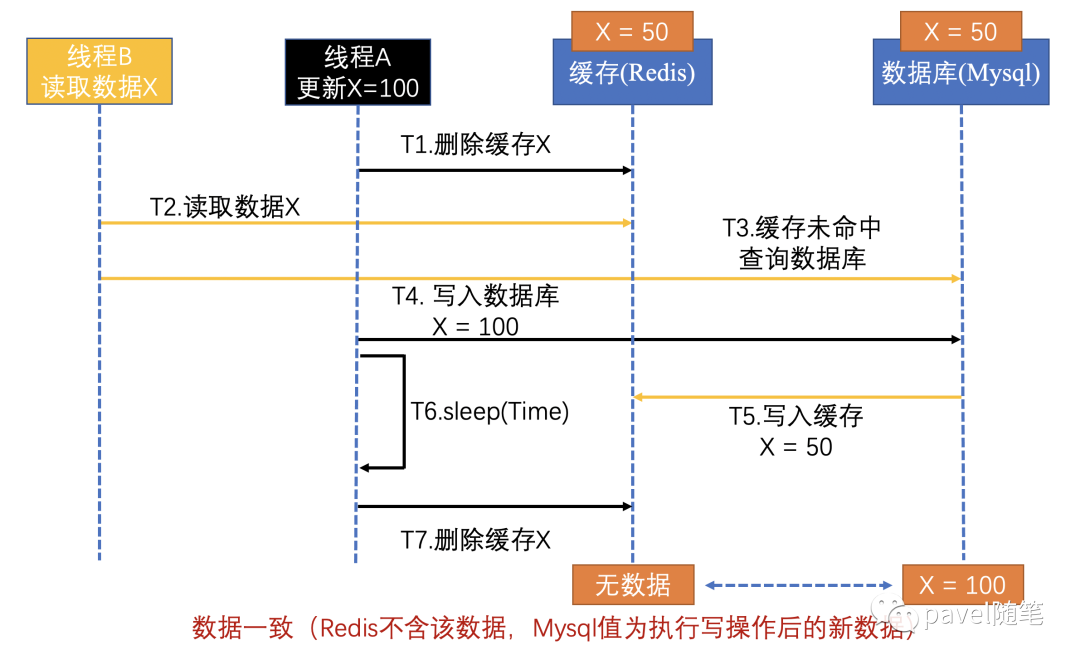
需注意:先删除缓存值再更新数据库,可能导致请求因缓存缺失而访问数据库,给数据库带来压力,也就是缓存穿透的问题。针对缓存穿透问题,一般用缓存空结果、布隆过滤器来解决。
先更新数据库,再删除缓存
线程 A 更新数据库的值后,还没删除缓存值,线程B已开始读取数据了,则线程B会直接查询缓存,缓存命中,就会读取到旧值。其本质也是,本应后发生的“B线程-读请求” 先于 “A线程-删除缓存” 执行并返回了。
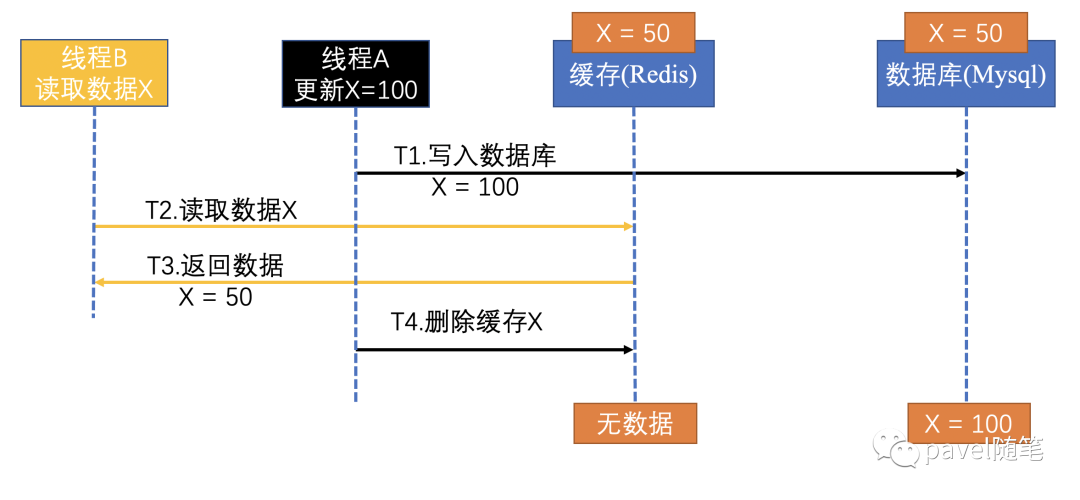
或者,使用”先更新数据库,再删除缓存”方案,“读写分离 + 主从库延迟”也会导致不一致:
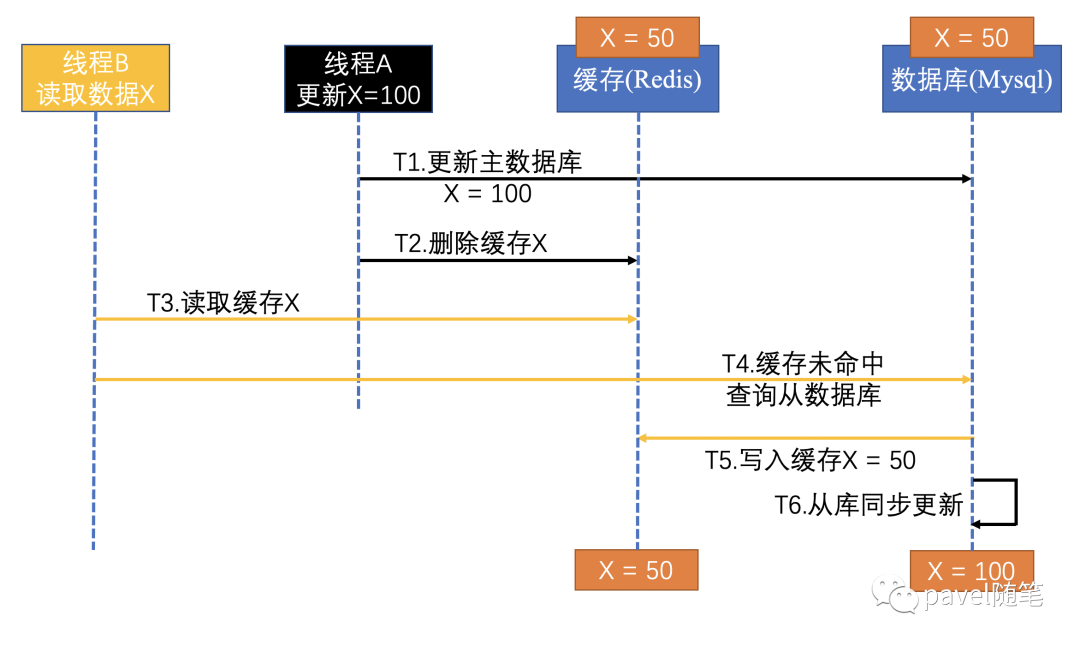
