





近日,开源PolarDB分布式版(以下简称PolarDB-X)正式发布2.4.1版本,重点增强企业级运维能力,面向DBA的数据库运维和数据管理需要,新增云备份转储恢复、在线DDL、数据库扩缩容、数据TTL等特性,全面提升 PolarDB-X 在多云部署、以及分布式大规模下的可运维性。

PolarDB-X 开源脉络
2021年10月在云栖大会上,阿里云正式对外开源了云原生分布式数据库PolarDB-X,采用全内核开源的模式,开源内容包含计算引擎、存储引擎、日志引擎、Kube等。
2022年1月,正式发布 2.0.0 版本,新增集群扩缩容、以及binlog生态兼容等特性,兼容 maxwell 和 debezium 增量日志订阅,以及新增其他众多新特性和修复若干问题。
2022年3月,正式发布 2.1.0 版本,全面提升 PolarDB-X 稳定性和生态兼容性,其中包含基于Paxos的三副本共识协议。
2022年5月,正式发布2.1.1 版本,重点推出冷热数据新特性,可以支持业务表的数据按照数据特性分别存储在不同的存储介质上。
2022年10月,正式发布2.2.0版本,重点推出符合分布式数据库金融标准下的企业级和国产ARM适配,共包括八大核心特性,全面提升 PolarDB-X 分布式数据库在金融、通讯、政务等行业的普适性。
2023年3月, 正式发布2.2.1版本,在金融标准能力基础上,重点加强了生产级关键能力,全面提升面向数据库生产环境的易用性和安全性。
2023年10月份,正式发布 2.3.0版本,重点推出PolarDB-X标准版(集中式形态),将PolarDB-X分布式中的DN节点提供单独服务,支持paxos协议的多副本模式、lizard分布式事务引擎,同时可以100%兼容MySQL。
2024年4月份,正式发布2.4.0版本,重点推出列存节点Columnar,提供持久化列存索引(Clustered Columnar Index,CCI),一张表可以同时具备行存和列存的数据,结合计算节点CN的向量化计算,可以满足分布式下的查询加速的诉求,实现HTAP一体化的体验和效果。
开源PolarDB-X v2.4.1特性
云备份集转储恢复
PolarDB-X开源版本全面继承了商业版本的生产级别的稳定性验证,同时开源和商业版在数据文件的物理格式上是互通的。因此,可以基于开源版本可以构建商业版本的 Backup。
🔗https://doc.polardbx.com/zh/operator/ops/backup-restore/restore-business-backupset.html
总体步骤分为两部分:导入备份集和发起恢复任务。
比如:运行的导入备份集工具,需要三个配置文件放在工具的配置目录下:
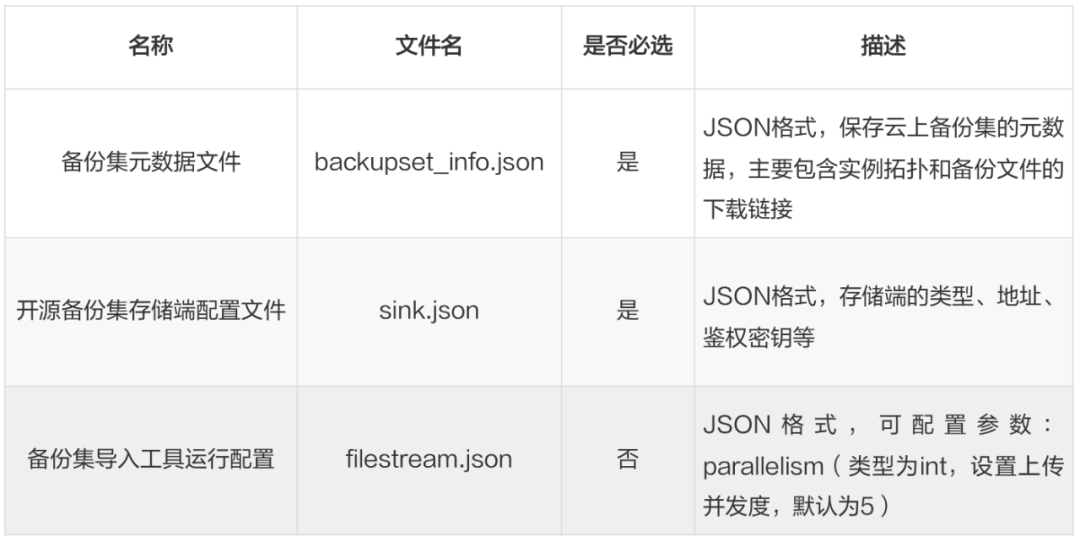
备份集元数据,可以通过商业备份集的OpenAPI DescribeOpenBackupSet,按要求输入接口参数 RegionId、DBInstanceName、RestoreTime,发起调用后可以获得完整的配置文本,比如包含备份集的物理文件、增量文件各自的下载地址;
