





在处理海量数据的环境中,如何高效地连接数据库与应用程序,无疑是提升系统整体性能的关键因素之一。为此,我们特别策划了本期内容,专为希望优化 Java 应用与 OceanBase 数据库之间连接的开发者打造,涵盖了 JDBC 连接参数设置、Druid 连接池的使用技巧等关键要点。在复杂的数据库应用场景中,良好的连接配置不仅能确保应用程序的稳定性,还能显著提高其运行效率和资源利用率。本文将带您全面掌握 JDBC 的基础配置、连接池的管理方式、连接探活的实现细节等关键概念。
通过本文,您将深入了解如何高效管理连接资源、减少连接开销,并掌握一系列确保系统稳定性的具体配置操作。
该指导适用于 OceanBase 数据库 V2.x、V3.x 和 V4.x 版本。
一、关键概念
为确保应用程序与 OceanBase 数据库之间的连接既稳定又高效,并确保安全性,您可以了解以下关键概念和原理:
1、JDBC(Java Database Connectivity)
JDBC 是一种用于 Java 应用程序与数据库交互的 API(应用程序接口),提供一组标准的接口,允许 Java 程序执行 SQL 语句、获取查询结果及处理数据库事务。
2、连接池(Connection Pool)
连接池是一种管理数据库连接的技术。它维持了一个预先创建的数据库连接集,应用程序在需要时可从中获取连接,并在使用完成后将连接返还,借此重用连接并减少连接的创建与销毁开销。
应用程序启动时会创建多个数据库连接并保存在内存中;当需要数据库连接时,从连接池中获取一个空闲连接,使用完毕后归还给连接池。这种机制显著减少了连接数据库的时间,提高了应用程序的性能和资源利用率。常见的连接池实现包括 Druid、DBCP、C3P0 等。
3、连接探活
定期检测数据库连接的有效性,以防止应用程序使用失效连接,从而提高系统稳定性。可通过配置 testWhileIdle、testOnBorrow 和 testOnReturn 来实现连接的探活机制。
了解以上关键概念后,请继续阅读本文,掌握将应用程序与数据库驱动相连接的具体配置项,这些配置是确保系统稳定性和性能的关键所在。
二、应用程序与数据库驱动配置
在进行应用程序与 OceanBase 数据库交互时,合适的驱动配置能极大提高系统的稳定性与性能。以下是一些主要的配置项:
1、连接超时设置:设置客户端连接数据库的等待时间,例如配置 connectTimeout 和 socketTimeout。同时,要实施快速失败重试机制,确保在连接失败时能迅速重试,并设定连接间隔时间,以减少网络阻塞和系统负载。、
2、日志记录:在程序运行期间,应记录连接数据库的 OceanBase 错误码及连接信息(如 IP、PORT、用户名),以便 DBA 快速诊断和解决问题。
3、版本兼容性:确保客户端库(如 .so 或 .jar 包)与数据库服务器版本兼容,以保证各组件间的正确协作。
