




今天分享的是中国科学技术大学、加州大学洛杉矶分校以及谷歌研究院联合发表的一篇工作。


01
论文概述
大型语言模型 (LLMs) 不可避免地会出现幻觉,仅通过它们所封装的参数知识无法确保生成文本的准确性。尽管检索增强生成 (RAG) 是对LLMs的可行补充,但它在很大程度上依赖于被检索的文档的相关性。
这篇论文提出了纠错型检索增强生成(CRAG)方法,以提升生成内容的鲁棒性和准确性。该框架旨在评估查询检索文档的整体质量来提高生成的鲁棒性,解决检索质量不高导致生成文本错误和幻觉的问题。CRAG是即插即用的,可以与各种基于RAG的方法无缝耦合。在涵盖短格式和长格式生成任务的四个数据集上的实验表明,CRAG可以显著提高基于RAG的方法的性能。
02
核心内容
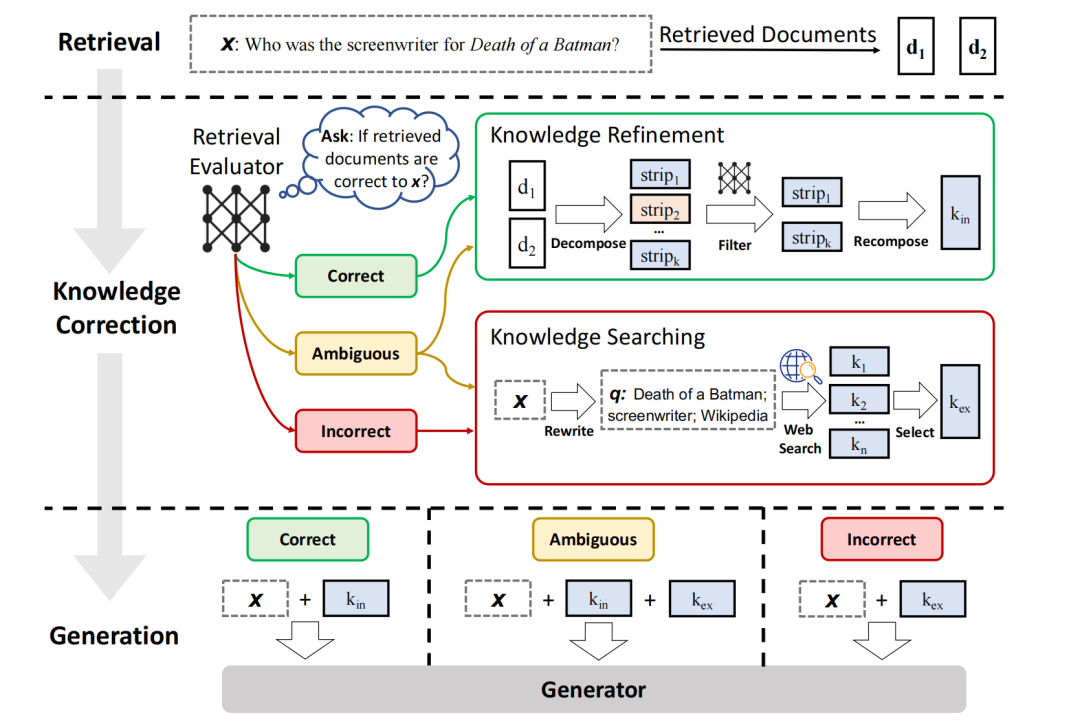
针对输入查询及任意检索器返回的检索文档,CRAG构建了一个轻量级检索评估器,用于评估检索文档与输入查询的相关性得分。相关性得分被量化为三种置信度等级,并触发相应的动作:{正确(Correct),错误(Incorrect),模糊(Ambiguous)}。
当触发正确(Correct)动作时,检索文档将被进一步精炼为更精确的知识片段。这一精炼操作包括知识的分解、过滤和重组。当触发错误(Incorrect)动作时,检索文档将被舍弃,转而依赖网络搜索作为补充知识源进行纠正。当无法自信(Ambiguous)地判断正确或错误时,将触发一种相对平衡的动作,该动作结合了正确和错误两种处理策略的优势。
检索评估器
CRAG框架中设计了一个轻量级的检索评估器,采用T5-large模型进行微调,用于评估检索文档与查询的相关性,并基于评估结果触发相应的纠正策略。相比大型语言模型(如LLaMA-2等),T5-large评估器具有明显的轻量化优势(仅0.77B参数),但能以低成本有效提升检索质量。具体地来讲,针对每个问题通常会检索到10篇文档,将问题与每篇文档逐一拼接为输入后,评估器会针对每个问题-文档对单独预测相关性得分。基于计算得到的相关性得分,可以对检索是否正确以及触发的动作进行最终判断。
动作触发
Correct
当置信得分介于上下阈值之间时,表示在检索准确性难以区分、评估器对判断不够自信。在这种情况下,将同时结合 Correct 和 Incorrect 动作中处理后的知识进行互补。
03
论文总结
研究检索器返回不准确结果的情形,首次尝试为RAG设计纠正策略以提高其鲁棒性。 提出了一个名为CRAG的即插即用方法,以提高自动自我纠正和有效利用检索文档的能力。 实验结果表明CRAG适用于基于RAG的方法,在短文本和长文本生成任务中的泛化能力。

