





本文字数:11241;估计阅读时间:29 分钟
Meetup活动
ClickHouse Beijing User Group第2届 Meetup火热报名中,详见文末海报!

设计高效的模式是提升 ClickHouse 性能的关键,这需要在多个选项之间做出权衡。最佳的设计方案取决于查询类型、数据更新频率、延迟需求和数据量等因素。本指南将介绍一些模式设计的最佳实践和数据建模技巧,帮助您优化 ClickHouse 的性能。

本指南中的示例基于 Stack Overflow 数据集的一个子集。这些数据记录了从 2008 年到 2024 年 4 月间,Stack Overflow 上的每篇帖子、每次投票、每位用户、每条评论以及每个徽章。这些数据以 Parquet 格式存储,您可以通过以下 S3 存储桶获取:s3://datasets-documentation/stackoverflow/parquet/。
数据集中的主键和表间关系仅用于说明数据的关联和唯一性,并未通过约束强制执行(因为 Parquet 是文件格式,而不是数据库表格式)。
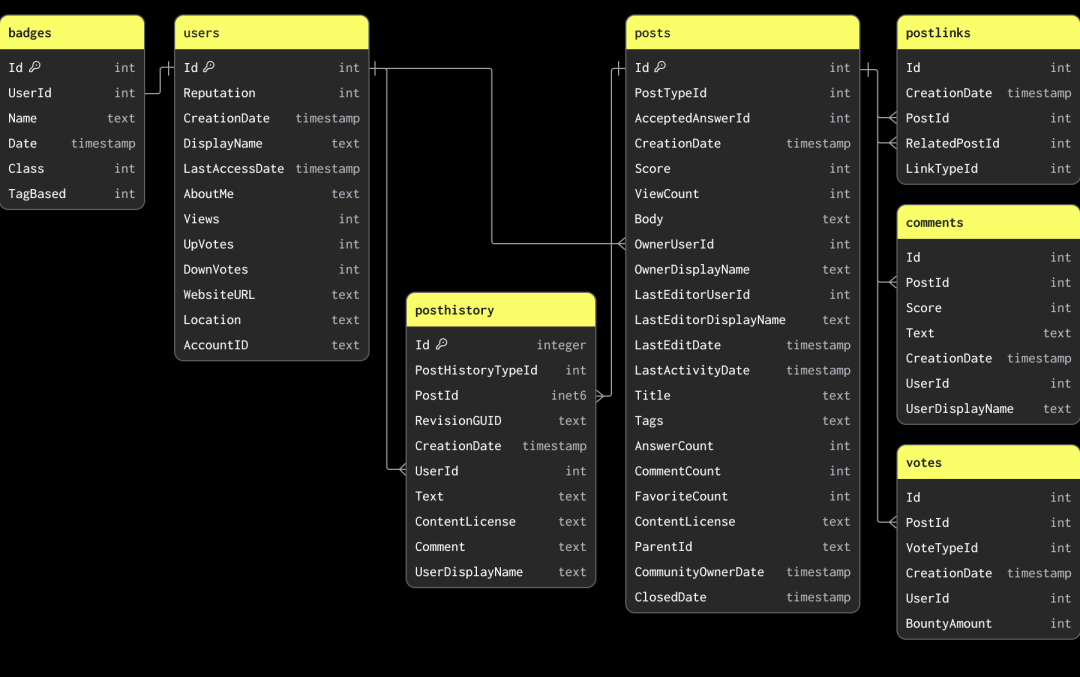
Stack Overflow 数据集包含多个相关表。在数据建模时,我们建议先加载主表。主表不一定是数据量最大的表,而是您预期大多数分析查询会针对的表。这样可以帮助您熟悉 ClickHouse 的核心概念和数据类型,尤其是如果您此前以 OLTP 数据库为主。这张主表可能会在添加更多表时重新建模,以便充分利用 ClickHouse 的功能并实现最佳性能。
为了说明教学目的,本指南中的模式设计是有意简化的。
由于大部分分析查询都会针对 posts 表,我们将重点放在为该表定义模式。这些数据可以从公共 S3 存储桶获取:s3://datasets-documentation/stackoverflow/parquet/posts/*.parquet,其中每年数据存储在一个文件中。
从 S3 加载 Parquet 格式的数据是导入 ClickHouse 的首选方式。ClickHouse 对 Parquet 格式进行了优化,能够以每秒处理数千万行数据的速度从 S3 中读取并插入。
DESCRIBE TABLE s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/posts/*.parquet')SETTINGS describe_compact_output = 1┌─name──────────────────┬─type───────────────────────────┐│ Id │ Nullable(Int64) ││ PostTypeId │ Nullable(Int64) ││ AcceptedAnswerId │ Nullable(Int64) ││ CreationDate │ Nullable(DateTime64(3, 'UTC')) ││ Score │ Nullable(Int64) ││ ViewCount │ Nullable(Int64) ││ Body │ Nullable(String) ││ OwnerUserId │ Nullable(Int64) ││ OwnerDisplayName │ Nullable(String) ││ LastEditorUserId │ Nullable(Int64) ││ LastEditorDisplayName │ Nullable(String) ││ LastEditDate │ Nullable(DateTime64(3, 'UTC')) ││ LastActivityDate │ Nullable(DateTime64(3, 'UTC')) ││ Title │ Nullable(String) ││ Tags │ Nullable(String) ││ AnswerCount │ Nullable(Int64) ││ CommentCount │ Nullable(Int64) ││ FavoriteCount │ Nullable(Int64) ││ ContentLicense │ Nullable(String) ││ ParentId │ Nullable(String) ││ CommunityOwnedDate │ Nullable(DateTime64(3, 'UTC')) ││ ClosedDate │ Nullable(DateTime64(3, 'UTC')) │└───────────────────────┴────────────────────────────────┘
