




关注我们
1
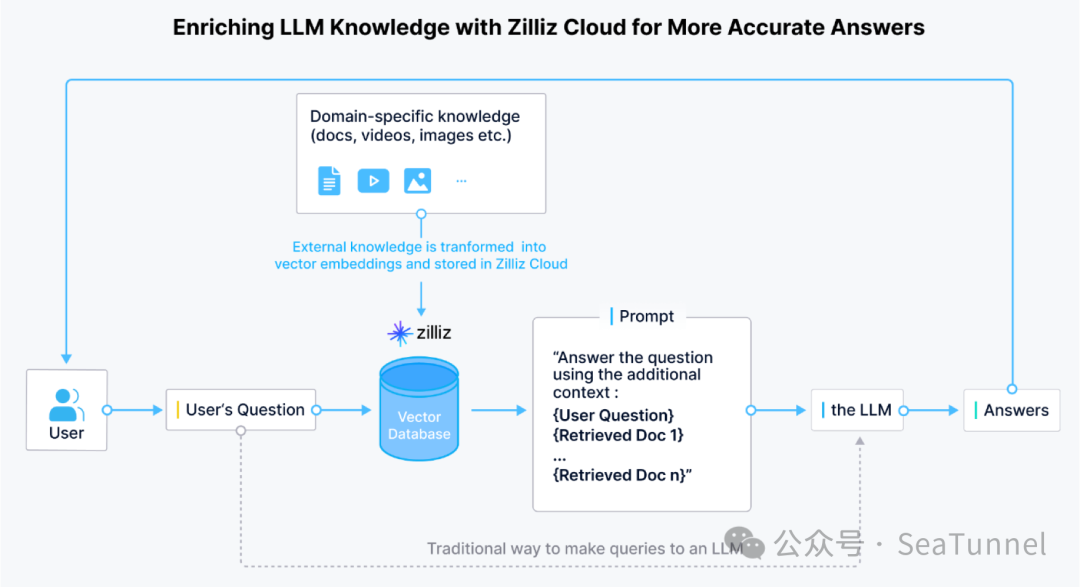
引言
2
什么是向量数据库
它能够高效处理高维向量数据,支持相似性搜索 支持KNN(K-近邻)搜索 计算向量间的距离(欧氏距离、余弦相似度等) 快速检索最相似的向量 主要用于AI和机器学习应用场景 图像检索系统 推荐系统 自然语言处理 人脸识别 相似商品搜索
3
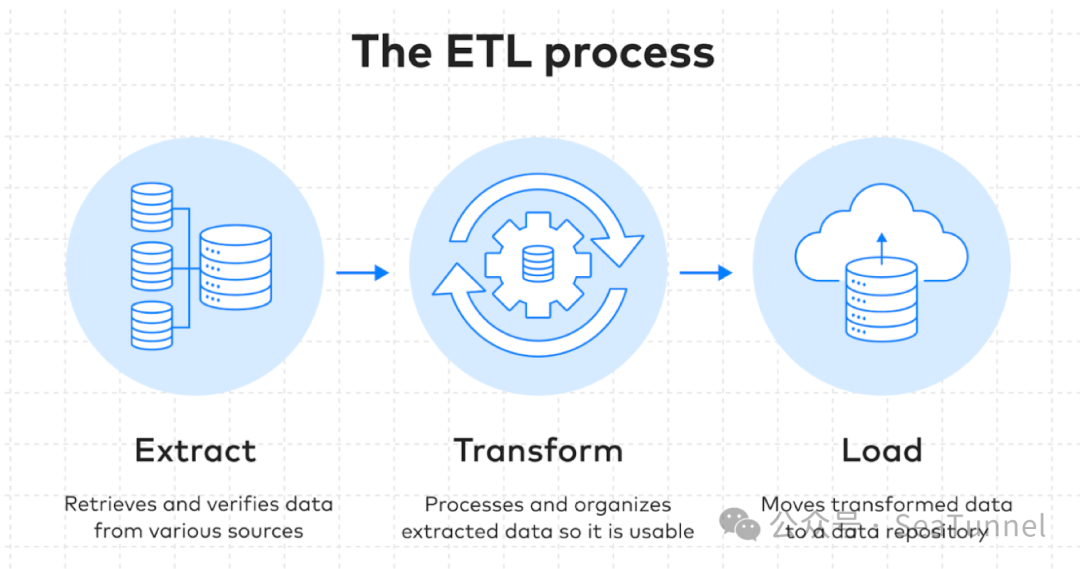
开发动力和背景
数据碎片化:用户数据分散在多个平台中,如 S3、HDFS、Kafka、数仓和数据湖。 多样的数据格式:非结构化数据以各种格式存在,包括 JSON、CSV、Parquet、JPEG 等。 缺乏完整的解决方案:目前没有一款产品能够完全满足跨系统高效传输非结构化数据和向量数据的复杂需求。
供应商锁定带来的影响
非结构化数据迁移的挑战
