




通常来说,业务应用系统 = 数据存储 + 逻辑处理 + 网络传输。其中的数据存储是系统的根基。
在业务应用系统中,需要持久化到磁盘的数据,一般保存在这些存储系统中:
关系型数据库:mysql,等 键值系统(NOSQL):redis,等 搜索引擎:ElasticSearch,等 文件系统:图片、视频等独立文件,log日志,等
存储系统的功能包括:增、删、查、改。其中,读又分为随机读取和顺序扫描。
磁盘数据存储结构有:
随机查找型: B树、LSM树 哈希 顺序扫描型: 文件append
磁盘机制
内存 vs 磁盘:内存数据在电脑断电重启后会丢失,所以要保存下来的数据文件都需要持久化到磁盘。
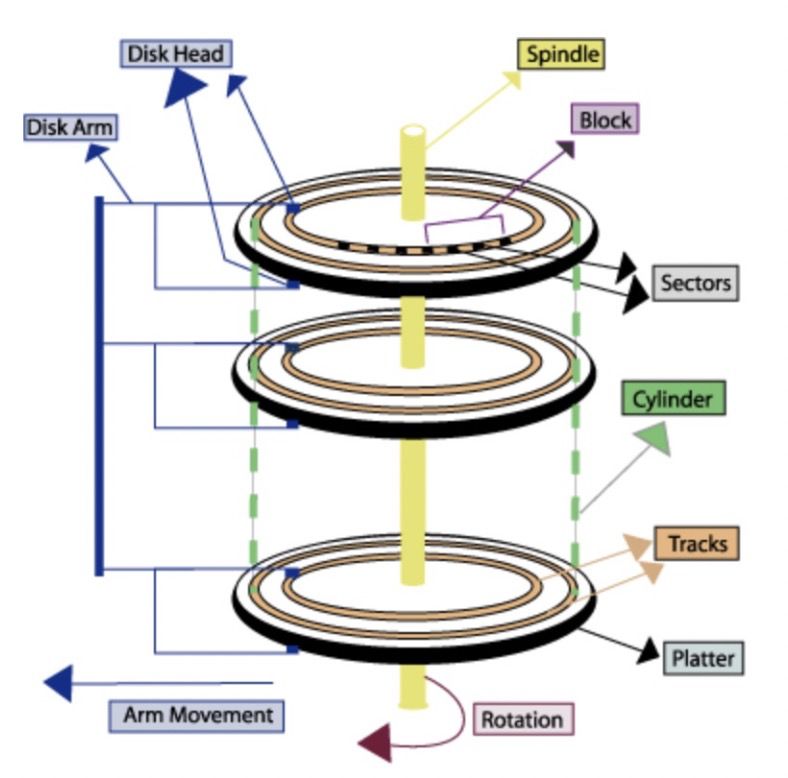
磁盘读写时涉及到磁盘上数据查找,数据地址一般由柱面号、盘面号和块号三者构成。磁盘读取依靠的是机械运动,也就是说移动臂先根据柱面号移动到指定柱面,然后根据盘面号确定盘面的磁道,最后根据块号将指定的磁道段移动到磁头下,便可开始读写。
整个过程主要有三部分时间消耗:查找时间(seek time) 、等待时间(latency time)、传输时间(transmission time) ,分别表示定位柱面的耗时、将块号指定磁道段移到磁头的耗时、将数据传到内存的耗时。
其中整个磁盘IO最耗时的地方在查找时间(即磁盘寻道),顺序访问的查找时间开销比较小,随机访问则需要较长的磁盘寻道时间。
15000转的SATA盘的顺序读取带宽可以达到100MB/s以上,则顺序读取1MB数据的耗时为100KB / 100MB/s * 1000 = 1ms;而磁盘寻道的耗时则需要10ms。