s3 表函数使 ClickHouse 能够直接查询存储在 S3 中的数据。这一功能适用于 ClickHouse 支持的所有文件格式。
CREATE TABLE postsENGINE = MergeTreeORDER BY () EMPTY ASSELECT * FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/posts/*.parquet')
几个关键点:
运行完这条命令后,我们的 posts 表还是空的,因为数据还没有加载。这里我们使用了 MergeTree 作为表引擎。MergeTree 是 ClickHouse 中最常用的表引擎,功能非常强大,可以处理 PB 级的数据,适用于大多数分析场景。而对于需要高效更新的场景,比如 CDC,则可以选择其他表引擎。
ORDER BY () 表示当前数据没有索引或排序。稍后我们会详细讲解。现在只需知道所有查询都需要执行线性扫描。
确认表已创建后:
SHOW CREATE TABLE postsCREATE TABLE posts(`Id` Nullable(Int64),`PostTypeId` Nullable(Int64),`AcceptedAnswerId` Nullable(Int64),`CreationDate` Nullable(DateTime64(3, 'UTC')),`Score` Nullable(Int64),`ViewCount` Nullable(Int64),`Body` Nullable(String),`OwnerUserId` Nullable(Int64),`OwnerDisplayName` Nullable(String),`LastEditorUserId` Nullable(Int64),`LastEditorDisplayName` Nullable(String),`LastEditDate` Nullable(DateTime64(3, 'UTC')),`LastActivityDate` Nullable(DateTime64(3, 'UTC')),`Title` Nullable(String),`Tags` Nullable(String),`AnswerCount` Nullable(Int64),`CommentCount` Nullable(Int64),`FavoriteCount` Nullable(Int64),`ContentLicense` Nullable(String),`ParentId` Nullable(String),`CommunityOwnedDate` Nullable(DateTime64(3, 'UTC')),`ClosedDate` Nullable(DateTime64(3, 'UTC')))ENGINE = MergeTree('/clickhouse/tables/{uuid}/{shard}', '{replica}')ORDER BY tuple()
在初始模式定义完成后,可以通过 INSERT INTO SELECT 命令加载数据,这里用 s3 表函数从存储桶中读取数据。在一台 8 核的 ClickHouse Cloud 实例上,大约 2 分钟就能完成 posts 数据的加载。
INSERT INTO posts SELECT * FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/posts/*.parquet')0 rows in set. Elapsed: 148.140 sec. Processed 59.82 million rows, 38.07 GB (403.80 thousand rows/s., 257.00 MB/s.)