4、切换数据库方法:推荐使用 Connection.setCatalog(dbname) 接口,而非 SQL 命令 use,以提高代码的可读性和维护性。
5、Session 状态变量设置:通过 JDBC 接口(如 setAutoCommit、setReadOnly、setTransactionIsolation)来设置 Session 状态变量,以减少 SQL 使用频率,降低数据库交互次数并提升性能。
6、事务处理:在执行单个事务(无论是单条 SQL 还是多条 SQL)之前,重新获取数据库连接(getConnection),事务执行完毕后,关闭连接(closeConnection)。确保每个事务独立处理,以防止连接复用导致的状态污染,确保数据的一致性和隔离性。
通过合理配置以上项,能够显著提升 OceanBase 数据库与应用程序之间的交互效率和稳定性。在后续章节中,我们将深入探讨一些具体的配置参数和示例,帮助您实现最佳的系统架构。
三、JDBC 连接配置
本节将详细介绍在配置 JDBC 连接数据库时的重要参数。用户可以将这些参数配置到连接池的 ConnectionProperties 中,也可以直接写入 JdbcUrl 中。为了统一管理,推荐在连接池中进行配置。
(一)JDBC 连接示例
JDBC 连接示例如下所示,您可以通过具体的 URL 进行数据库连接:
conn = jdbc:mysql://x.x.x.x(ip):xx(port)/xxxx(dbname)?rewriteBatchedStatements=true&allowMultiQueries=true&useLocalSessionState=true&useUnicode=true&characterEncoding=utf-8&socketTimeout=3000000&connectTimeout=60000接下来,我们将详细解析 JDBC 连接示例 中各个参数配置的含义及其作用,以帮助您更好地理解和使用。
1、jdbc:mysql://x.x.x.x(ip):xx(port)/xxxx(dbname)
✅ x.x.x.x (ip): 数据库服务器的 IP 地址。确保该地址是数据库服务器的真实地址。
✅ xx(port): 数据库服务监听的端口,MySQL 默认端口为 3306。
✅ xxxx(dbname): 要连接的具体数据库名称。确保在连接之前数据库已存在且用户有足够的权限访问。
2、rewriteBatchedStatements=true
这个参数用于优化批量更新操作。当启用此选项时,JDBC 驱动程序会将批处理语句重写成一次性 SQL 语句,从而减少与数据库的交互次数,提高性能。
3、allowMultiQueries=true
该参数允许在单个 Statement 语句中执行多个 SQL 查询。虽然这可以提高执行效率,但也可能导致 SQL 注入风险,应谨慎使用。在处理用户输入时务必进行严格的验证和清理。
4、useLocalSessionState=true
