






01
论文概述
检索不相关信息的影响:论文强调了检索不相关信息对于LLMs输出质量的显著负面影响,尤其是在需要利用模型内部知识有效回答问题的情况下。
检索增强生成(RAG)的局限性:论文指出,尽管RAG方法在特定领域问答系统中得到了广泛应用,但其在开放领域问答中存在明显的局限性,尤其是在处理不需要从本地数据集中检索数据的查询时。
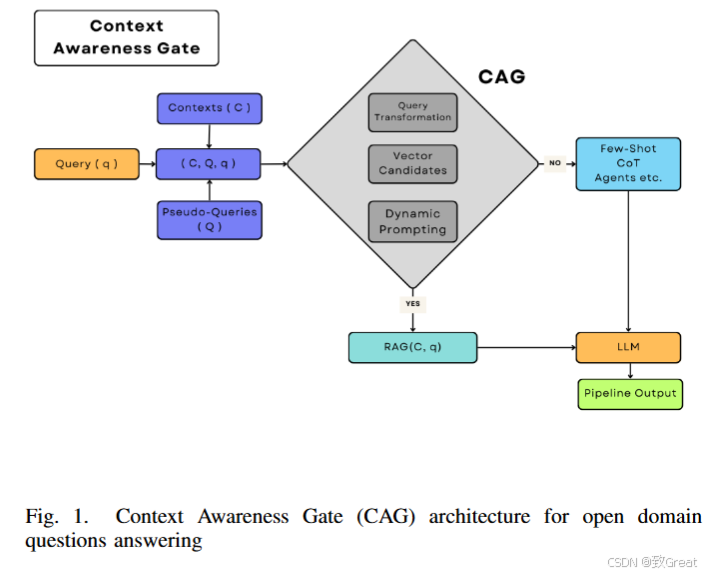
动态调整LLMs输入提示的需求:为了提高RAG系统在开放领域和封闭领域问答任务中的可靠性,论文提出了一种新的机制——上下文感知门(Context
Awareness Gate, CAG),它能够根据用户查询是否需要外部上下文检索来动态调整LLMs的输入提示。统计方法和可扩展性:论文还介绍了向量候选(Vector Candidates,
VC)方法,这是CAG的核心数学组件,它独立于LLMs,具有统计特性且高度可扩展。上下文与问题之间关系的分布分析:论文通过对上下文和问题之间关系的分布进行统计分析,提出了可以用于增强RAG系统中上下文检索过程的方法。
论文旨在通过提出CAG架构和VC方法,解决在开放领域问答中检索不相关信息的问题,从而提高LLMs在问答系统中的性能和输出质量。
02
相关工作
1. Query2Doc 和 HyDE:
03
核心内容

04
论文实验
SQuAD 数据集:使用SQuAD数据集进行实验,将CRSB作为本地数据集进行查询,以检验模型是否能够识别与数据集无关的查询,并避免使用RAG,转而使用LLM输入提示生成少量样本响应。 CRSB 数据集:将CRSB作为本地数据集进行查询,以验证模型是否能够识别需要上下文检索的查询,并根据RAG步骤检索相关数据。
上下文相关性 (Context Relevancy): 衡量检索到的上下文与用户查询的相关程度。 答案相关性 (Answer Relevancy): 衡量生成的答案与用户查询的相关程度。
基线模型:使用OpenAI GPT-4o mini作为问答基础模型。 CAG实现:实施了CAG架构,并与经典的RAG进行比较。 超参数设置:将95%密度分布设置为策略P,将阈值T设置为0,作为向量候选的超参数。
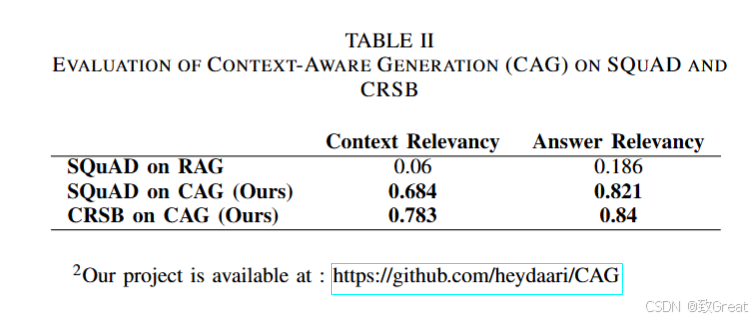
SQuAD数据集上的RAG:在SQuAD数据集上,基线模型RAG取得了0.06的上下文相关性和0.186的答案相关性,显示出在捕获和检索相关信息方面的显著局限性。
SQuAD数据集上的CAG:CAG方法显著提高了这些指标,达到了0.684的上下文相关性和0.821的答案相关性,表明模型在检索和理解上下文相关信息以及提供更准确答案方面的能力得到了显著增强。
CRSB数据集上的CAG:在CRSB数据集上应用CAG架构得到了更强的结果,上下文相关性达到0.783,答案相关性上升到0.84,表明该方法不仅跨数据集泛化良好,而且显著增强了系统的整体理解和开放领域问答能力。
05
编者介绍
项目链接:https://github.com/gomate-community/GoMate
