




2024 CCF中国软件大会(CCF ChinaSoft)于2024年11月15日至17日在陕西省西安高新国际会议中心召开。本届大会的主题为“智能软件创新赋能新质生产力发展”。在往届大会成功举办的基础上,2024 CCF中国软件大会将组织特邀报告、院士高峰论坛、青年学者论坛、大会常设论坛、论文专刊论坛、顶会顶刊论坛、学术论坛、工业论坛、教育论坛、学科竞赛、软件研究成果展示等近50个不同类型的活动。
其中,大模型评测技术论坛备受瞩目,大模型评测是大模型研发体系中的关键一环,模型评测能够发现模型缺陷,指导模型优化方向,减少计算资源浪费,持续提升模型性能,确保大模型产品满足用户需求,推动大模型技术迭代进步。然而,现有大模型评测技术仍面临若干严峻挑战:面向大模型能力的客观评价和主观评价难以有机协同;大模型生成能力超过大多现有评测基准;因专业知识与评测专家缺乏,行业垂类大模型评测体系构建难度大;大模型评测数据集来源受限,数据管理、隐私保护存在缺陷 ……
大模型评测技术论坛拟围绕建立客观、公正、自动化的大模型评测体系展开,邀请各领域顶级专家学者从自然语言处理、软件测试、数据挖掘、数据管理等多个角度重点研讨大模型评测技术关键问题,为各领域专家协同创新、合作共享提供交流平台,助力构建更完善的大模型评测技术体系,推动大模型技术支撑千行百业持续健康发展。欢迎软件测试、软件工程、人工智能、数据科学、数据库等学科的专家和学者前来参加。
华东师范大学兰韵诗副教授带来《基于大语言模型的结构化数据管理研究》主题报告。

报告摘要:大语言模型在人工智能中扮演着重要的角色。在数据库领域,越来越多的研究人员开始聚焦于如何将大语言模型运用于下游任务,如:配置旋钮、测试样例生成和查询生成。其中查询生成(NL2DQL)作为结构化数据管理的重要任务,旨在将自然语言自动转化为数据库查询语言。其有着广泛的服务场景和应用前景。基于此,本次报告将首先介绍大语言模型用于查询生成的基本范式,进而介绍我们进行的一些探索,包括设计实现了大语言模型将自然语言转为领域内数据库查询的新框架和方法,最后分享我们在国产数据库上的应用实践。
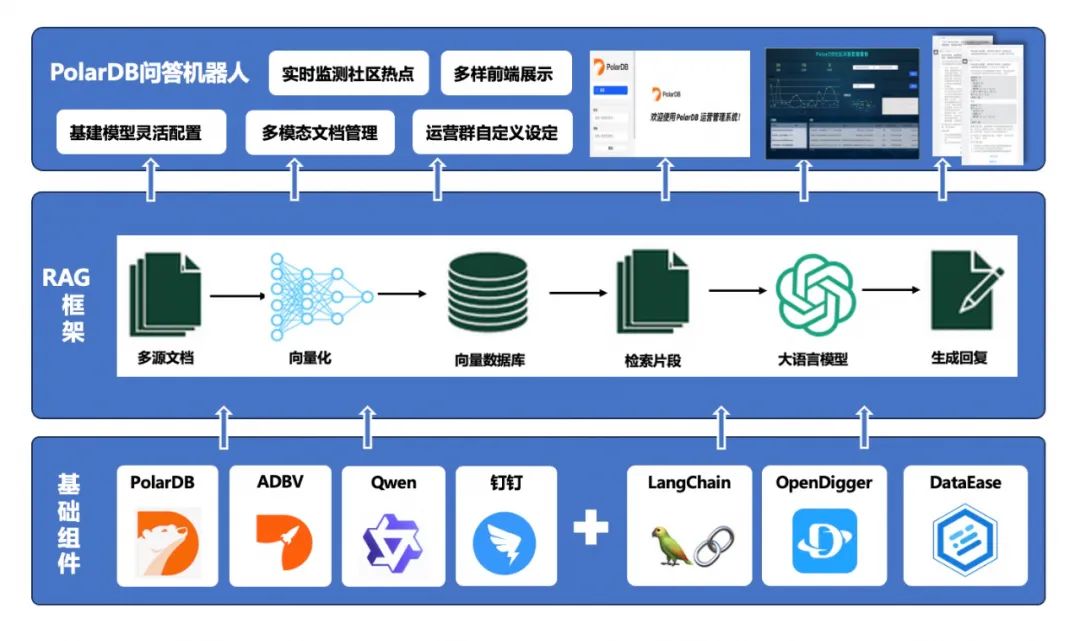