当启用该选项时,MySQL JDBC 驱动程序将使用本地会话状态,这样在发送状态变化时不会立即与数据库同步,优化了一些操作的执行速度。
5、useUnicode=true
启用此选项后,JDBC 驱动程序将使用 Unicode 字符集进行字符串的输入和输出,确保可以正确处理非 ASCII 字符,如中文或其他语言的字符。
6、characterEncoding=utf-8
指定数据库连接使用的字符编码为 UTF-8。这是一个通用的字符集,可以支持多种语言的字符,避免在数据传输过程中出现乱码的情况。
7、socketTimeout=3000000
这个参数设置了超时时间(以毫秒为单位)。如果在指定时间内没有进行任何数据传输,连接将会被自动关闭。
8、connectTimeout=60000
该参数定义了客户端与数据库服务器建立连接时的超时时间(同样以毫秒为单位)。如果在这个时间内无法成功连接,则会抛出异常。
接下来,我们将详细解析 JDBC 连接示例中的各个参数配置。
(二)超时配置
在 JDBC 连接示例中,可以配置以下参数:
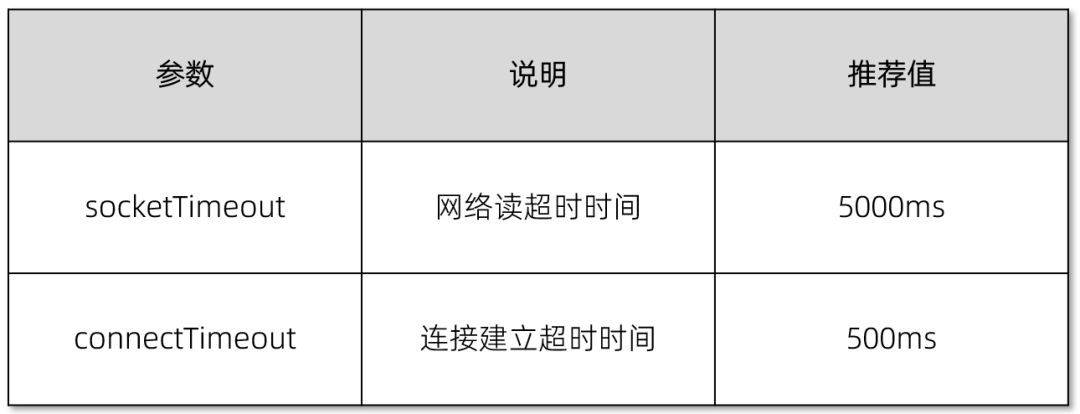
✅ 建议设置 socketTimeout ,并根据应用特点进行调整。如果不设置,系统将使用默认超时时间 0ms,即永不超时。
✅ 建议设置 connectTimeout,并根据应用特点进行调整。如果不设置,系统将使用默认连接建立超时时间 30000ms。
✅ 通过 OceanBase 数据库的 Session 变量 ob_query_timeout 和 ob_trx_timeout 控制 SQL 超时时间。
(三)Session 变量配置
在 JDBC 连接示例中,可以配置以下参数:

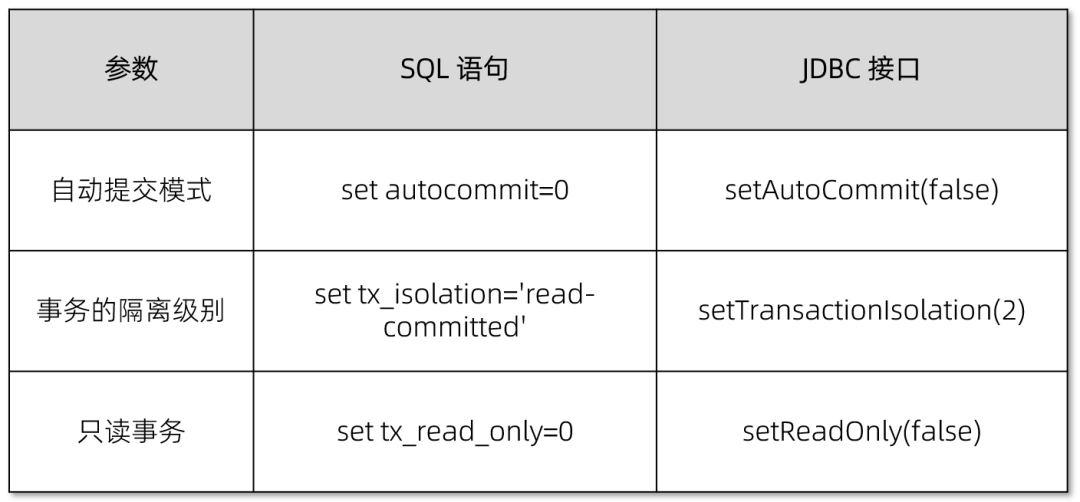
✅ 强烈建议将 useLocalSessionState 设置为 true,使用本地的 Session 状态变量以减少应用与数据库之间的交互,从而提升交易性能。在使用 M有SQL JDBC 连接 OceanBase 时可以设置此参数;而 OceanBase JDBC 不支持该参数。
✅ 本地 Session 状态变量包括 autocommit、read_only 和 transaction isolation。
✅ 注意,使用本地 Session 状态变量的前提是通过 JDBC 接口而非 SQL 语句来设置这些状态变量。
(四)批量执行优化参数设置
在云和分布式数据库环境中,应用服务器与数据库服务器之间的网络链路较长,因此网络延迟对交易性能至关重要。为此,高效的应用编码应尽量采用批量执行方法,减少与数据库的多次交互。
下面列出了一些重要的 JDBC 参数设置,这些参数不仅影响批量执行的行为,同时也关系到应用程序与数据库之间的交互效率:
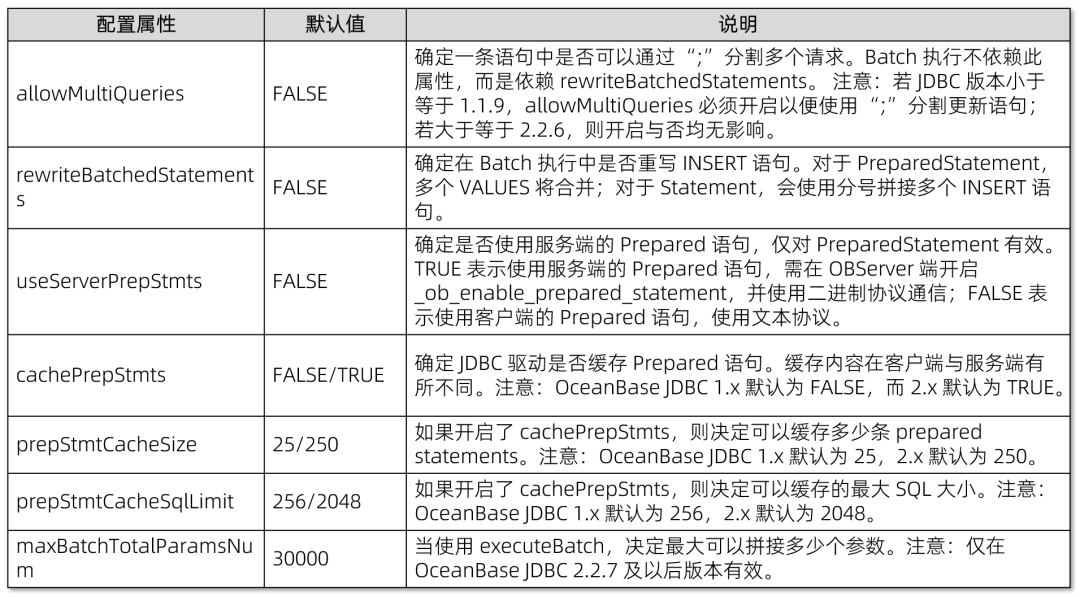
