




点击蓝字
关注我
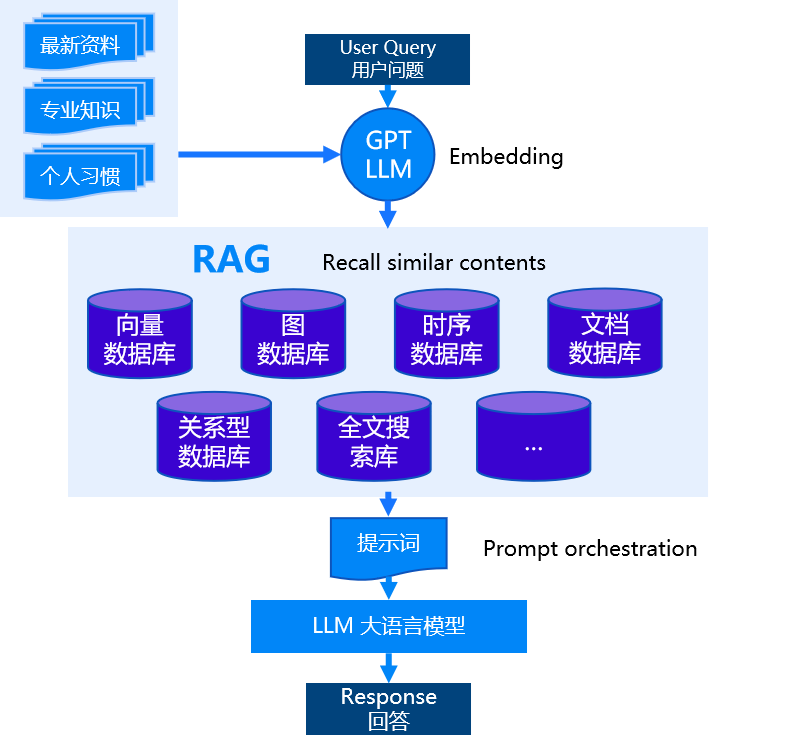
大语言模型正迅速地应用于各行各业,改变用户与企业产品和服务之间的交互方式,帮助企业提高效率、降低成本。尽管大模型具有巨大的潜力,但其训练、维护和技术难度要求极高,成本也非常昂贵。在企业实际应用过程中,大语言模型落地也存在着领域知识缺乏、知识时效性低,隐私数据安全性低、AI幻觉等挑战。
基于检索增强生成框架(RAG)的数据管理技术,通过大模型外挂知识库的方式,有效解决了大模型知识库更新及大模型“幻觉”等问题,加速企业大语言模型的应用和发展。业内最常用的方式是将文档、图片、音视频转化为向量数据存储在向量数据库中,通过检索向量数据库来增强大模型。然而,仅仅通过向量数据还远远不够,结合全文的精确检索、图数据的实体检索等模型数据的联合检索可以有效提升大模型召回的准确率。此外,一些特殊的业务场景,还需要结合时序数据、地理空间数据等进行联合检索和分析。因此,不管是解决大模型的局限性,还是为了满足更丰富的业务场景,多模型能力已成大模型时代的刚需。
市场方面,行业发展方向也印证了这一点。搜索型数据库、分析型数据库都在增加向量检索、全文检索等能力,NoSQL厂商如图数据库厂商也在拓展向量能力,市场上多模数据库产品逐渐增多,配套的多模数据库技术标准和评测也已建立。随着大模型的广泛应用和新场景的不断拓展,多模数据库迎来快速发展期。

多模联合检索能力,已成为大模型时代的刚需
随着大语言模型的快速发展以及其自身的局限,向量数据库在其中扮演重要角色,可作为外置存储来增强大模型能力。除了由专业的向量数据库提供外,业内很多关系型数据库、搜索型数据库等在原有系统基础上进一步扩展向量检索能力。如传统关系型数据库代表Oracle、MySQL、PostgreSQL陆续宣布支持向量检索,搜索引擎的代表ElasticSearch从8.0版本就开始提供基于向量检索的能力。
全文与向量混合检索,也成为趋势。全文检索更适合做关键字匹配,可以避免检索内容低频的问题。而通过将向量检索和全文检索的联合召回,可以降低漏检和误检的概率。如星环科技的向量数据库Hippo从向量拓展到全文,一个系统实现了向量与全文的联合检索,实现了比使用单一模型检索更高的精度。
图也正在与大模型结合,并与向量检索联合进一步提升大模型的准确性和推理能力。由图数据支撑的知识图谱往往不是通过公开的非结构化数据构造出来的,而是由企业内部业务或生产线的数据汇集和转化而成的,具有非常重要的业务价值。通过构建图模型的知识表达,将实体和关系之间的联系用图的形式进行展示,并与大模型相结合,在补充大模型领域知识的同时,也为大模型提供更加准确的信息,提升大模型的预测和推理能力。这方面有单一的图数据库厂商在探索,也有与向量数据库厂商整合的联合方案,而发展较早且被广泛使用的开源图数据库Neo4j已在图的基础上拓展了向量检索能力。