备份存储地址,目前可以支持SFTP/MinIO/S3/Aliyun OSS等常见的备份存储介质,参考类似的备份元数据配置。 🔗https://doc.polardbx.com/zh/operator/ops/backup-restore/1-backup-storage-configure.html
运行备份转储的命令:
docker run -d -v /root/config:/config --network=host \
--name=polardbx-backupset-importer \
--entrypoint="/backupset-importer"
polardbx-opensource-registry.cn-beijing.cr.aliyuncs.com/polardbx/backupset-importer:v1.7.0 \
-conf=/config
备份转储任务,会通过商业备份集的元数据自动完成下载,并上传到指定的备份存储介质上。
另外,可以通过PolarDB-X Operator,基于k8s实现通过导入的备份集直接创建实例,参考基于导入的备份集做恢复。
🔗 https://doc.polardbx.com/zh/operator/ops/backup-restore/restore-business-backupset.html#基于导入的备份集做恢复
DDL在线变更
创建一张与原表结构一样的临时表
将具体变更操作应用到临时表上
将存量数据拷贝到临时表中
同步增量修改数据到临时表中
交换原表和临时表,完成变更
在增量数据同步方面,gh-ost 与 pt-osc 实现的方式有所不同,gh-ost 采用 binlog 订阅进行回放,而 pt-osc 采用的是利用触发器进行增量双写,但两种增量方案都并不完美。
语法格式:
ALTER TABLE tbl_name
alter_option [, alter_option] ...
ALGORITHM = OMC
实际demo例子:
# 创建测试表
CREATE TABLE t1(a int primary key, b tinyint, c varchar(10)) partition by key(a);
# 修改t1表中b列和c列的列类型
ALTER TABLE t1 MODIFY COLUMN b int, MODIFY COLUMN c varchar(30), ALGORITHM=OMC;
# 修改t1表中b列的名称和类型,并在该列后面增加一个bigint类型的e列
ALTER TABLE t1 CHANGE COLUMN b d int, ADD COLUMN e bigint AFTER d, ALGORITHM=OMC;
ALTER TABLE MODIFY COLUMN `sbtest1` MODIFY COLUMN k bigint;
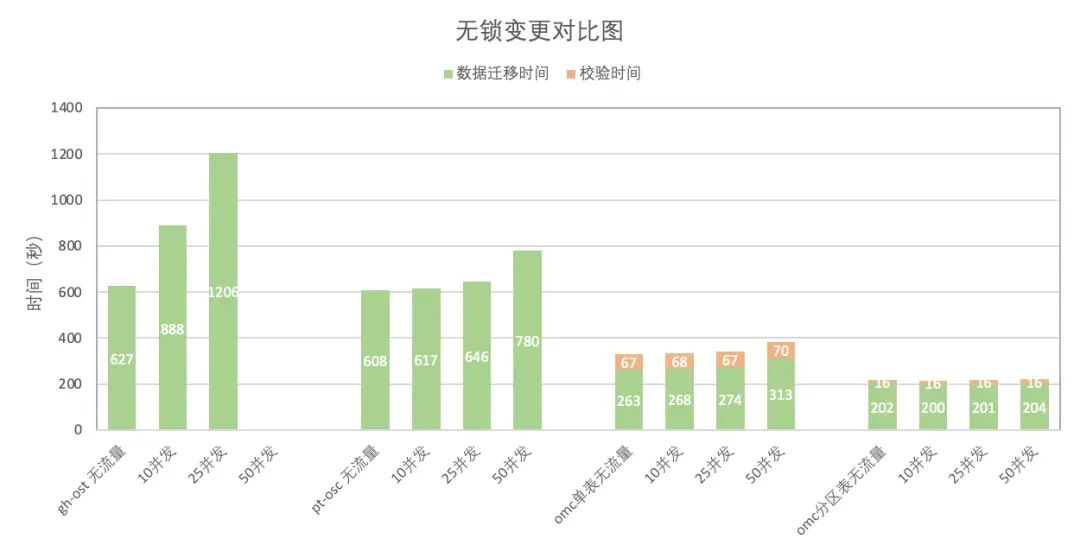
随着背景流量并发量的攀升,使用 gh-ost 工具的变更耗时显著增长,且当并发量达到 50 时,其增量回放已经没办法追上流量的修改,无法顺利完成变更;
即便在面临 50 并发的背景流量,pt-osc 工具依旧能够保证变更任务成功完成,但是变更时间会有所增加;
PolarDB-X 对分区表执行无锁列类型变更操作时,展现出了较高的稳定性与效率,其变更时长几乎不受背景流量波动的影响,并且所耗费的时间仅为 pt-osc 工具所需时间的三分之一;