无论您选择使用 Statement 还是 PreparedStatement,均可实现 Batch 执行。接下来,我们将分别展示如何使用这两种对象进行批量执行,以实践上述配置对性能的提升。
1、使用 PreparedStatement 对象
首先,我们通过 PreparedStatement 开始实现批量执行。以下是一个示例代码,展示了如何在一个事务中插入多条记录:
conn = DriverManager.getConnection(obUrl);conn.setAutoCommit(false);String SQL = "INSERT INTO TEST1 (C1, C2) VALUES (?, ?)";PreparedStatement pstmt = conn.prepareStatement(SQL);int rowCount = 5, batchCount = 10;for (int k = 1; k <= batchCount; k++) {for (int i = 1; i <= rowCount; i++) {pstmt.setInt(1, (k * 100 + i));pstmt.setString(2, "test value");pstmt.addBatch();}int[] count = pstmt.executeBatch();pstmt.clearBatch();}conn.commit();pstmt.close();
在使用 PreparedStatement 时,Batch 执行的行为会有所不同,具体如下:
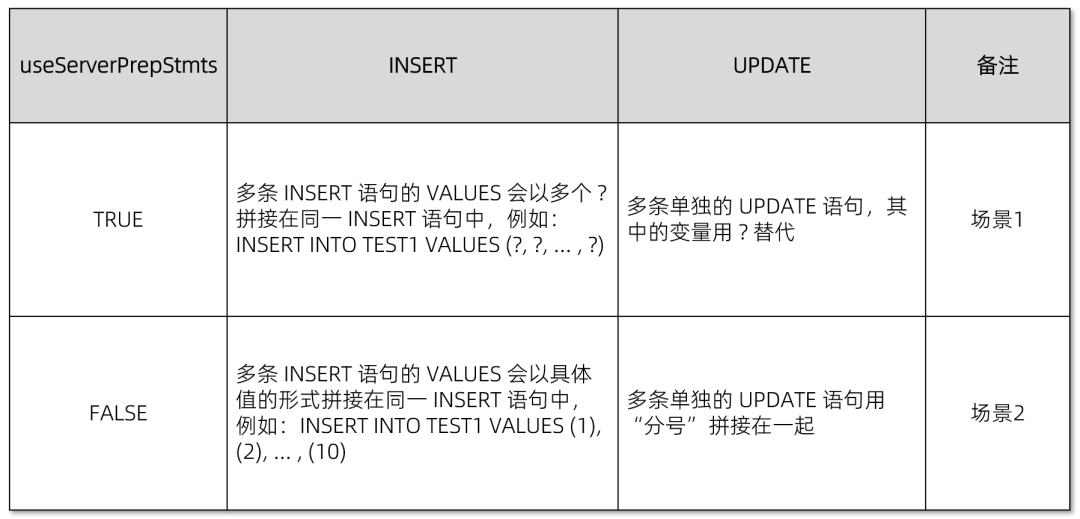
2、使用 Statement 对象
我们也可以通过 Statement 对象实现批量执行。以下是一个代码示例,展示了如何使用 Statement 来插入多条记录:
conn = DriverManager.getConnection(obUrl);conn.setAutoCommit(false);Statement stmt = conn.createStatement();String SQL1 = "INSERT INTO test1 (c1, c2) VALUES (1, 'test11')";stmt.addBatch(SQL1);String SQL2 = "INSERT INTO test1 (c1, c2) VALUES (2, 'test12')";stmt.addBatch(SQL2);String SQL3 = "INSERT INTO test1 (c1, c2) VALUES (3, 'test13')";stmt.addBatch(SQL3);int[] count = stmt.executeBatch();stmt.clearBatch();conn.commit();
与 PreparedStatement 相比,使用 Statement 对象的批量执行行为如下所示:
(五)如何在不同场景中选择适当的配置?