可以看出,磁盘顺序读写数据的带宽还是不错的;存储系统的性能瓶颈主要在于磁盘随机读写:
从磁盘读取100KB数据的耗时 = 磁盘寻道时间10ms + 数据读取时间1ms = 11ms
如果能尽量避免磁盘随机读写,尽量减少磁盘寻道的次数,则可以很大地提升存储系统的性能。比如,将随机读写转化为顺序读写,通过缓存减少磁盘随机读写,等。

B-tree
B树存储引擎是B树的持久化实现,不仅支持单条记录的增、删、查、改,还支持顺序扫描。
通常用于实现关系型数据库。
平衡二叉树、B树、B+树
先回忆下,平衡二叉树、B树、B+树是长什么样子的:
平衡二叉树:平衡查找树,即每次插入后都会通过旋转节点保持平衡的有序二叉树
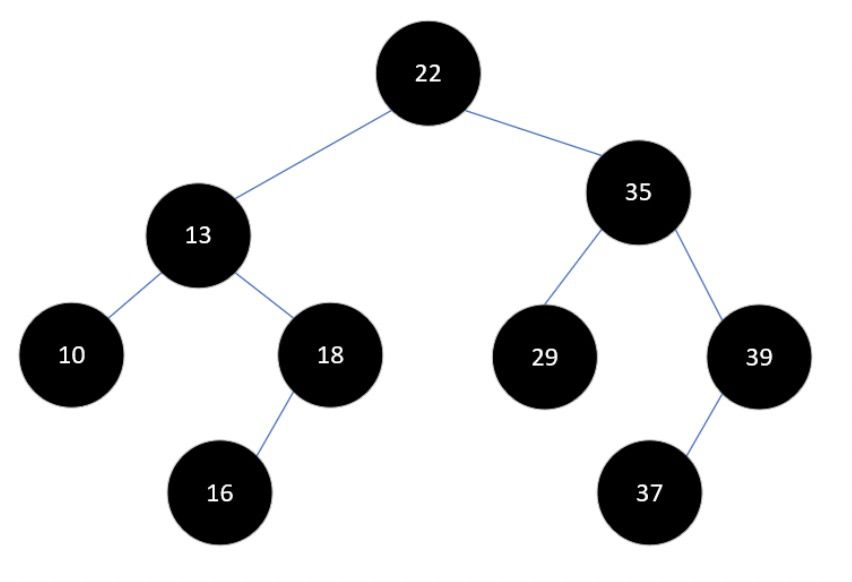
B树:多路平衡查找树
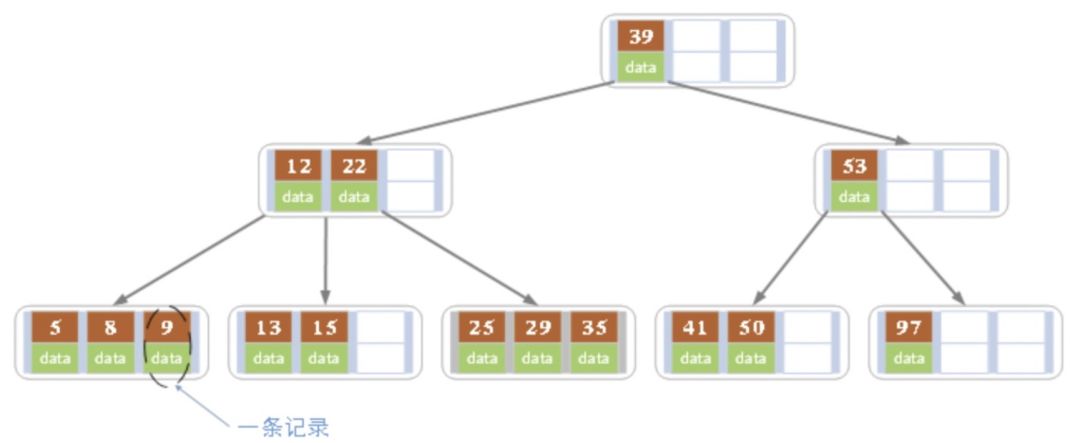
B+树:多路平衡查找树
与B树最大的不同是内部结点不保存数据,只用于索引;所有数据(或者说记录)都保存在叶子结点中;叶子结点本身依关键字的大小自小而大顺序链接;并且每个叶子结点都存有相邻叶子结点的指针。
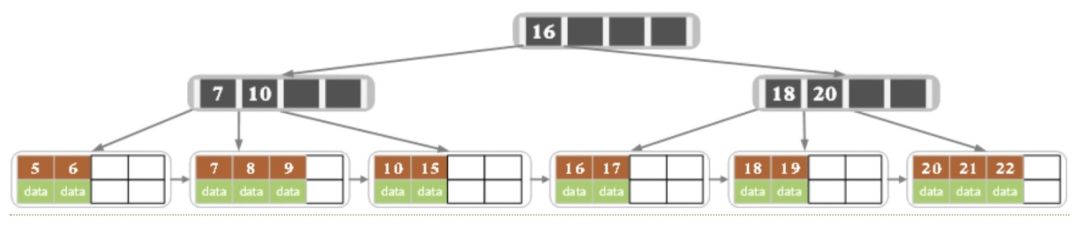
why B-Tree
我们知道,有序二叉树可用于快速查找;而B+树和平衡二叉树在索引数据方面,查找速度差别不大:虽然存储同样多的数据,100阶的B+树肯定比平衡二叉树的高度要低的多,但是B+树在一个结点可能需要比较很多次才能找到下一层的结点,但是平衡二叉树只要比较一次就可以向下走一层。所以综合起来,其实两者索引的速度几乎是一样的。
那为什么存储引擎一般是用B+树,而不是平衡二叉树呢?:
这是因为上面说索引速度相当的前提是,两者的数据结构都位于内存中。当我们要在磁盘上索引一个记录时,每次都要把接点数据读入内存中才能作比较判断;相比起磁盘IO耗时,在内存中对比数据过程所花的时间基本可以忽略不计,所以应尽量减少磁盘IO次数。减少磁盘IO的次数就必须要压缩树的高度,让瘦高的树尽量变成矮胖的树,所以支持多路查找的B+树肯定比二路查找的平衡二叉树要更优,因为B+树中一个节点中可以存放很多的key,相同数量的key在B+树中生成的节点要远远少于二叉树中的节点,相差的节点数量就等同于磁盘IO的次数。
同时,在磁盘中以B+树的形式组织数据就有着天然的优势:由于磁盘IO是非常昂贵的操作,所以计算机操作系统对此做了优化——预读。因为局部预读原理说明:当访问一个地址数据的时候,与其相邻的数据很快也会被访问到。所以每次磁盘IO时,不仅仅把当前磁盘地址的数据加载到内存,同时也把相邻数据也加载到内存缓冲区中。每次磁盘IO读取的数据我们称之为一页(page),一页的大小与操作系统有关,一般为4KB或者8KB。这也就意味着读取一页内数据的时候,实际上发生了一次磁盘IO。
假设,我们现在选择4KB作为内存和磁盘之间的传输单位,那么我们在设计B+树的时候,不论是索引结点还是叶子结点都使用4KB作为结点的大小。假设一个记录的大小是1KB,那么一个叶子结点可以存4个记录。而对于索引结点(大小也是4KB),由于只需要存key值和相应的指针,所以一个索引结点可能可以存储100~150个分支,所以整棵树大概可以存储400万个记录:
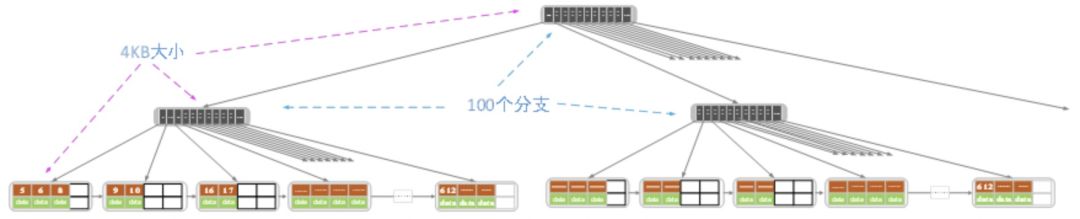
考虑如上图所示的B+树,如果这个B+树存储到磁盘中,我们怎么根据记录的key找到对应的记录呢?
