




梧桐数据库助力企业构建自主可控的企业级数据仓库
一、背景
随着互联网、物联网和移动设备的普及,数据的产生速度和规模达到了前所未有的高度。企业需要一种有效的方法来存储、管理和分析这些海量数据,从而做出更明智的决策。数据仓库成为解决这一问题的重要工具,它能够处理和分析海量数据,整合和优化企业日常运营中产生的交易数据、客户数据、市场数据等,使这些数据成为企业进行分析和决策的重要依据。随着数据量的不断增加,企业需要更新大规模计算分析能力构建数据仓库,分布式OLAP的数据库能够解决这一痛点,HADOOP+MPP构建企业级数据大数据处理平台和数据仓库的架构被广泛的应用。
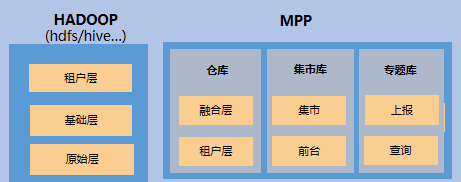
数据处理主要采用hadoop+mpp的模式,其中Hadoop承载基础数据处理和清单级数据处理,MPP承载着复杂计算和综合查询,随着数据的增长,MPP和Hadoop的存储需求不断增加,存储的温数据、冷数据不断增加;hive在查询效率方面存在短板。主要有如下痛点:
1、大数据的数据没有采用分级存储,其中历史数据且使用频率低的占了较大的空间。
2、MPP承载综合查询,需要存储大量的历史周期的冷数据、温数据。
3、HIVE查询效率低,无法承载大数据的数据分析查询场景;存储的冷数据无法被快速的使用,无法满足业务诉求。
二、新一代云原生架构的分布式数据库
基于发展演进的规划和面临的痛点问题,梧桐数据库应运而生,新一代的梧桐云原生分析型数据库(WuTongDB)作为中国移动自主开发的云原生数据库,兼具高扩展性、高并发能力、资源隔离、混合负载、快速计算引擎、安全保障等诸多优势,为企业数据管理提供了全新的解决方案。梧桐数据库能够帮助企业有效应对数据大爆炸和业务复杂性的难题。