在前面的讨论中,我们提到了 Statement 对象在批量插入和更新中的基本用法。接下来的部分将更深入地探讨在不同场景中如何选择合适的配置,以充分利用批量执行的性能。
1、批量插入(Batch INSERT)
在场景 1 和场景 2 中,可以更有效地利用批量执行性能,建议使用以下配置:
💡 场景 1:
📕 JDBC 对象:
PreparedStatement 对象📕 服务端参数:
_ob_enable_prepared_statement=TRUE📕 JDBC 配置属性:
rewriteBatchedStatements=TRUEuseServerPrepStmts=TRUEcachePrepStmts=TRUEprepStmtCacheSize=<根据实际情况>prepStmtCacheSqlLimit=<根据实际情况>maxBatchTotalParamsNum=<根据实际情况>
💡 场景 2:
📕 JDBC 对象:
PreparedStatement 对象📕 JDBC 配置属性:
rewriteBatchedStatements=TRUEuseServerPrepStmts=FALSE
2、批量更新(Batch UPDATE)
接下来,我们将讨论在场景 2、场景 3 和场景 4 中进行批量更新的建议配置。使用文本协议通信可以有效利用多条 UPDATE 语句的批处理功能,因此应采用以下配置:
💡 场景 2:
📕 JDBC 对象:
PreparedStatement 对象📕 服务端参数:
ob_enable_batched_multi_statement=TRUE_enable_static_typing_engine=TRUE(OceanBase V3.2 需要)
📕 服务端变量:
_enable_dist_data_access_service=1(OceanBase 3.2 需要)📕 JDBC 配置属性:
rewriteBatchedStatements=TRUEuseServerPrepStmts=FALSEallowMultiQueries=TRUE(避免 JDBC 驱动不同版本之间的行为差异)
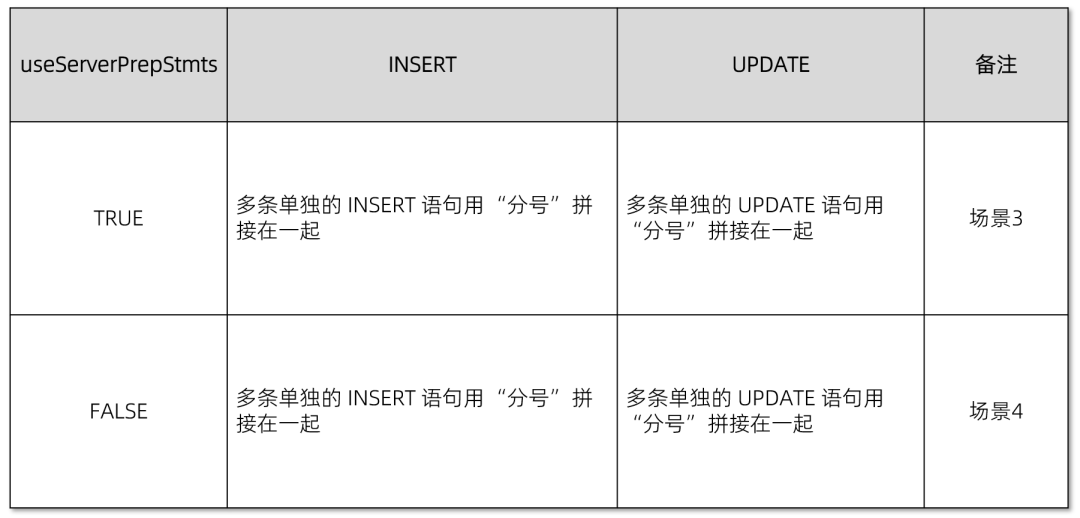
💡 场景 3 和 4:
另外,在场景 3 和场景 4 中,我们建议采用以下配置以支持批量更新:
📕 JDBC 对象:
Statement 对象📕 服务端参数:
ob_enable_batched_multi_statement=TRUE_enable_static_typing_engine=TRUE(OceanBase 3.2 需要)
📕 服务端变量:
_enable_dist_data_access_service=1(OceanBase 3.2 需要)📕 JDBC 配置属性:
rewriteBatchedStatements=TRUEallowMultiQueries=TRUE(避免 JDBC 驱动不同版本之间的行为差异)
通过明确每种场景下的配置推荐,我们可以更有效地利用 JDBC 的批量执行性能,提升数据操作的效率。
四、OceanBase 批量执行优化
在 OceanBase 数据库中,以下配置项与批量执行相关:
从操作语句看,OceanBase 对 INSERT、UPDATE 和 DELETE 的 Batch 执行处理存在差异:
(一)INSERT
首先,在处理 INSERT 时,有几个关键场景值得关注:
场景 1:
OceanBase 服务器接收到一次 INSERT 的 COM_STMT_PREPARE 请求(request_type=5)和一次 COM_STMT_EXECUTE 请求(request_type=6)。此种优化带来的好处包括:
👉 仅需进行两次通信即可完成 INSERT 的 Batch 执行。
👉 PreparedStatement 减少了编译时间。
👉 如果后续有多次 executeBatch,并合理设置 cachePrepStmts 等参数,将减少 prepare 请求(request_type=5)的次数,仅需执行 execute 请求(request_type=6)。
场景 2:
另一方面,若 OceanBase 服务端收到一次 INSERT 的 COM_QUERY 请求(request_type=2),带来的优化效果是:
👉 仅需一次通信即可完成 INSERT 的 Batch 执行。
场景 3/4:
服务器接收到多个以 “;” 连接的 INSERT 语句请求,并按顺序执行,同样实现了:
👉 仅需一次通信完成 INSERT 的 Batch 执行。
(二)UPDATE
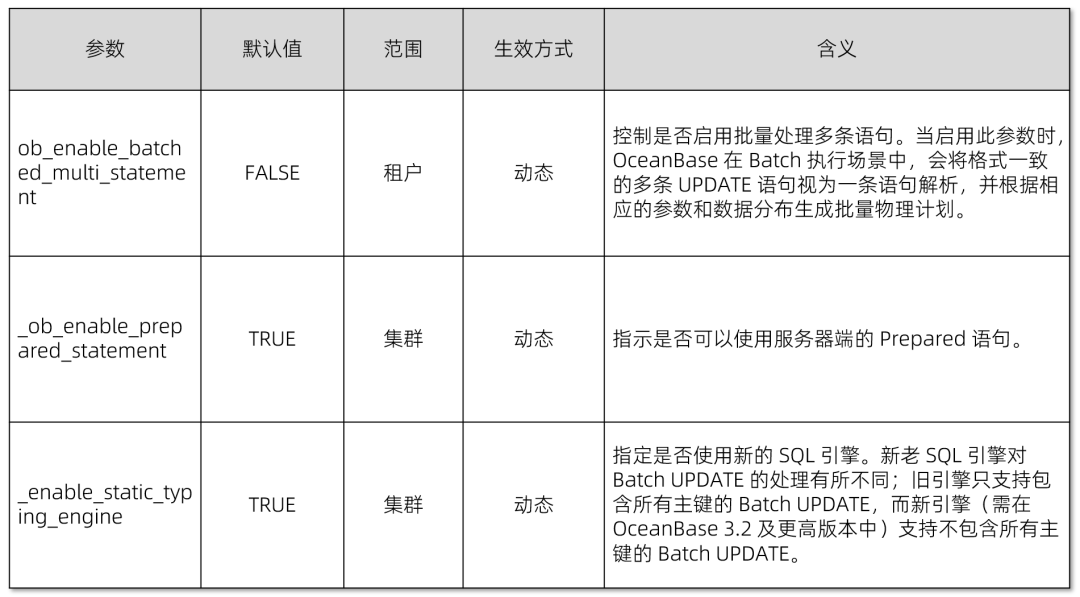
在处理 UPDATE 时,情况有所不同。首先,在未启用 ob_enable_batched_multi_statement 时,场景 1/2/3/4 的 Batch UPDATE 在 OceanBase 服务器端将依次执行,未实现特别优化。然而,启用 ob_enable_batched_multi_statement 后,针对场景 2/3/4 的 Batch UPDATE,OceanBase 会将格式一致的多条 UPDATE 语句视为一条进行解析。生成的批量物理计划能显著提升执行效率。需要特别注意的是:
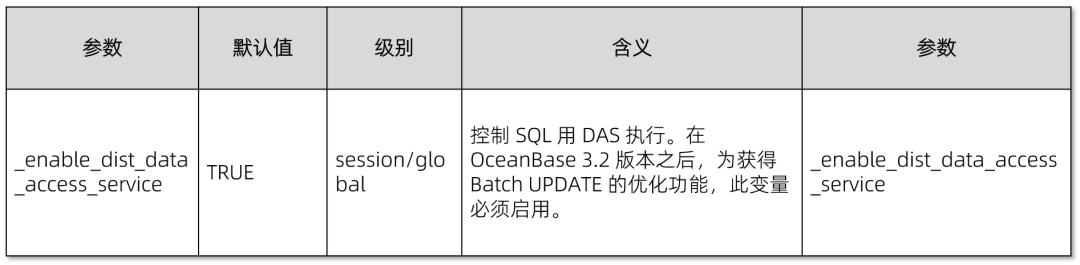