上面的查询加载了 6000 万行数据。虽然这个数据量对 ClickHouse 来说不算大,但如果网络较慢,可以选择加载部分数据。例如,只加载特定年份的数据文件,像 https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/posts/2008.parquet 或 https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/posts/{2008,2009}.parquet。有关如何使用通配符模式筛选文件的更多信息,请参考相关文档。
提升 ClickHouse 查询性能的关键之一是数据压缩。
数据占用越小,I/O 就越少,查询和插入的速度也会更快。大多数情况下,压缩算法对 CPU 的开销要远低于减少 I/O 带来的性能提升。因此,优化数据压缩是提高 ClickHouse 性能的首要任务。
ClickHouse 为什么能实现出色的数据压缩?作为一款列式数据库,它按列顺序存储数据。如果数据是排序的,相同的值会彼此相邻,压缩算法可以充分利用这种模式。此外,ClickHouse 提供了编解码器 (codecs) 和多样化的数据类型,用户可以通过调整这些设置进一步优化压缩效果。
在优化初期,通过调整数据类型可以快速提升压缩效率和查询性能。以下是一些优化模式的简单规则:
优化数据类型的建议:
1. 使用严格类型
初始模式中,许多列被定义为字符串类型(String),但实际上应该是数值类型(Numeric)。正确的类型设置不仅能确保过滤和聚合时符合预期语义,还能提升性能。同样,日期类型应确保准确,如 Parquet 文件中已正确提供的日期字段。
2. 避免使用 Nullable 列
默认情况下,ClickHouse 会将列定义为 Nullable 类型,这意味着会额外生成一个 UInt8 类型的辅助列,用于区分空值和 Null。这会占用更多存储空间,并降低查询性能。除非必须区分默认空值和 Null,否则建议避免使用 Nullable。例如,对于 ViewCount 列,使用 0 作为空值即可满足大多数查询需求。如果需要过滤空值,可以在查询时加上过滤条件。
3. 选择数值类型时优先最小精度
ClickHouse 提供多种数值类型,可根据范围和精度选择最合适的类型。尽量减少列所需的位数,例如使用 UInt16 而不是 Int16,因为它能存储更大范围的数据(最大值为 65535)。根据需要优先选择更小的无符号类型。
4. 为日期类型选择合适的精度
ClickHouse 支持多种日期类型,例如 Date 和 Date32,后者支持更大的日期范围但需要更多存储空间。对于日期时间字段,可以选择 DateTime(秒级精度,32 位)或 DateTime64(纳秒级精度,64 位)。根据查询需求,优先选择较粗精度的类型以减少存储。
5. 使用 LowCardinality 优化低唯一值列
对于唯一值少于 1 万的列(如数字、字符串、日期),可以使用 LowCardinality 类型进行字典编码,这样能大幅减少磁盘占用空间。
6. 特定情况下使用 FixedString