PolarDB-X 对单表执行无锁列类型变更操作时,尽管其变更时长同样会随背景流量并发量的提升而有所增加,但相比 pt-osc 与 gh-ost,依然展现出较高的变更效率,耗时大幅缩减;
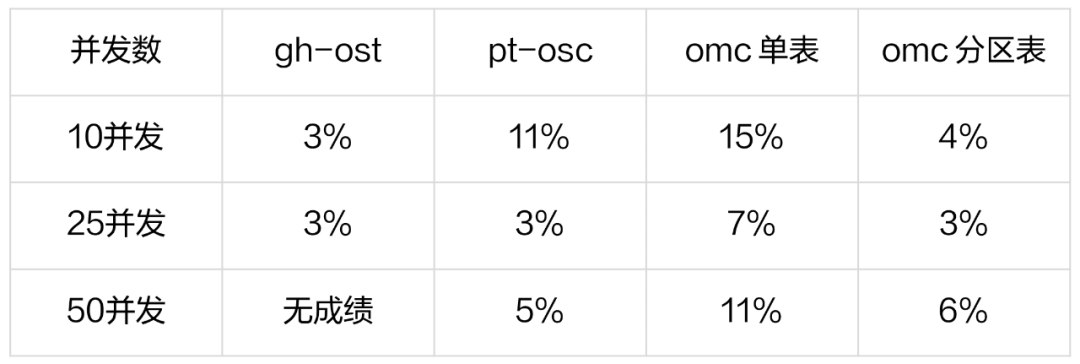
在变更操作期间,由于涉及一些资源的竞争,sysbench oltp_read_write工作负载会受到一定的影响,导致 TPS 会有所下滑,具体下降比率详情请参见下表:
物理扩缩容
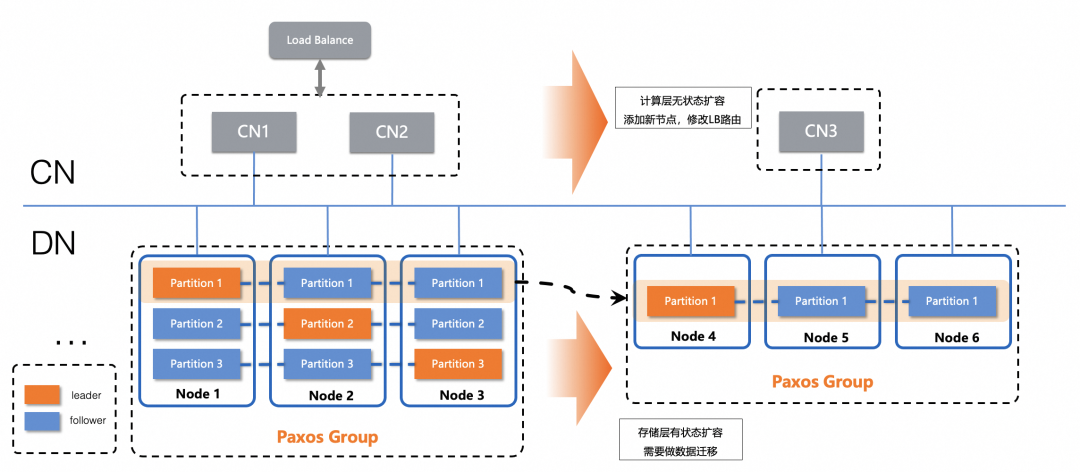
分布式数据库扩缩容的本质,就是数据分片的腾挪,整个过程涉及了全量+增量的组合。PolarDB-X v2.4.1版本,针对扩缩容能力做了全新的升级,数据腾挪的全量迁移方式,从原先默认的逻辑数据迁移演进到了基于物理文件迁移。
需要读取Leader节点,保证数据迁移的一致性,虽然仅是TableScan的读操作,也会对原节点有一定的CPU开销;
写入目标节点,采用了逻辑Insert的方式,虽然可以走Batch批量处理优化提交,但本质上还是需要逻辑迭代执行,CPU开销比较大,执行的效率不够快;
逻辑迁移,在分布式下的整体并行度不够大,没有充分发挥分布式多节点的效果,比如50个节点,一次性扩容25个节点,容易出现扩容耗时过长的问题。
数据读取,首先可以访问Follower节点,不对在线业务有影响,同时通过直接访问物理文件,不做逻辑解析,直接实现二进制的读取;
写入目标节点,同样采用物理写入,将数据读取的二进制流直接写入目标节点,实现类似物理文件二进制拷贝的效果,CPU仅需要处理网络转发和IO落盘的操作,并不需要处理逻辑迭代;
更大的并行度规划,引入了更确定的物理复制任务,可以将分布式的扩缩容拆分为多个物理复制的拷贝子任务的组合,通过MPP并行计算调度到多个节点,实现分布式的并行扩缩容。
# 开启物理复制迁移
set global physical_backfill_enable=true;
# 关闭物理复制迁移
set global physical_backfill_enable=false;
同时,我们设计了分布式大规模的扩缩容实验,实例规格:35个CN(8C32G) + 70个DN(8C32G),TPCC 50万仓(总计约45TB)
DN缩容,70节点缩容为40节点,涉及总数据量19.53TB,总耗时80分5秒,总的迁移速度4096MB/s,平均单节点135.6MB/s;
DN扩容,40节点扩容为70节点,涉及总数据量17.51TB,总耗时68分6秒,总的迁移速度4439.4MB/s,平均单节点149.8MB/s。
数据TTL
可以定时清理冷数据。
更低的冷数据存储成本。
归档后仍然可以供后台业务进行分析统计。
已有的数据表,配置TTL策略,比如:指定TTL的时间列及其数据的存活时间;
定义TTL的清理任务,比如:主动清理或者定时自动清理,以及关注清理任务的状态;
定义数据归档,比如:TTL默认可以只做数据清理,但也可以额外配置被清理的数据进行转储归档。

# 针对已有的数据表,动态配置TTL
ALTER TABLE `orders_test`
MODIFY TTL
SET