此外,像时序数据、地理空间数据等其他模型的数据也正在与大模型结合,并与关系型数据、向量数据等融合,满足一些领域场景的需求。比如,时序数据主要应用在金融交易数据、工业互联网设备检测数据等场景,其比传统关系型数据库具有更高的数据压缩率、更快速地时序数据查询性能等,将其作为大模型的外挂知识库,不仅可以解决大模型自身的局限性,如实现对实时产生的海量交易数据、生产数据的搜索和分析,还能带来更低的成本、更高的性能等优势。在做设备监测和分析时,往往需要结合设备的⼀些其他信息,例如设备来源、故障记录、保养记录来综合分析设备的运行状况,这些数据有些是关系型数据形式,有些是文档、图片的形式。通过将这些非结构化数据转化成向量数据,结合关系型数据、以及产线上实时产生的时序数据进行关联分析,并基于大模型的语言生成能力,可以大幅降低海量、多源、异构数据的分析门槛,提升数据分析效率。
技术局限与业务需求双驱动
多模数据库赛道火热
为了解决大模型的局限性,以及满足更丰富的业务场景,多模型能力已成大模型时代的刚需。然而,传统的数据管理模式往往是将不同的数据模型用独立的平台来处理,不同产品在接口标准上不一致,开发者和业务分析人员需要掌握不同的语言去访问、使用、操作这些数据,而这些接口都需要与大模型进行对接,并且在业务上如果涉及到了跨模型的混合业务,需要把数据从一个平台导入到另一个平台中,ETL流转效率低,同时也难以保证数据的准确性、一致性和实效性。
多模数据库旨在单个系统中集成了多个关系型和/或非关系型数据引擎(例如,文档、图、键值、时序等),通过使用单个系统来降低操作的复杂性,更好地支持不同场景下的多种类型数据处理,成为大模型外置知识库的最佳选择。
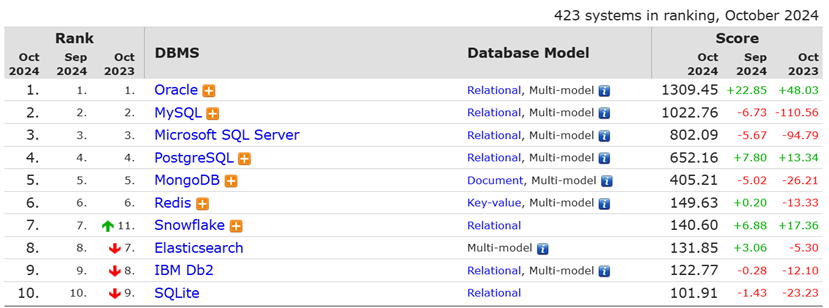
Gartner近几年发布的《Hyper Cycle for Data Management》报告中,多模数据库在2020年时还是在泡沫化的底谷期,2022年进入到实质生产的高峰期,2023年已经成为技术成熟度曲线靠右第二的技术了,而2024年已经不再出现了该曲线上,说明该技术早已成熟,并被市场接受和应用。从数据库流行度排行榜DB-engines上可以看出,流行度排名前10的产品有8个均支持多模能力。
而国内发展则显得稍慢一些,比如Gartner在2022年发布了《中国数据库管理系统供应商甄选》,列举了中国数据库市场的数据库产品和厂商情况,其中,多模数据库只有阿里云、星环科技、巨杉和达梦四家。而2023年之前,墨天轮中国数据库流行度排名中并没有“多模型”分类,之后增加了“多模型”分类,起初只有星环科技ArgoDB、阿里云Lindorm和华为云GeminiDB三个产品。
