




SQL Performance Analyzer 简称 SPA
1.1 SPA介绍
SQL 性能分析(SPA)通过自动化识别和评估每个业务 SQL 语句变更前后的性能差异所产生的总体影响,并提供一份 SQL 整体性能评估报告,该报告显示了由于语句更改所带来的影响。对于会使性能变差的 SQL 语句,SPA 提供了执行计划详细信息及调整建议,以帮助我们提前纠正任何可能的负面结果,从而使变更对数据库 SQL 的负面影响降到最低。
我们可以通过 SQL 性能分析工具分析各种类型的数据库更改对 SQL 性能产生的影响,这里主要包括以下几大类。
- 1)数据库升级。
- 2)PDB 级别整合或用户层面整合。
- 3)操作系统或硬件的配置变更。
- 4)数据库层参数调整。
- 5)统计信息更新。
- 6)SQL 优化验证。
1.2 SPA 工作流程
SQL 性能分析的主要工作流程具体如下。
1)目标环境搭建。
2)根据业务周期捕获生产端需要分析的 SQL,并将其存储在 SQL 调优集(SQL Tunning Set,STS)中。
3)将生产捕获到的 SQL 调优集打包传输到测试环境并导入。
4)在测试环境上创建 SQL 性能分析任务。
5)执行 SQL 调优集中的 SQL 语句,生成变更前的 SQL 执行信息。
6)执行系统变更(升级、迁移等)。
7)重新执行 SQL 调优集中的 SQ L语句,生成变更后的 SQL 执行信息。
8)比较和分析变更前后对 SQL 性能的影响,并生成整体的 SQL 性能评估报告。
9)调优性能下降的 SQL 语句。
10)重复执行步骤 6 到 8,直到达到预期的 SQL 性能目标。
1.3 SPA对生产库的影响
捕获 SQL 工作负载对生产系统的性能影响可以忽略不计,并且不应影响吞吐量。包含更多 SQL 语句的 SQL 工作负载将更好地代表应用程序或数据库的状态。这将使 SQL 性能分析器能够更准确地预测系统更改对 SQL 工作负载的潜在影响。因此,您应该捕获尽可能多的 SQL 语句。理想情况下,您应该捕获由应用程序调用或在数据库上运行的所有 SQL 语句。
您可以将捕获的 SQL 语句存储在 SQL 调优集中,并将其用作 SQL 性能分析器的输入源。SQL 调优集是一个数据库对象,包括一个或多个 SQL 语句,以及它们的执行统计信息和执行上下文。SQL 语句可以从不同的源加载到 SQL 调优集中,包括游标缓存、自动工作负载存储库 (AWR)、SQL 跟踪文件和现有的 SQL 调优集。使用 SQL 调优集捕获 SQL 工作负载使您能够:
- 将 SQL 文本和任何必要的辅助信息存储在单个持久数据库对象中
- 在 SQL 调优集中填充、更新、删除和选择捕获的 SQL 语句
- 从各种数据源加载和合并内容,例如自动工作负载存储库 (AWR) 或游标缓存
- 从捕获 SQL 工作负载的系统导出 SQL 调优集并将其导入另一个系统
- 重用 SQL 工作负载作为其他顾问的输入源,例如 SQL Tuning Advisor 和 SQL Access Advisor
SPA 实战演练
建议在要升级的原生产环境创建 SPA 专用用户
2.1 生产端和测试端:创建 SPA 用户
set linesize 240
col profile for a20
set pages 999
col username for a25
col ACCOUNT_STATUS for a18
select USERNAME,ACCOUNT_STATUS,CREATED,PROFILE,PASSWORD_VERSIONS,DEFAULT_TABLESPACE from dba_users where account_status='OPEN' order by CREATED asc;

CREATE USER spauser IDENTIFIED BY oracle;
GRANT CONNECT,RESOURCE,DBA TO spauser;
GRANT ADVISOR TO spauser;
GRANT SELECT ANY DICTIONARY TO spauser;
GRANT ADMINISTER SQL TUNING SET TO spauser;
2.2 生产端:创建SQL 调优集
conn spauser/oracle
--可删除以前的或者测试的 SQL 调优集,第一次执行不需要这一步
begin
dbms_sqltune.drop_sqlset(SQLSET_NAME => 'SPA_STS',
SQLSET_OWNER => 'SPAUSER');
end;
/
begin
DBMS_SQLTUNE.CREATE_SQLSET(SQLSET_NAME => 'SPA_STS',
DESCRIPTION => 'SQL Set Create at : '||TO_CHAR(SYSDATE, 'YYYY-MM-DD HH24:MI:SS'),
SQLSET_OWNER => 'SPAUSER');
end;
/
-- SQLSET_OWNER:指定进行SQL性能分析的用户
-- SQLSET_NAME:自定义SQL调优集的名称
确认SQL调优集信息,命令如下:
select owner, name, STATEMENT_COUNT from dba_sqlset;