兰韵诗老师主要研究方向为自然语言处理,智能问答,大语言模型等。她的研究致力于利用语言模型解决各类场景的问答任务,提升问答效率和精度,从而减少运营成本。兰韵诗博士在机器学习和自然语言处理顶级会议上发表论文四十余篇,担任ACL、EMNLP、NeurIPS等国际会议程序委员。目前主持国家自然科学基金青年科学基金、国家区域重点项目子课题等。获得国泰君安、阿里云等资助,带领团队深度参与产学研项目,多项成果已在工业界部署上线。随着人工智能2.0时代的到来,大语言模型掀起了时代的浪潮。阿里云联合华东师范大学推出PolarDB开源社区自动问答机器人,帮助PolarDB开源社区的开发者快速检索到需要的技术细节和内容,提高业务开发与部署效率,提升社区服务体验。支持领域内内容高效查询、自定义投放场景和渠道、社区动态实时监测等功能。
PolarDB 是阿里云自研的云原生数据库产品家族,采用存储计算分离、软硬一体化设计,既拥有分布式设计的低成本优势,又具有集中式的易用性,可满足大规模应用场景需求。2021年,阿里云把数据库开源作为重要战略方向,正式开源自研核心数据库产品 PolarDB(PolarDB PostgreSQL 版和PolarDB 分布式版)。
作为行业领先的数据库产品,PolarDB提供详细的产品手册、运维文档、自媒体技术专栏以及体系化的课程等丰富的学习内容与资料,为广大开发者更好的使用PolarDB良好的支撑。为了更好的满足开发者以及企业用户的服务诉求,PolarDB提供了开源官网、阿里云开发者社区、技术交流钉群、企业专属钉群、微信交流群 、视频号等全方位的服务和交流矩阵。本项目将利用AI能力,充分挖掘PolarDB产品内容价值,为社区用户提供更高效、更精准的自助服务。
PolarDB开源社区自动问答机器人整体框架
针对“历史对话未有效利用”,“不清晰问题引起的检索困难”,“SQL开发相关问题复杂”的问题, 我们分别采取了以下解决方案: 实时收集社区问答记录,对问题进行关键词识别和聚类建模,挖掘历史问答数据价值。当社区内再次有相似的问题出现时,我们将直接检索出相似的历史已解决问题或返回高赞回复。这样的策略在提升系统的响应速率和准确性上均有一定效果。同时利用历史对话数据建模,可对模糊问题进行规范重写。
