




HtmlRAG: HTML is Better Than Plain Text for Modeling Retrieved Knowledge in RAG Systems。
HtmlRAG:在 RAG 系统中对检索知识进行建模时,HTML 优于纯文本。

论文链接:https://arxiv.org/pdf/2411.02959

01
摘要
HTML 格式优势:保留结构化信息并充分利用 LLM 对 HTML 的理解能力,同时适配多种文档格式。 HTML 清理:设计了基于规则的清理算法,去除无用元素,压缩结构冗余,保留语义信息。 HTML 剪枝:两阶段剪枝策略,使用嵌入模型进行粗剪枝,再用生成模型进行细剪枝,优化信息提取。 实验验证:在六个 QA 数据集上,HtmlRAG 比基于纯文本的 RAG 系统表现更优。
02
主要方法
HtmlRAG 的核心目标是在保留关键信息的前提下压缩 HTML 文档长度,以适应 LLM 的输入限制并提升性能。
1. HTML 清理
这部分的目标是去除 HTML 文档中与用户查询无关的冗余信息,同时保留语义结构,为后续处理打下基础。
其流程是首先识别并删除文档中的 CSS 样式、JavaScript 代码和注释等,这些元素虽然对人类阅读有帮助,但对 LLM 的理解和分析并无实际意义。然后移除不必要的标签属性,例如class和id,这些属性在 HTML 清理阶段可以被替换为更通用的标签,例如div。同时将多层嵌套的单层标签进行合并,这样既可以减少文档的长度,也可以简化结构,方便后续处理。最后删除没有内容的标签,这些标签对文档的结构和内容没有实际影响。
首先使用 HTML 解析库将 HTML 文档解析为 DOM 树,构建文档的语义结构。并根据预设的块大小阈值(例如 256 或 512 个单词),将 DOM 树中的节点进行合并,形成块节点。合并时,优先考虑合并具有相同语义的节点,例如将同一章节下的多个段落合并为一个块。合并后的块节点包含该块内的所有文本内容,以及相关的 HTML 标签。最后处理叶子节点,将无法合并的叶子节点(例如单个段落或标题)单独作为块节点,以便后续处理。
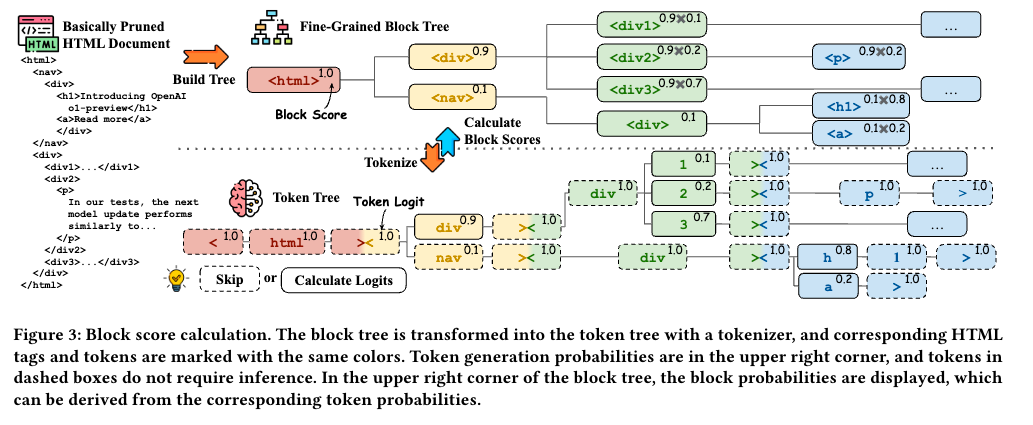
3. 剪枝算法
可以使用嵌入模型计算每个块与用户查询的嵌入相似度,将相似度较高的块视为与用户查询相关,保留下来。然后使用贪心算法删除相似度较低的块,例如从相似度最低的块开始删除,直到文档长度满足 LLM 的输入限制。还可以将嵌入模型剪枝后的块树扩展为更细粒度的块树,将每个块进一步分解为更小的块节点。再使用LLM计算每个块的路径序列概率,将其作为块的评分,评分较高的块被视为与用户查询相关,保留下来。最后使用贪心算法删除评分较低的块,例如从评分最低的块开始删除,直到文档长度满足 LLM 的输入限制。
03
流程
流程说明
检索:通过搜索引擎获取相关 HTML 文档。 HTML 清理:清除冗余结构,保留语义信息。 块树构建:划分文档内容为多个块。 嵌入模型剪枝:基于相似度缩短文档长度。
生成模型剪枝:细粒度优化块内容。 贪心剪枝:最终压缩至 LLM 可接受的长度。 LLM 输入:生成最终答案。
04
总结
05
编者简介
05
编者简介