缺乏面向向量数据库的 ETL 工具:像 Airbyte 和 Seatunnel 之类的主流工具仅面向传统的关系型数据库,无法有效满足向量数据库之间的数据迁移需求。 向量数据库之间能力差异: 许多向量数据库不支持数据导出。 部分向量数据库的增量数据实时处理能力有限。 向量数据库之间的数据 Schema 不匹配。
为向量数据而生的数据迁移工具
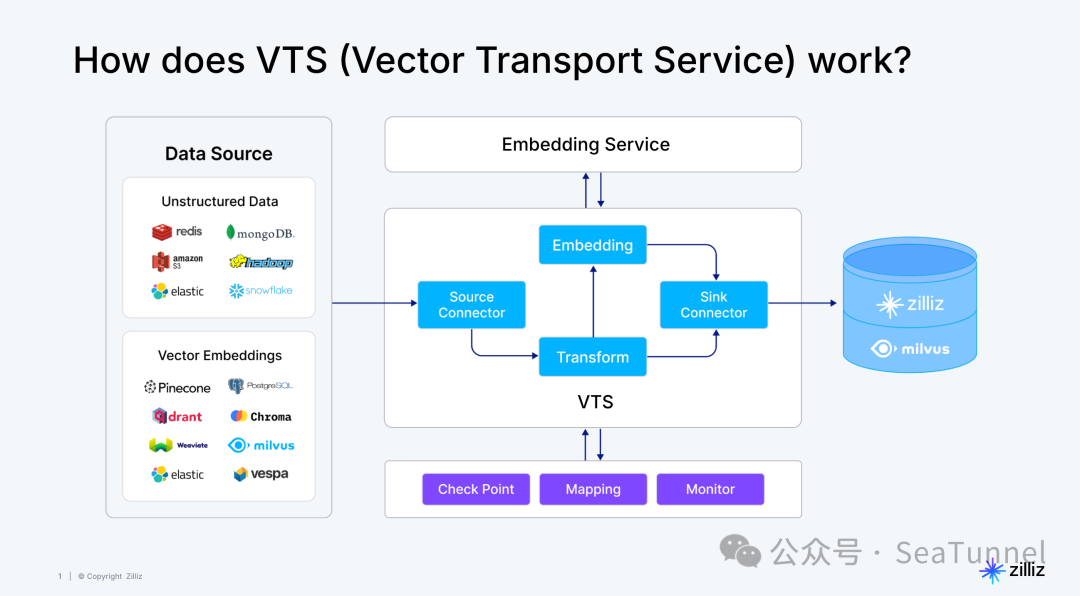
GitHub地址:https://github.com/zilliztech/vts
满足日益增长的数据迁移需求:用户的需求不断扩展,演变为将数据从不同的向量数据库、传统的搜索引擎(如 Elasticsearch 和 Solr)、关系型数据库、数仓、文档数据库,甚至 S3 和数据湖进行迁移。 支持实时流数据流和离线导入:随着向量数据库能力的不断扩展,用户需要对实时流数据的支持和离线批量导入的能力。 简化非结构化数据转换流程:与传统 ETL 不同,转换非结构化数据需要借助 AI 模型的力量。迁移服务结合了 Zilliz Cloud Pipelines,能够将非结构化数据转换为 Embedding 向量并完成数据标记等任务,显著降低数据清洗成本和操作难度。 