梧桐数据库(WuTongDB) 是一款云原生架构的分布式数据库,支持高并发,高吞吐,高性能的弹性计算,支持多主节点,多虚拟计算集群和多虚拟存储集群,其整体架构分为存储节点、计算节点、管理节点,分别对应图中的存储层、计算层及服务层,数据库在任一层级上都可以水平扩展,实现存储与计算完全分离。
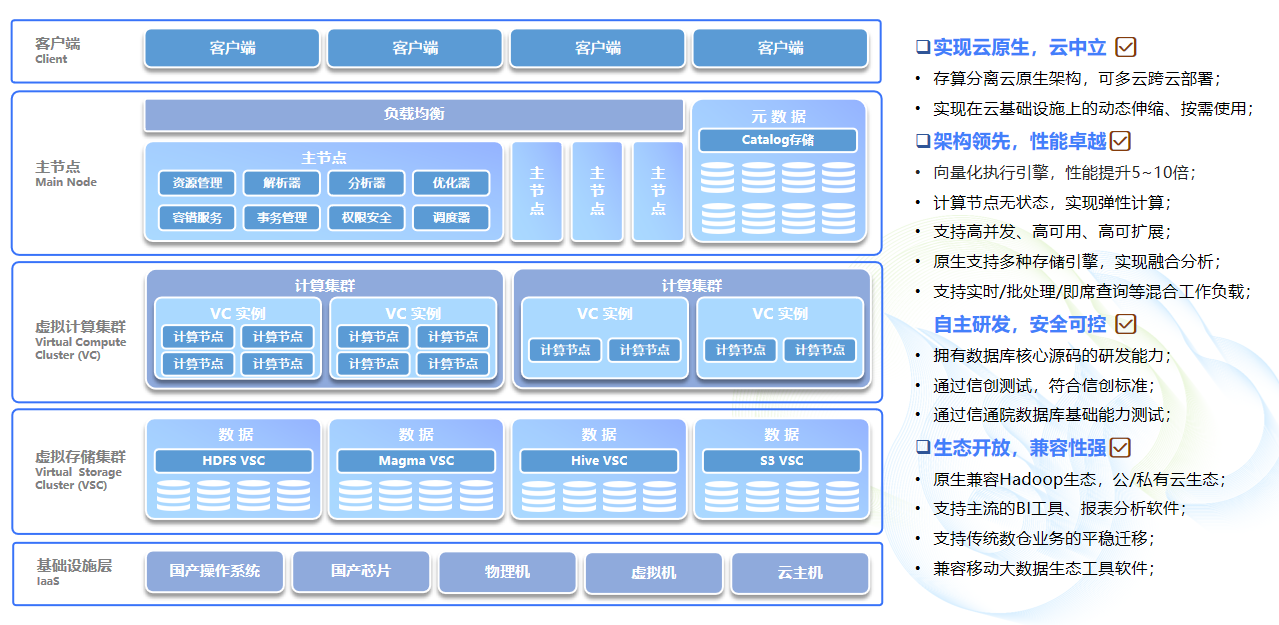
应用场景1:传统架构计算引擎升级换代
针对PB级数据分析场景下传统架构数据库查询效率低、扩容难、成本高、维护困难等痛点,新一代云原生数据库可为企业构建全业务核心数据仓库,具备高性能、高扩展、低成本、一站式分析等特性,提供自动化元数据/数据迁移工具,实现 Oracle、Teradata、Vertica 等传统数仓业务的平滑迁移。
应用场景2:支持企业构建一站式湖仓
新一代云原生数据库支持湖仓构建,可直接基于多个对象存储、不同Hadoop平台进行数据关联查询、处理、分析;对用户屏蔽底层存储细节,在数据分析查询层面形成统一服务;提供ODBC、JDBC、Spark/Flink connector等多种访问接口对接周边生态;从而避免数据孤岛,提供一站式湖仓能力。
- 主要做法
基于梧桐数据库的特性,结合企业大数据系统架构发展和演进,甘肃移动选型梧桐数据库做构建自主可控的企业级数据仓库,同时向湖仓一体演进。基于业务开发上线时间相比之前减少15%,核心业务的每秒事务数(TPS)总体提升20倍。
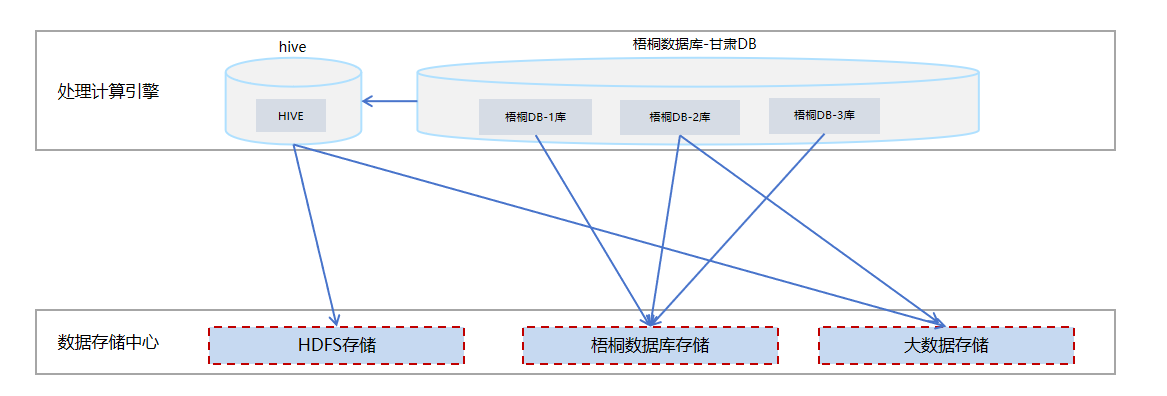
四、能力提升
通过利用湖仓一体的架构,多种存储融合使用,实现大数据更长周期的数据存储,降低存储成本。冷数据的在线使用,基于hive、梧桐DB等引擎,可以实现大数据冷数据的快速使用,更大程度满足数据分析的计算场景。大数据数据存储策略,形成大数据的冷热数据转存策略和方案,细化数据生命周期管理措施。