2023年,随着大模型元年“百模大战”的拉响,向量数据库产品如雨后春笋版冒了出来,多模数据库产品也逐渐增多,如九章云极发布多模向量数据库DingoDB,浪潮发布多模数据库KaiwuDB等。同时还有许多关系型数据库、搜索型数据库、图数据库等产品虽然没有直接定位为“多模数据库”,但陆续在原有系统基础上扩展向量检索、全文检索等多模能力,如阿里云PolarDB、PingCAP TiDB、蚂蚁OceanBase、枫清科技ArcNeural等。
2024年,中国信通院联合30余家企业制定了《多模数据库技术要求》标准,并开展了“可信数据库”多模数据库产品评测,目前已有星环科技、阿里云、九章云极等陆续通过了该项评测。
可以预见,随着大模型的深入应用和新场景的不断探索,数据库会集成越来越多的数据模型,多模数据库赛道的竞争将进一步加剧。
多种实现方式,
原生统一多模架构加速大模型落地
目前常见的多模数据库实现架构主要有四种:
第一种,为每一种新数据模型开发独立完整的存算策略,例如IBM DB2和Oracle DB等,其本身都是在关系型基础上增加对多模的支持。这种多模架构的缺点是基于存算耦合架构,支持的模型越多,系统的开发量和复杂度就越高,消耗存算资源也较多。正因为如此,其支持的数据模型相对较少。
第二种,用单一存储引擎支撑多个存储模型,如MongoDB属于文档数据库,在文档数据引擎下,也支持键值、对象数据、向量数据等模型。由于不同计算数据模型对于存储的要求不同,单一存储引擎无法随之匹配适合的存储策略,从而限制了多模型数据库的性能。
第三种,在多种独立数据库之上提供统一的用户界面,对底层多个数据库进行转发。例如CouchBase和Marklogic等。这种多模架构由于底层多个数据库开发语言不一致,导致了实际开发时的高难度,排除故障的成本也较高。
第四种,用统一接口、统一的计算引擎、统一的存储管理和统一的资源管理的原生统一多模架构来支持多模型。星环科技原创的分层架构设计,基于存算解耦合架构,实现了支持关系型、图、时序、宽表、时空、向量等11种数据模型的统一存储管理和跨模型联合分析。

在传统数据分析场景下,基于原生多模统一架构,用户不需要独立建设不同的数据库,而是可以实现不同模型数据的统一存储管理,只需用一句SQL就能同时访问多种存储模型进行联合分析,替代之前多段代码查询,一次操作完成之前多次操作才能完成的业务,极大简化了开发复杂度,简化用户操作。同时数据也仍保留在原存储引擎中,也不用对数据进行导入导出或者转换,不会存在数据不一致或数据冗余存储的问题。
在大模型场景下,基于原生多模统一架构,可以满足大模型场景下多模态数据的统一存储管理与服务,大幅简化知识库的知识存储与服务层架构,降低开发与运维成本。通过将其作为大模型外置知识库,可以检索文本/图片/音视频转化后的向量数据、图数据、时序数据、以及传统关系型数据等,不仅可以解决大模型在领域知识缺乏、知识时效性低等问题,大幅提升大模型的准确率,也可以基于多模型数据探索和应用更多的业务场景。


扫码关注我们
扫码关注我们
END