set linesize 1000
COLUMN NAME FORMAT a20
COLUMN COUNT FORMAT 99999
COLUMN DESCRIPTION FORMAT a50
SELECT NAME, STATEMENT_COUNT AS "SQLCNT", DESCRIPTION FROM USER_SQLSET;

2.3 生产端:获取业务周期AWR快照点
select min(snap_id) min_id, max(snap_id) max_id
from dba_hist_snapshot
where end_interval_time between
to_date('2024-11-22 16:30', 'yyyy-mm-dd hh24:mi') and
to_date('2024-11-22 17:00', 'yyyy-mm-dd hh24:mi')
order by 1;
MIN_ID MAX_ID
---------- ----------
1728 1729
2.4 生产端:SQL调优集加载数据
通过 AWR 报告中的 SQL 语句导入 SQL 调优集进行整体的 SQL 性能测试,命令如下:
DECLARE
SQLSET_CUR DBMS_SQLTUNE.SQLSET_CURSOR;
BEGIN
OPEN SQLSET_CUR FOR
SELECT VALUE(P)
FROM TABLE(DBMS_SQLTUNE.SELECT_WORKLOAD_REPOSITORY(&begin_snap,
&end_snap,
'PARSING_SCHEMA_NAME NOT IN (''SYS'', ''SYSTEM'')',
NULL,
NULL,
NULL,
NULL,
1,
NULL,
'ALL')) P;
DBMS_SQLTUNE.LOAD_SQLSET(SQLSET_NAME => 'SPA_STS',
SQLSET_OWNER => 'SPAUSER',
POPULATE_CURSOR => SQLSET_CUR,
LOAD_OPTION => 'MERGE',
UPDATE_OPTION => 'ACCUMULATE');
CLOSE SQLSET_CUR;
OPEN SQLSET_CUR FOR
SELECT VALUE(P)
FROM TABLE(DBMS_SQLTUNE.SELECT_CURSOR_CACHE('PARSING_SCHEMA_NAME NOT IN (''SYS'', ''SYSTEM'')',
NULL,
NULL,
NULL,
NULL,
1,
NULL,
'ALL')) P;
DBMS_SQLTUNE.LOAD_SQLSET(SQLSET_NAME => 'SPA_STS',
SQLSET_OWNER => 'SPAUSER',
POPULATE_CURSOR => SQLSET_CUR,
LOAD_OPTION => 'MERGE',
UPDATE_OPTION => 'ACCUMULATE');
CLOSE SQLSET_CUR;
END;
/

2.5 生产端:查询SQL调优集
--需要登录SPAUSER用户操作,否则查不到记录
set line 567 pages 9999 long 9999
COLUMN SQL_TEXT FORMAT a120
COLUMN SCH FORMAT a15
COLUMN ELAPSED FORMAT 999999999
SELECT SQL_ID,
PARSING_SCHEMA_NAME AS "SCH",
SQL_TEXT,
ELAPSED_TIME AS "ELAPSED",
BUFFER_GETS
FROM TABLE(DBMS_SQLTUNE.SELECT_SQLSET('SPA_STS'));

--parsing_schema_name 用户名
--elapsed_time 此 SQL 语句所用总秒数的总和
--buffer_gets 此 SQL 语句的缓冲区获取总数(数据库访问块的次数)
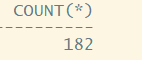
SELECT count(*) FROM TABLE(DBMS_SQLTUNE.SELECT_SQLSET('SPA_STS'));
2.6 生产端:打包SQL Set
--使用该 CREATE_STGTAB_SQLSET 过程创建一个临时表,以保留导出的 SQL 调整集(注意大小写)
BEGIN
DBMS_SQLTUNE.CREATE_STGTAB_SQLSET(table_name => 'T_11G_STAGING_TABLE',
schema_name => 'SPAUSER',
db_version=> DBMS_SQLTUNE.STS_STGTAB_11_2_VERSION);
END;
/
--使用该 PACK_STGTAB_SQLSET 过程用 SQL 调整集填充中转表(注意大小写)。
BEGIN
DBMS_SQLTUNE.PACK_STGTAB_SQLSET(sqlset_name => 'SPA_STS',
sqlset_owner => 'SPAUSER',
staging_table_name => 'T_11G_STAGING_TABLE',
staging_schema_owner => 'SPAUSER',
db_version => DBMS_SQLTUNE.STS_STGTAB_11_2_VERSION);
END;
/
2.7 导出临时表到目标库
expdp spauser/oracle directory=bak dumpfile=sts_20241122.dmp logfile=sts_20241122.log tables=T_11G_STAGING_TABLE