TTL_EXPR = `date_field` EXPIRE AFTER 2 MONTH TIMEZONE '+08:00';
指定orders_test表的date_field
列为TTL定义的时间列,只保存最近两个月的数据(数据过期时间为2个月),定时清理任务执行的时区为东八区。
手动执行
# 手动执行
ALTER TABLE `orders_test` CLEANUP EXPIRED DATA;
定时自动执行
# 定时执行,指定为每天的凌晨2点运行数据清理
ALTER TABLE `orders_test` MODIFY TTL \
SET TTL_JOB = CRON '0 0 2 */1 * ? *' TIMEZONE '+08:00';
# 创建数据归档的数据空间
CREATE TABLE `orders_test_archive`
LIKE `orders_test`
ENGINE = 'Columnar' ARCHIVE_MODE = 'TTL';
ENGINE的值必须为'Columnar',不允许其他值,代表使用列存引擎;
如果对原主库执行了DDL变更,比如加列,数据归档表也会自动执行加列,可以确保后续的归档任务不中断。
TTL原理概述
🔗 https://help.aliyun.com/zh/polardb/polardb-for-xscale/principle-overview
TTL表的定义与创建
TTL表的过期数据清理
🔗 https://help.aliyun.com/zh/polardb/polardb-for-xscale/ttl-table-expired-data-cleansing?
归档表语法说明
🔗 https://help.aliyun.com/zh/polardb/polardb-for-xscale/archive-table-syntax-description?
开源生态
项目地址:🔗 https://github.com/polardb/polardbx-sql

PolarDB-X Operator是基于K8S Operator架构,正式发布1.7.0版本,提供了PolarDB-X 数据库的部署和运维能力,生产环境优先推荐,可参考《PolarDB-X Operator运维指南》
PolarDB-X Operator 1.7.0新版本,重点适配了多云的部署能力,比如支持阿里云PolarDB-X商业备份集恢复、备份适配aws S3协议,融合了商业、开源与多云之间的关系,详见:ChangeLog。
🔗 https://github.com/polardb/polardbx-operator/releases/tag/v1.7.0
总结
PolarDB-X v2.4.1版本,重点增强企业级运维能力,面向DBA的数据库运维和数据管理,提供了更多有价值的能力,可以查看更多详细的Changelog:
另外,重要时刻:2024-09-30,中国信息安全测评中心发布安全可靠测评结果公告(2024年第2号),PolarDB-X【阿里云PolarDB数据库管理软件(分布式版)V2.0(简称:PolarDB 分布式版)】,首批通过分布式的安全可靠测评。更多内容可以点击文末「阅读原文」了解详情。




点击了解 PolarDB分布式版V2.0