对于长度固定的字符串(例如语言或货币代码),可以使用 FixedString 类型。这种类型在长度固定的数据场景下非常高效,但如果数据长度不一致,建议优先使用 LowCardinality。
7. 利用 Enum 提高效率和验证数据
Enum 类型适用于编码枚举值,可以是 8 位或 16 位。它不仅可以在插入时验证数据(拒绝未声明的值),还可以利用枚举值的自然排序,例如用户反馈列 Enum(':(' = 1, ':|' = 2, ':)' = 3)。如果需要这类功能,可以考虑使用 Enum。
提示:如果要查找所有列的值范围以及唯一值的数量,可以使用如下简单查询语句:"SELECT * APPLY min, * APPLY max, * APPLY uniq FROM table FORMAT Vertical"。建议在较小的数据子集上执行该查询,因为操作较大数据集可能会带来较高的计算成本。请注意,该查询要求数字列必须定义为数字类型,而不是 String 类型,才能保证结果的准确性。
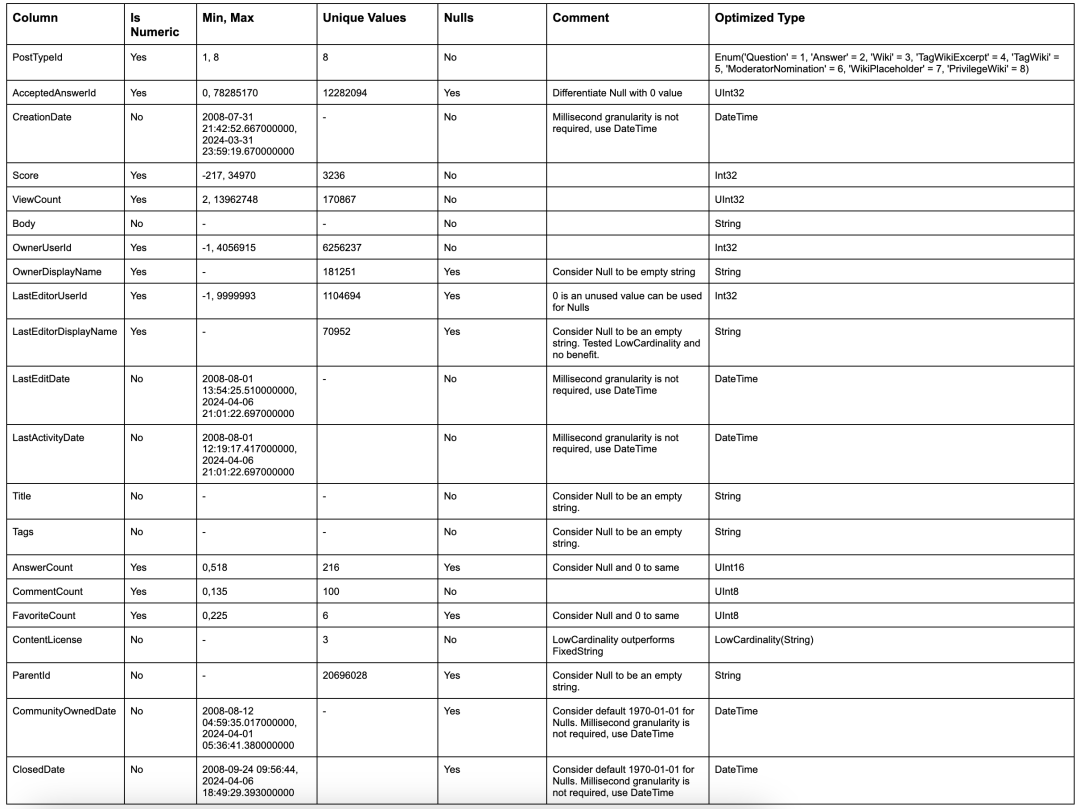
基于上述规则,我们得到了以下数据模式:
CREATE TABLE posts_v2(`Id` Int32,`PostTypeId` Enum('Question' = 1, 'Answer' = 2, 'Wiki' = 3, 'TagWikiExcerpt' = 4, 'TagWiki' = 5, 'ModeratorNomination' = 6, 'WikiPlaceholder' = 7, 'PrivilegeWiki' = 8),`AcceptedAnswerId` UInt32,`CreationDate` DateTime,`Score` Int32,`ViewCount` UInt32,`Body` String,`OwnerUserId` Int32,`OwnerDisplayName` String,`LastEditorUserId` Int32,`LastEditorDisplayName` String,`LastEditDate` DateTime,`LastActivityDate` DateTime,`Title` String,`Tags` String,`AnswerCount` UInt16,`CommentCount` UInt8,`FavoriteCount` UInt8,`ContentLicense`LowCardinality(String),`ParentId` String,`CommunityOwnedDate` DateTime,`ClosedDate` DateTime)ENGINE = MergeTreeORDER BY tuple()COMMENT 'Optimized types'
我们可以通过一条简单的 INSERT INTO SELECT 查询,将数据从之前的表读取并插入到新表中来填充这个模式:
INSERT INTO posts_v2 SELECT * FROM posts0 rows in set. Elapsed: 146.471 sec. Processed 59.82 million rows, 83.82 GB (408.40 thousand rows/s., 572.25 MB/s.)