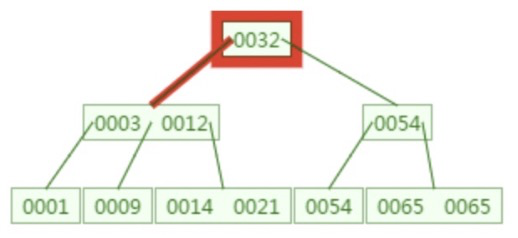
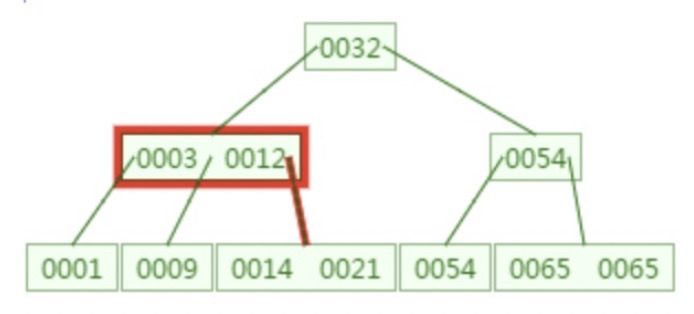
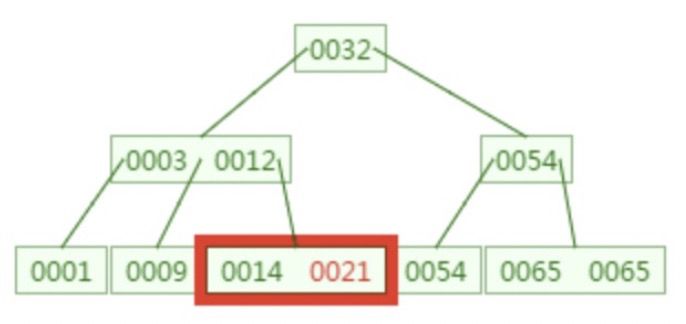
这样我们只需要通过三次磁盘IO时间,就从400万个记录中找到了对应的key记录,可以说是非常快了。
快速的原因是:索引结点中不存数据,只存键和指针,所以一个索引结点就可以存储大量的分支,而一个索引结点只需要一次IO即可读取到内存中。
LSM(Log Structure Merge Tree)
LSM树其实是一种思想,是对B树存储引擎的一种优化方法,通过批量转储技术来避免磁盘随机写入(多次的磁盘寻道)。和B树相比,LSM树牺牲了部分读性能,用来大幅提高写性能。
通过LSM树实现的存储系统有:levelDB、HBase、等。
LSM树的设计思想非常朴素:将对数据的修改增量保持在内存中,达到指定的大小限制后将这些修改操作批量写入磁盘。不过读取的时候稍微麻烦,需要合并磁盘中历史数据和内存中最近修改操作。
所以写入性能大大提升,读取时可能需要先看是否命中内存,否则需要访问较多的磁盘文件。
LSM树在实际项目中可以有很多优化策略,比如使用布隆过滤器快速判断key是否存在,做一些额外的索引以帮助更快找到记录,等等。
LSM树由两个或以上的存储结构组成,以两个存储结构为例,一个存储结构常驻内存中,称为C0 tree,具体可以是任何方便健值查找的数据结构,比如红黑树、map之类。另外一个存储结构常驻在硬盘中,称为C1 tree,具体结构类似B树。
1)插入操作:
插入一条新记录时,首先在日志文件中插入操作日志,以便后面恢复使用,日志是以append形式插入,所以速度非常快;
将新记录的索引插入到C0中,这里在内存中完成,不涉及磁盘IO操作;
当C0大小达到某一阈值时或者每隔一段时间,将C0中记录滚动合并到磁盘C1中;对于多个存储结构的情况,当C1体量越来越大就向C2合并,以此类推,一直往上合并Ck。
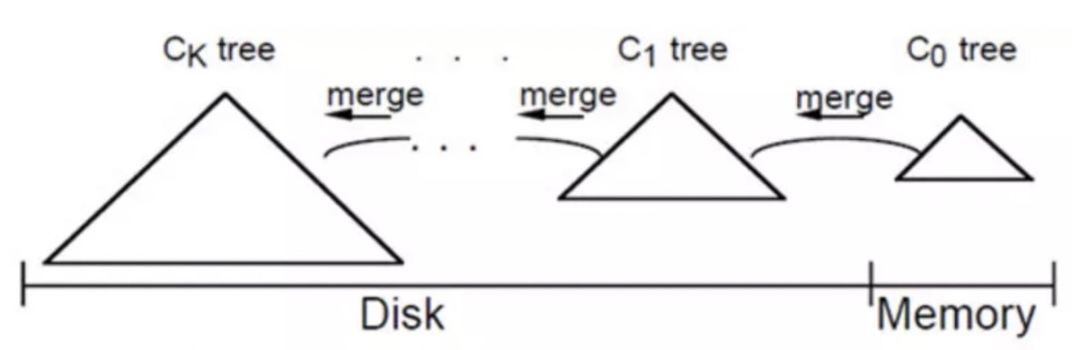
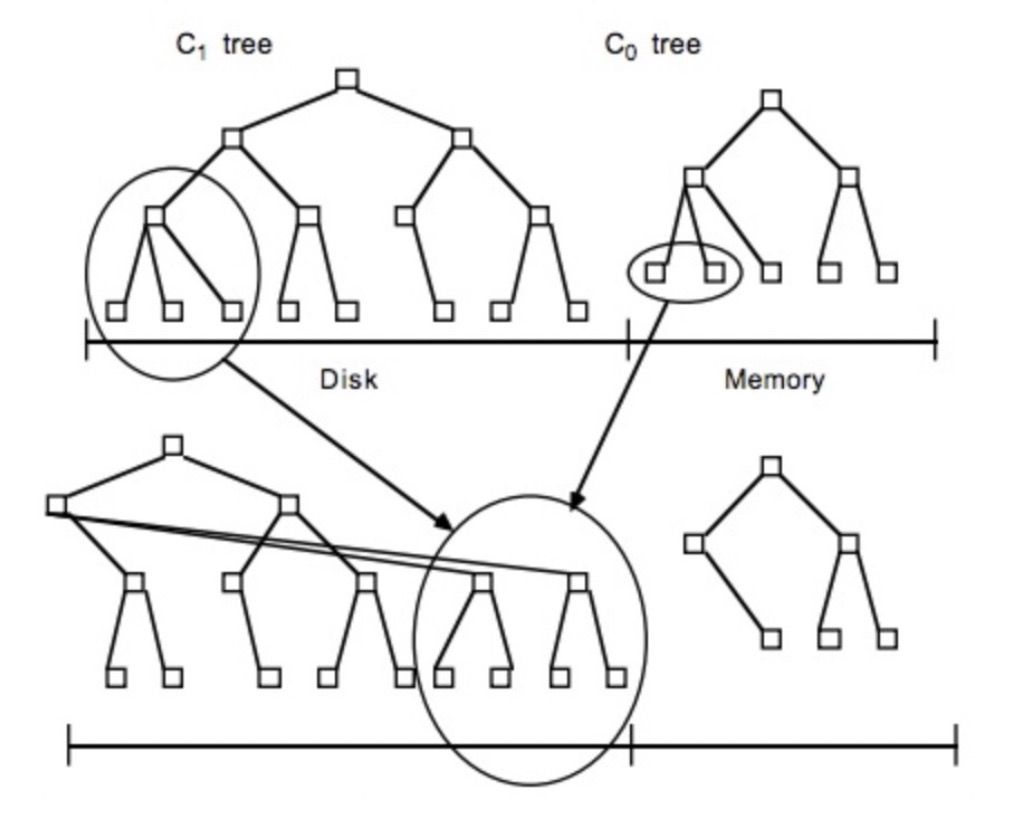
2)合并操作:
将C1的数据读取到内存中,和内存中C0的数据进行合并排序(类似“归并排序”),合并结果以追加的方式刷入到磁盘中C1树的新位置上(注意是追加而不是改变原来的节点)。
3)更新操作:
如果该记录在内存C0树中存在,则可以直接替换;
如果该记录在磁盘中,则可以在异步执行合并时,使用内存C0树中的新记录覆盖磁盘中的老记录。
因为读取数据是优先读取内存C0树中的数据,所以可以保证读到的数据都是最新的
4)删除操作:
删除操作为了能快速执行,主要是通过标记来实现:在内存C0树中将要删除的记录标记一下,后面异步执行合并时将相应记录删除。
如果C0树不存在的要删除的记录,则在C0树中生成一个该记录的节点并标为删除,这样查找时就能在内存中得知该记录已被删除,无需去磁盘找了。
哈希存储