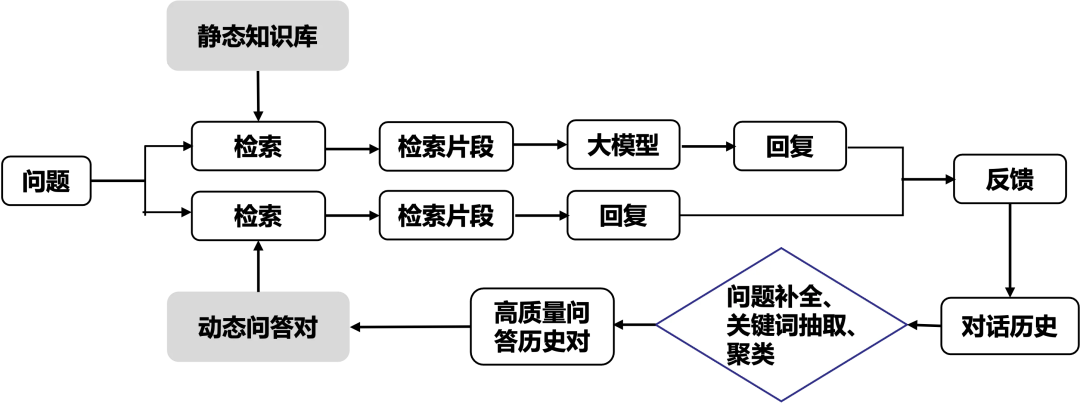
整体工作流程如下:
知识上传与存储:相关知识内容上传后,系统会自动对上传文件进行解析、切片并存储在PolarDB中; 用户提问:根据用户输入的自然语言问题,系统会通过向量数据库递归检索与用户问题最相关的PolarDB相关内容,检索的文档切片作为上下文输入提示和归纳回复; 答案输出:结合存储的历史提问上下文信息,规范重写“问题”,并生成和输出相应的答案。
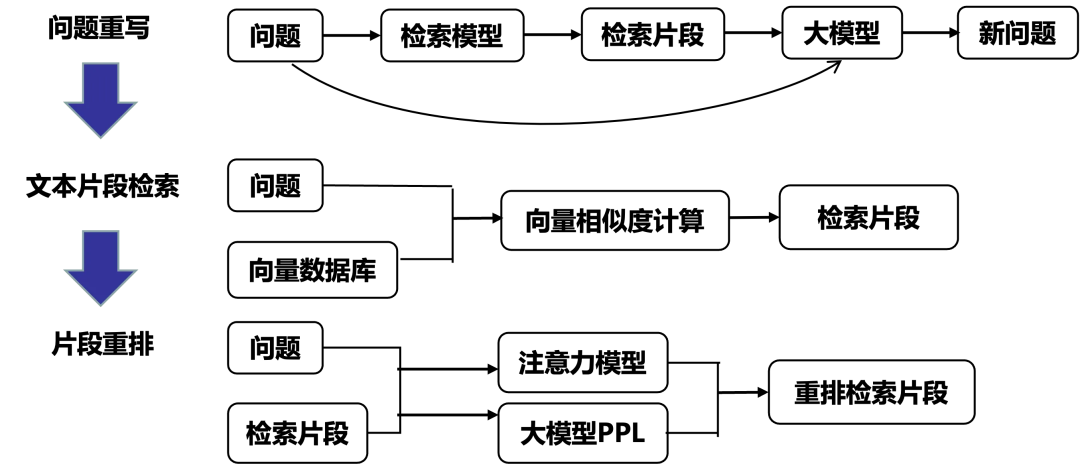
采取多种策略对问题进行重写和转述
首先,我们通过伪相关片段,其包含和问题高度相关的信息,这些信息可以帮助消除查询歧义并生成清晰的新问题。 接着,我们利用低维稠密向量来表示问题,使得这个向量能够表达问题语义,通过计算向量的相似度反映问题与片段之间的相似性。 最后,在得到少量检索片段之后利用更加精细的排序方式,如注意力模型和使用大模型回复困惑度反向判断检索片段的精确度,得到重排之后的检索片段。
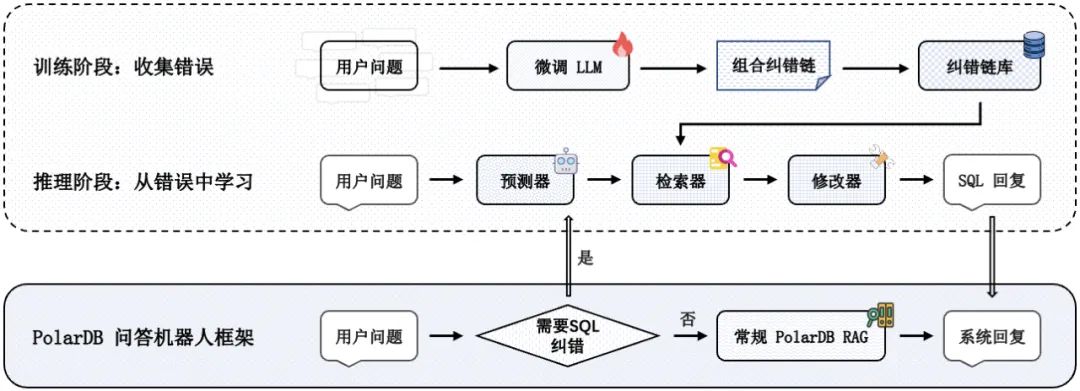
文本转SQL语句的流程中还融入语句纠错能力,对生成的SQL语句进行二次验证,使生成的SQL语句尽可能地准确和完整。这是针对数据库查询类问题的创新探索。
从错误中学习:根据纠错链修改 SQL 查询
首先,在大语言模型(Large Language Model,LLM)训练阶段,我们收集 LLM 学习过程中产生的可能错误的SQL 预测,并按照预定义的模式(用户问题-SQL预测1-SQL预测2-...-SQL正确答案)组成纠错链,存入纠错链库。 其次,在推理阶段,我们根据用户问题与 LLM 预测的 SQL 从纠错链库中检索类似的纠错示例,并请求大语言模型从中学习纠错知识,根据检索的纠错上下文修改候选 SQL 查询。 最后,为了将该 SQL 纠错方法融入 PolarDB 问答机器人框架中,大语言模型被要求判断当前的用户问题是否需要做 SQL 纠错,若需要则执行上述推理过程并将纠错后的 SQL 语句根据问题进行重写,使其回复得更加自然;否则做常规的 PolarDB RAG 问答。
点击“阅读原文”了解PolarDB V2.0