在新模式中,所有的空值将被自动转换为对应类型的默认值。例如,整数类型的默认值为 0,字符串类型的默认值为空字符串。同时,ClickHouse 会自动将数字转换为目标精度。ClickHouse 的主键(排序键)对于习惯使用 OLTP 数据库的用户,经常会希望找到 ClickHouse 中与其等价的概念。
在 ClickHouse 通常处理的大规模数据环境中,内存和磁盘的使用效率是至关重要的。数据写入 ClickHouse 表时,以块的形式存储,这些块被称为“部分 (parts)”,并且后台会有规则对这些部分进行合并。在 ClickHouse 中,每个部分都有自己的主索引。当部分被合并时,其主索引也会一并合并。主索引使用一种称为“稀疏索引 (sparse indexing)”的技术,每组行生成一个索引条目。
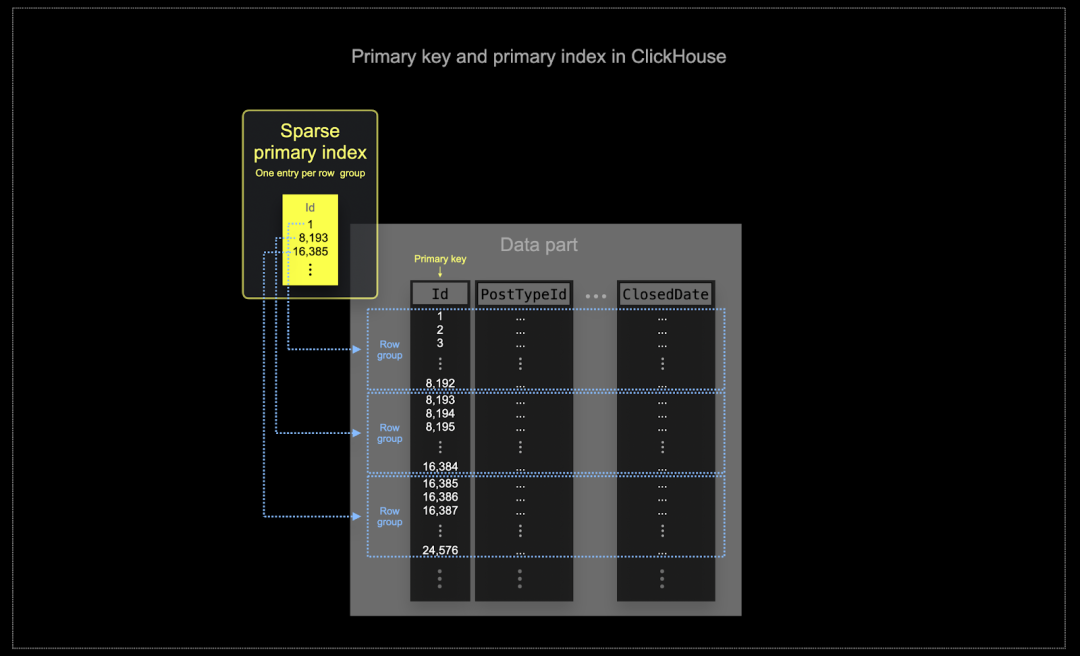
在 ClickHouse 中,选择的排序键不仅决定索引结构,还决定数据在磁盘上的存储顺序。这种存储顺序会显著影响数据的压缩效果,从而间接提高查询性能。理想的排序键应尽可能让大多数列的值按连续顺序存储,以便压缩算法和编解码器更高效地压缩数据。
无论列是否包含在排序键中,表中的所有列都会根据排序键的值进行排序。例如,如果使用 CreationDate 作为排序键,那么其他列的值顺序将与 CreationDate 列的值顺序一致。此外,排序键支持多列配置,功能类似于 SELECT 查询中的 ORDER BY 子句。
1. 优先选择常用于 WHERE 子句的列。如果某列经常出现在查询条件中,那么应优先考虑将其作为排序键的一部分。尤其是那些能显著减少需扫描数据量的列,能够有效提高查询性能。
2. 尽量选择与其他列高度相关的列。这样可以确保这些列的值存储时相邻,进一步提高数据的压缩效率。对于排序键中的列,GROUP BY 和 ORDER BY 操作也能更高效地利用内存。
为排序键选择列时,应按特定顺序声明列。列的顺序会直接影响次级键的过滤效率以及数据文件的压缩比。通常建议按照基数的升序排列列,同时权衡这一排序对查询过滤效率的影响,并根据实际访问模式进行测试和优化。
示例
我们将上述指南应用到 posts 表,假设用户需要分析数据,并按日期和帖子类型进行筛选。例如:
“过去 3 个月内,哪类问题的评论数最多?”
如果使用之前优化了数据类型但未设置排序键的 posts_v2 表执行此查询:
SELECTId,Title,CommentCountFROM posts_v2WHERE (CreationDate >= '2024-01-01') AND (PostTypeId = 'Question')ORDER BY CommentCount DESCLIMIT 3┌───────Id─┬─Title─────────────────────────────────────────────────────────────┬─CommentCount─┐│ 78203063 │ How to avoid default initialization of objects in std::vector? │ 74 ││ 78183948 │ About memory barrier │ 52 ││ 77900279 │ Speed Test for Buffer Alignment: IBM's PowerPC results vs. my CPU │ 49 │└──────────┴───────────────────────────────────────────────────────────────────┴──────────────10 rows in set. Elapsed: 0.070 sec. Processed 59.82 million rows, 569.21 MB (852.55 million rows/s., 8.11 GB/s.)Peak memory usage: 429.38 MiB.