impdp spauser/oracle directory=bak dumpfile=sts_20241122.dmp logfile=sts_imp_20241122.log full=y

2.8 测试端:解包 SQL Set
BEGIN
DBMS_SQLTUNE.UNPACK_STGTAB_SQLSET ( SQLSET_NAME => 'SPA_STS',
SQLSET_OWNER => 'SPAUSER',
REPLACE => TRUE,
STAGING_TABLE_NAME => 'T_11G_STAGING_TABLE',
STAGING_SCHEMA_OWNER => 'SPAUSER');
end;
/
2.9 测试端:创建SPA分析任务
VARIABLE t_name VARCHAR2(100);
EXEC :t_name := DBMS_SQLPA.CREATE_ANALYSIS_TASK(sqlset_name => 'SPA_STS',task_name => 'SPA_TEST', SQLSET_OWNER => 'SPAUSER');
--sqlset_name:指定之前创建的 SQL 调优集的名称。
--task_name:自定义 SQL 性能分析任务的名称。
--SQLSET_OWNER:指定 SPA 用户
2.10测试端:前期性能
在测试服务器中,可以直接从SQL Tuning Set中转化得到所有SQL在11g数据库中的执行效率,得到11g中的SQL Trail。
begin
DBMS_SQLPA.EXECUTE_ANALYSIS_TASK(TASK_NAME => 'SPA_TEST',
EXECUTION_NAME => 'EXEC_BEFORE_UPGRADE11',
EXECUTION_TYPE => 'CONVERT SQLSET');
end;
/
execution_type 通过以下方式之一设置参数:
1>设置为 "EXPLAIN PLAN" 为 SQL 调优集中的所有 SQL 语句生成执行计划而不执行它们。
2>设置为 "TEST EXECUTE"以执行 SQL 调优集中的所有语句并生成它们的执行计划和统计信息。指定时 TEST EXECUTE,过程生成执行计划和执行统计信息。执行统计信息使 SQL 性能分析器能够识别已改进或退化的 SQL 语句。除了生成执行计划之外,收集执行统计信息可以提高性能分析的准确性,但需要更长的时间。
3>设置为 "CONVERT SQLSET" 引用 SQL 试验的执行统计信息和计划的 SQL 调整集。
2.11测试端:后期性能
在测试服务器(运行19c数据库)中,需要在本地数据库(19c)测试运行SQL Tuning Set中的SQL语句,分析所有语句在19c环境中的执行效率,得到19c中的SQL Trail。
begin
DBMS_SQLPA.EXECUTE_ANALYSIS_TASK(TASK_NAME => 'SPA_TEST',
EXECUTION_NAME => 'EXEC_AFTER_UPGRADE19',
EXECUTION_TYPE => 'TEST EXECUTE');
end;
/
注意这一步耗时较长,建议放后台执行,需要将以上捕获的 SQL 跑一遍,过程中可看到单核 CPU 100%。可用以下 SQL 查看预估时长及进度。
select INST_ID,SID,SERIAL#,OPNAME,TARGET,TARGET_DESC,
SOFAR,
TOTALWORK,
UNITS,
START_TIME,
LAST_UPDATE_TIME,
ELAPSED_SECONDS,
SQL_ID
from gv$session_longops
Where SOFAR <> TOTALWORK
and sid = XXX;
2.12测试端:性能对比
得到升级前后 SQL 执行的信息之后,就可以对比升级它们的执行性能了,下面从不同的维度(SQL 执行的时间、SQL 执行的 CPU 时间、SQL 执行的物理读、逻辑读等)进行对比分析
对比升级前后 SQL 执行的时间,命令如下:
1)对比两次跟踪中的SQL执行时间
begin
DBMS_SQLPA.EXECUTE_ANALYSIS_TASK(task_name => 'SPA_TEST',
execution_type => 'COMPARE PERFORMANCE',
execution_name => 'Compare_elapsed_time',
execution_params => dbms_advisor.arglist
('execution_name1',
'EXEC_BEFORE_UPGRADE11',
'execution_name2',
'EXEC_AFTER_UPGRADE19',
'comparison_metric',
'elapsed_time'));
end;
/
2)对比两次跟踪中的SQL执行的CPU时间
begin
DBMS_SQLPA.EXECUTE_ANALYSIS_TASK(task_name => 'SPA_TEST',
execution_type => 'COMPARE PERFORMANCE',
execution_name => 'Compare_CPU_time',
execution_params => dbms_advisor.arglist
('execution_name1',