确保端到端的数据质量:数据集成和同步过程中容易出现数据丢失和不一致的问题。迁移服务通过强大的监控和告警机制解决了这些可能影响数据质量的问题。
4
VTS核心能力
基于Apache SeaTunnel
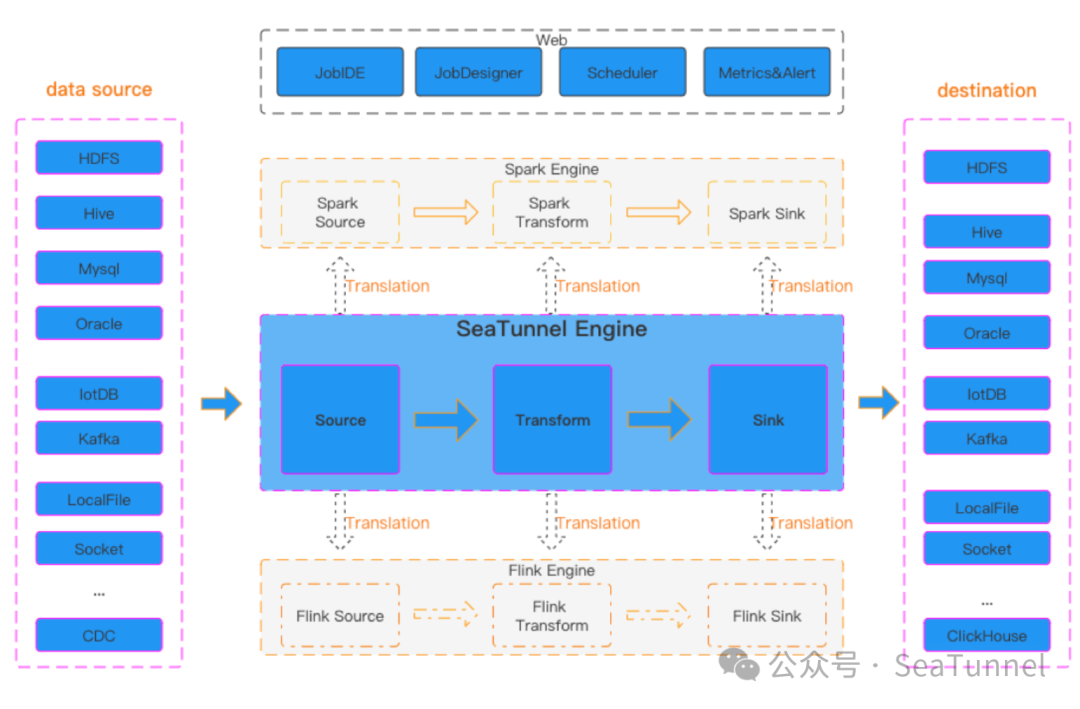
向量数据库迁移 AI应用数据Pipeline构建 向量数据实时同步 非结构化数据转换与加载 跨平台数据集成
向量数据库迁移
跨平台数据集成
5
VTS支持的Connector和Transform
支持的Connector
支持的Transform
支持的数据类型
性能演示
非结构化数据支持
6
应用场景
7
未来规划
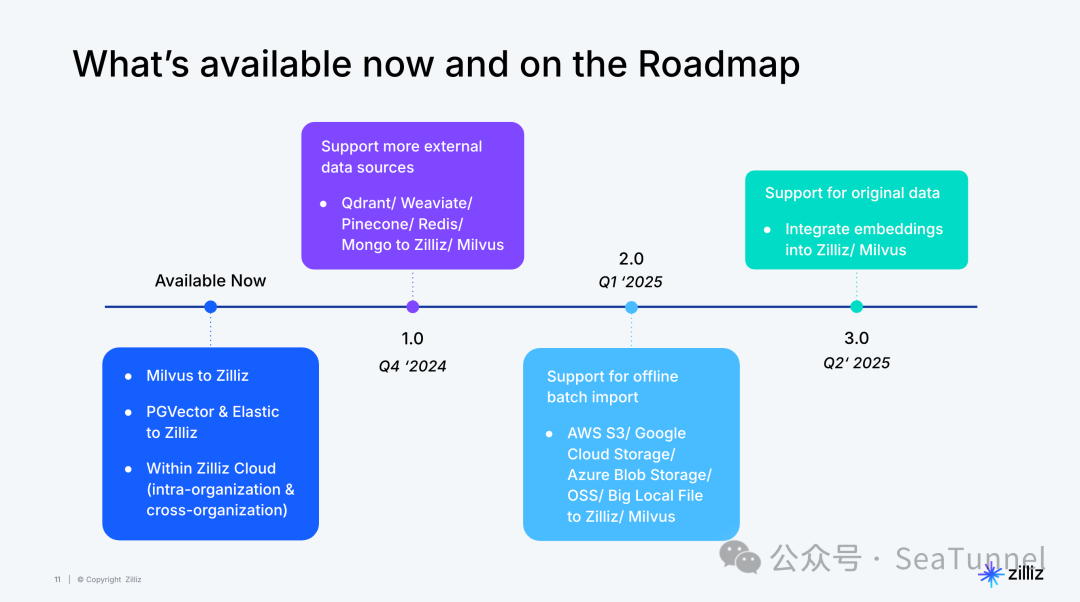
8
结语

Apache SeaTunnel
精彩推荐
点击阅读原文了解更多⭐️!

文章转载自SeaTunnel,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