哈希存储引擎是哈希表的持久化实现,支持增、删、改,以及随机读取操作,但不支持顺序扫描。
通常用于实现键值(key-Value)存储系统,比如nosql。
哈希存储引擎的哈希表结构中,哈希索引可以存储在内存哈希结构中,key-value数据则存储在磁盘中。
内存哈希索引的每一项包含了三个用于定位磁盘value数据的信息:文件编号(file_id)、value在文件中的位置(value_pos)、value的长度(value_size)。
1)读操作时,通过key从内存哈希表中获取对应的value定位信息,然后到磁盘中读取file_id对应文件的value_pos开始的value_size字节,就可以得到value值。
2)写操作时,首先将key-value记录追加到活跃数据文件(file)的末尾,然后更新内存哈希表。当一个活跃数据文件中的数据达到大小限制,则这个文件就变成了老数据文件;新记录会追加到新建立的活跃数据文件末尾。
3)更新操作时,为了避免磁盘的随机读写,可以通过“直接添加新记录 + 使用时间戳确定同一个key的哪条记录是最新”的方式来代替“更新记录”操作。
因此,每次读操作包括了一次内存读操作和一次磁盘寻道读操作;写操作则包括了一次顺序的磁盘写入(追加append)和一次内存操作。
定期合并:
key-value系统中的记录删除或更新后,原来的记录会成为垃圾数据。因此需要定期将老数据文件中的数据扫描一遍,对同一个key的多个操作以只保留最新一个记录的原则进行数据合并,合并后的数据写入新生成的数据文件中。
数据恢复:
当断电机器重启后,内存中的哈希索引会丢失,这时候可以通过扫描一遍磁盘文件(file)中的数据,重建内存哈希结构。如果数据文件很大,这是一个非常耗时的过程。
因此,可以通过索引文件(hint file)来提高重建内存哈希索引表的速度:简单来说,索引文件就是将内存中的哈希索引表转储到磁盘生成的结果文件。这样,在重建内存哈希表式,就不需要扫描所有数据文件,而仅仅需要将索引文件中的数据一行行读取并重建即可。
Log
日志可以分为两大类:
一类是我们平常在代码中打印的业务日志,用于记录系统运行信息、定位问题;
另一类是操作日志(commit Log),用于实现优化磁盘读写性能、系统故障恢复等。
日志在磁盘中的存储,一般就是以追加的方式写入到一个个文件中。
业务日志这里就不展开讲了;下面主要讲下对于存储系统尤为重要的操作日志(commit Log)。
操作日志
操作日志分为:重做日志(redo log)、回滚日志(undo log)和 回滚/重做日志(undo/redo log)
回滚日志记录事务修改前状态;重做日志记录事务修改后的状态。例如:事务T对表格中的X执行加10操作,初始时X=5,更新后X=15,那么undo日志记为
写操作日志的约束规则为:“日志先行”,即在修改内存中的元素X之前,要确保与这一修改相关的操作日志必须先刷入到磁盘中(追加式)。
“日志先行”的原因是:加入先修改内存中的数据,那么用户就能立刻读到修改后的结果,一旦在完成内存修改与写入操作日志之间发生故障,那么最近的修改操作就无法恢复;然而之前的用户可能已经读取了修改后的结果,这就会产生数据不一致的情况。