'EXEC_BEFORE_UPGRADE11',
'execution_name2',
'EXEC_AFTER_UPGRADE19',
'comparison_metric',
'CPU_TIME'));
end;
/
3)对比升级前后 SQL 执行的逻辑读,命令如下:
begin
DBMS_SQLPA.EXECUTE_ANALYSIS_TASK(task_name => 'SPA_TEST',
execution_type => 'COMPARE PERFORMANCE',
execution_name => 'Compare_BUFFER_GETS',
execution_params => dbms_advisor.arglist
('execution_name1',
'EXEC_BEFORE_UPGRADE11',
'execution_name2',
'EXEC_AFTER_UPGRADE19',
'comparison_metric',
'BUFFER_GETS'));
end;
/
4)对比升级前后 SQL 执行的物理读,命令如下:
DBMS_SQLPA.EXECUTE_ANALYSIS_TASK(task_name => 'SPA_TEST',
execution_type => 'COMPARE PERFORMANCE',
execution_name => 'Compare_disk_reads',
execution_params => dbms_advisor.arglist
('execution_name1',
'EXEC_BEFORE_UPGRADE11',
'execution_name2',
'EXEC_AFTER_UPGRADE19',
'comparison_metric',
'DISK_READS'));
end;
/
2.13 生成报告
1>对比 SQL 的执行时间,获取全部结果
ALTER SESSION SET EVENTS '31156 trace name context forever, level 0x400';
SET LONG 9999999 longchunksize 100000 linesize 200 head off feedback off echo off
spool 11g_19c_change_1122.html
SELECT DBMS_SQLPA.REPORT_ANALYSIS_TASK('SPA_TEST',
'HTML',
'TYPICAL',
'ALL',
NULL,
100,
NULL,
NULL,
NULL)
FROM DUAL;
spool off
2>对比 SQL 的执行时间,生成对比报告:
set trimspool on
set trim on
set pages 0
set long 999999999
set linesize 1000
spool spa_report_elapsed_time_1126.html
SELECT dbms_sqlpa.report_analysis_task('SPA_TEST', 'HTML', 'ALL','ALL',
top_sql=>300,execution_name=>'Compare_elapsed_time') FROM dual;
spool off;
3>对比 SQL 执行的 CPU 时间,生成对比报告
spool spa_report_CPU_time_1126.html
SELECT dbms_sqlpa.report_analysis_task('SPA_TEST', 'HTML', 'ALL','ALL',
top_sql=>300,execution_name=>'Compare_CPU_time') FROM dual;
spool off;
4>对比 SQL 执行的逻辑读时间,生成对比报告
spool spa_report_buffer_time_1126.html
SELECT dbms_sqlpa.report_analysis_task('SPA_TEST','HTML','ALL','ALL',
top_sql=>300,execution_name=>'Compare_BUFFER_GETS') FROM dual;
spool off;
5>对比 SQL 执行的物理读时间,生成对比报告
spool spa_report_physical_time_1126.html
SELECT dbms_sqlpa.report_analysis_task('SPA_TEST','HTML','ALL','ALL',
top_sql=>300,execution_name=>'Compare_disk_reads') FROM dual;
spool off;
6>获取错误信息报告
spool spa_report_errors_1126.html
SELECT dbms_sqlpa.report_analysis_task('SPA_TEST', 'HTML', 'errors','summary')
FROM dual;
spool off;
7>获取不支持的对象报告:
spool spa_report_unsupport_1126.html
SELECT dbms_sqlpa.report_analysis_task('SPA_TEST', 'HTML', 'unsupported','all')
FROM dual;
spool off;