即使这次查询线性扫描了全部 6000 万行,性能依然非常出色——这就是 ClickHouse 的强大性能 :) 不过需要注意,在处理 TB 或 PB 级别数据时,排序键的重要性才会真正显现!
在这种场景下,我们可以假设用户会经常按 PostTypeId 进行筛选。PostTypeId 的基数只有 8,因此非常适合作为排序键的第一个条目。与此同时,按日期粒度进行过滤已经足够满足需求(这对 datetime 类型的过滤也有效),因此我们将 toDate(CreationDate) 作为排序键的第二个部分。这种选择还能生成更小的索引,因为日期可以用 16 位表示,从而加快过滤速度。最后,我们选择 CommentCount 作为排序键的第三个条目,以便更高效地定位评论最多的帖子(用于最终排序)。
CREATE TABLE posts_v3(`Id` Int32,`PostTypeId` Enum('Question' = 1, 'Answer' = 2, 'Wiki' = 3, 'TagWikiExcerpt' = 4, 'TagWiki' = 5, 'ModeratorNomination' = 6, 'WikiPlaceholder' = 7, 'PrivilegeWiki' = 8),`AcceptedAnswerId` UInt32,`CreationDate` DateTime,`Score` Int32,`ViewCount` UInt32,`Body` String,`OwnerUserId` Int32,`OwnerDisplayName` String,`LastEditorUserId` Int32,`LastEditorDisplayName` String,`LastEditDate` DateTime,`LastActivityDate` DateTime,`Title` String,`Tags` String,`AnswerCount` UInt16,`CommentCount` UInt8,`FavoriteCount` UInt8,`ContentLicense` LowCardinality(String),`ParentId` String,`CommunityOwnedDate` DateTime,`ClosedDate` DateTime)ENGINE = MergeTreeORDER BY (PostTypeId, toDate(CreationDate), CommentCount)COMMENT 'Ordering Key'--populate table from existing tableINSERT INTO posts_v3 SELECT * FROM posts_v20 rows in set. Elapsed: 158.074 sec. Processed 59.82 million rows, 76.21 GB (378.42 thousand rows/s., 482.14 MB/s.)Peak memory usage: 6.41 GiB.Our previous query improves the query response time by over 3x:SELECTId,Title,CommentCountFROM posts_v3WHERE (CreationDate >= '2024-01-01') AND (PostTypeId = 'Question')ORDER BY CommentCount DESCLIMIT 310 rows in set. Elapsed: 0.020 sec. Processed 290.09 thousand rows, 21.03 MB (14.65 million rows/s., 1.06 GB/s.)