写操作日志流程如下:
1)将操作日志以追加写的方式写入磁盘的日志文件 2)将操作日志的修改操作应用到内存中 3)返回操作成功或失败
操作日志的作用:
1)通过转换随机写为顺序写,优化磁盘写性能
以数据库为例,为了保证数据库的一致性,数据库操作需要持久化到磁盘,如果每次操作都随机更新磁盘的某个数据块,系统性能将会很差。因此,可以通过操作日志顺序记录每个数据库操作并在内存中执行这些操作,内存中的数据通过后台线程定期刷新到磁盘,实现将随机写磁盘数据请求转化顺序写操作日志请求。
2)系统故障恢复(重做日志)
基于“日志先行”的原则,所有对数据的操作必定会先有操作日志。
因此,如果机器断电重启,内存中还没有落入磁盘的数据会丢失;这时可以通过redo日志进行故障恢复,只需要从头到尾读取日志文件中的修改操作,并将这些操作逐条应用到内存/磁盘的数据中,即可恢复数据。
3)实现事务操作回滚(回滚日志)
以数据库为例,数据库运行过程中可能会发生故障,这时候某些事务可能执行到一半但没有提交。当系统重启时,数据需要能够恢复到一致的状态,即要么提交整个事务,要么回滚。
由于undo日志记录了数据变更前的状态,以此可以通过undo日志恢复数据到事务前的状态
操作日志优化:
1、成组提交(Group Commit):主要针对重做日志
存储系统要求先将操作日志刷入磁盘才能更新内存中的数据,如果每个事务都要求将日志立即刷入磁盘,受限于磁盘IO,这个操作仍然是事务并发的瓶颈,系统的吞吐量将会很差。
因此,存储系统往往有一个是否立即刷入磁盘的选项,对于一致性要求很高的应用,可以设置为立即刷入;相应地,对于一致性要求不太高的应用,可以设置为不要求立即刷入,首先将操作日志缓存到内存缓冲区中,通过后台线程定期刷入磁盘,比如在满足“日志缓冲区中数据量超过一定大小 / 距离上次刷入磁盘超过一定时间”任一条件时,将操作日志刷入磁盘。这种做法有一个问题,如果存储系统意外故障,可能丢失最后一部分更新操作;所以如果某个事务的redo log还没有全部刷入磁盘,机器就断电重启了,则可以通过undo log进行事务回滚,丢弃该事务。
成组提交与定期刷入磁盘的思想类似,通过将多个事务操作日志的刷磁盘动作合并,减少刷磁盘次数。但成组提交与定期刷入磁盘不同的是,成组提交技术要保证操作日志成功刷入磁盘后,才能返回写操作成功。这样可能会牺牲写事务的延时,但大大提高了系统的吞吐性。
以InnoDB为例,当InnoDB变更任何数据前,会写一条redo log到内存日志缓冲区。在缓冲区满的时候、事务提交的时候、或者每一秒钟(任一条件达到),InnoDB都会刷写缓冲区的内容到磁盘日志文件。InnoDB的Group Commit(成组提交)开启时,可以通过组提交,实现在一个磁盘IO操作中提交多个事务:
在InnoDB日志系统里面,每条redo log都有一个lsn(Log Sequence Number),lsn是单调递增的。每个事务执行更新操作都会包含一条或多条redo log,各个事务将日志拷贝到内存缓冲区log_sys_buffer时(log_sys_buffer 通过log_mutex保护),都会获取当前最大的lsn,因此可以保证不同事务的lsn不会重复。假设三个事务Trx1、Trx2和Trx3的日志的最大lsn分别为lsn1、lsn2、lsn3(lsn1<lsn2<lsn3),它们同时进行提交,那么如果Trx3日志先获取到log_mutex进行落盘,它就可以顺便把[lsn1---lsn3]这段日志也刷了,这样Trx1和Trx2就不用再次请求磁盘IO,从而实现在一个磁盘IO操作中提交多个事务。组提交的基本流程如下:
1)获取 log_mutex 2)若 flushed_to_disk_lsn(已刷盘的lsn) >= lsn,表示日志已经被刷盘,跳转5 3)若 current_flush_lsn(正在刷盘的lsn) >= lsn,表示日志正在刷盘中,跳转5后进入等待状态 4)将小于lsn的日志刷盘(flush and sync) 5)退出 log_mutex
关于InnoDB的组提交,更多可参考:[图解MySQL]MySQL组提交:https://yq.aliyun.com/articles/617776
2、检查点(checkpoint):主要针对重做日志
通过记录操作日志,存储系统可以把数据保存在内存后,就马上返回成功给用户;然后再通过后台线程慢慢把内存中的数据刷到磁盘中。但如果系统故障/断电重启后,内存中的数据就会丢失,这时候需要依赖redo日志,恢复内存中的数据:故障恢复时,需要回放所有的redo日志,效率较低;如果redo日志较多,那么故障恢复时间会很长。
checkpoint(检查点)技术:系统定期将内存中的数据以某种易于加载的形式dump(转储)到磁盘中,并记录checkpoint时刻的日志回放点,以后故障恢复只需要回放checkpoint时刻的日志回放点之后的redo日志。
参考
《大规模分布式存储系统:原理解析与架构实战》
看图轻松理解数据结构与算法系列(NoSQL存储-LSM树):https://juejin.im/post/5bbbf7615188255c59672125
The Log-Structured Merge-Tree (LSM-Tree):http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.44.2782&rep=rep1&type=pdf
深入理解数据库索引采用B树和B+树的原因:https://blog.csdn.net/qq_35571554/article/details/82796278
B+树在磁盘存储中的应用:https://www.cnblogs.com/nullzx/p/8978177.html
《高性能mysql第三版》8.5.1 InnoDB I/O配置
MySQL binlog和redo的组提交:http://blog.itpub.net/29654823/viewspace-2153565/
[图解MySQL]MySQL组提交:https://yq.aliyun.com/articles/617776