解决方法设计
延迟消息
发送「删除缓存消息」到队列中,延迟删除缓存,同时也要控制主从库延迟,尽可能降低不一致发生的概率。(延迟时间不好把控)
订阅binlog,异步删除
通过数据库的binlog来异步淘汰key,利用工具(canal)将binlog日志采集发送到MQ中,然后通过ACK机制确认处理删除缓存。
锁机制
更新数据时,加写锁;查询数据时,加读锁保证两步操作的“原子性”,使得操作可以串行执行。
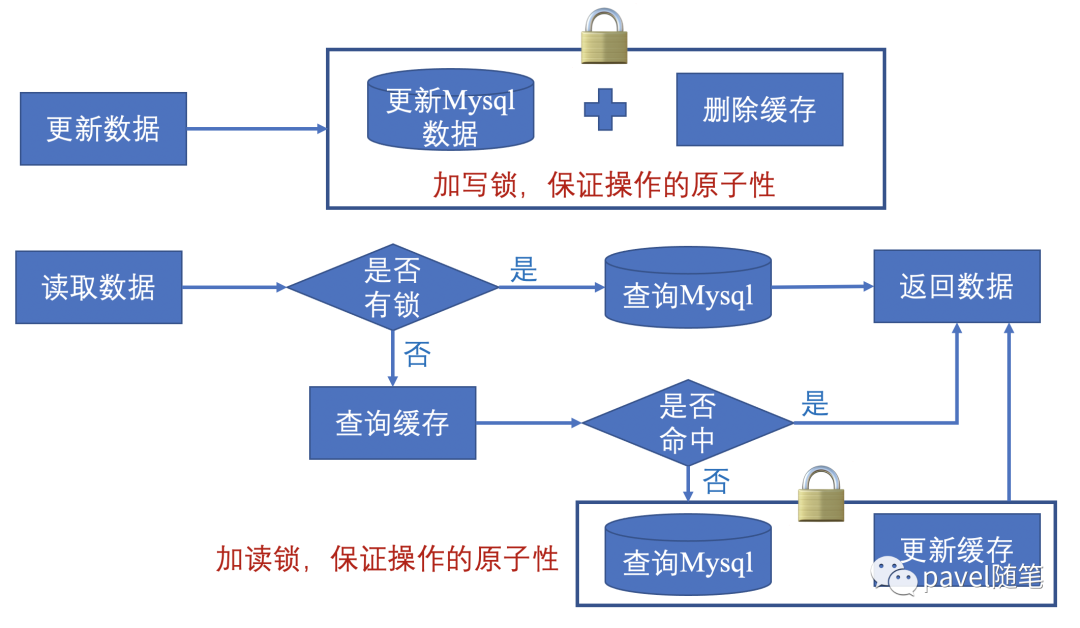
结论
实际应该优先使用“先更新数据库再删除缓存”的执行时序,原因主要为:
先删除缓存值再更新数据库,有可能导致请求因缓存缺失而访问数据库,给数据库带来压力(缓存穿透);
设计业务的读取数据库和写缓存的时间无法估计,将导致延迟双删中的sleep时间设置困难。