如果您想了解使用特定数据类型和合适排序键对压缩性能的提升,可以参考 ClickHouse 中关于压缩的内容【https://clickhouse.com/docs/en/data-compression/compression-in-clickhouse】。如果需要进一步提升压缩效果,也可以查看“选择合适的列压缩编码”这一部分【https://clickhouse.com/docs/en/data-compression/compression-in-clickhouse#choosing-the-right-column-compression-codec】。
目前,我们只迁移了一个表。这虽然帮助我们理解了一些 ClickHouse 的核心概念,但在实际应用中,大多数数据模式往往更复杂。
接下来,我们将在以下指南中,探讨如何使用多种技术重构更复杂的模式,从而优化 ClickHouse 的查询性能。在整个过程中,我们将 Posts 表作为核心,通过它执行大多数分析查询。尽管其他表可以独立查询,但我们假设绝大多数分析需求都基于 Posts 表的上下文。
本节中,我们采用了经过优化的其他表版本。虽然我们会提供这些表的结构定义,但为简洁起见,我们省略了具体的决策过程。这些优化遵循前面提到的规则,具体细节留给读者自行推导。
值得注意的是,ClickHouse 并不支持外键。这并不妨碍使用 JOIN,但引用完整性需要由用户在应用程序层面管理。在 OLAP 系统(如 ClickHouse)中,数据完整性通常通过应用程序或数据引入流程来实现,而非数据库自身强制执行。这样的设计不仅降低了系统开销,还提高了数据插入的灵活性和效率,非常契合 ClickHouse 追求极致速度和可扩展性的理念。
1. 数据反规范化:通过合并表格和使用复杂数据类型处理非 1:1 关系,将 JOIN 从查询阶段移至数据插入阶段。
2. 字典 (Dictionaries):利用 ClickHouse 特有的字典功能处理直接 JOIN 和键值查找。
3. 增量物化视图 (Incremental Materialized Views):将复杂计算的开销从查询阶段转移到插入阶段,并支持增量计算聚合值。
4. 可刷新物化视图 (Refreshable Materialized Views):类似于传统数据库中的物化视图,支持定期计算查询结果并缓存。
在接下来的指南中,我们将逐一讲解这些方法的适用场景,并结合 Stack Overflow 数据集的实际问题,通过实例展示这些策略的具体应用方式。

好消息:ClickHouse Beijing User Group第2届 Meetup 已经开放报名了,将于2024年11月30日在北京朝阳区科荟路33号4幢1层 清泉(奥林匹克森林公园店)举行,扫码免费报名

 注册ClickHouse中国社区大使,领取认证考试券
注册ClickHouse中国社区大使,领取认证考试券

试用阿里云 ClickHouse企业版
轻松节省30%云资源成本?阿里云数据库ClickHouse架构全新升级,推出和原厂独家合作的ClickHouse企业版,在存储和计算成本上带来双重优势,现诚邀您参与100元指定规格测一个月的活动,了解详情:https://t.aliyun.com/Kz5Z0q9G

征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出&图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com