👉 在 OceanBase V3.1 版本中,仅支持谓语中包含所有主键的优化;而在 OceanBase 3.2 (需较新分支)中,可无此限制,但需启用 _enable_dist_data_access_service 变量并启动新 SQL 引擎。
👉 同一批次 UPDATE 中不能有相同的行。
👉 必须开启显式事务。
(三)DELETE
在 OceanBase V3.x 版本中对 Batch DELETE 的处理为依次执行,而 OceanBase V4.x 对 DELETE 语句进行了优化。
(四)如何检查 OceanBase 的 Batch 执行状态?
检查 Batch 执行的有效性,最常用的方法是通过 gv$sql_audit。以下是不同场景的示例:
1、场景 1 的 Batch INSERT 生效时:
query_sql: insert into test_multi_queries (c1, c2) values (?, ?)request_type: 5ps_stmt_id: 1query_sql: insert into test_multi_queries (c1, c2) values (?, ?),(?, ?),(?, ?)request_type: 5ps_stmt_id: 2request_type: 6
2、场景 2 的 Batch INSERT 生效时:
query_sql: insert into test_multi_queries (c1, c2) values (1, 'PreparedStatement; rewriteBatchedStatements=true&allowMultiQueries=true&useLocalSessionState=true'),(2, ...),(3, ...)3、场景 2 的 Batch UPDATE 生效时:
query_sql: update test2 set c2='batch update1' where c1=1; update test2 set c2='batch update2' where c1=2; ...ret_code: 0is_batched_multi_stmt: 1
🧡注意:
若 ret_code=-5787,表明 Batch UPDATE 未成功,需要根据上述说明查找原因。
(五)Batch 执行时,executeBatch 方法返回值
调用 executeBatch 后,会返回一个整型数组 int[],对于 Batch INSERT 和 Batch UPDATE:
👉 如果在 OceanBase 端最终是逐条执行的,数组将返回每个操作所修改的行数。
👉 若作为整体执行(如将多条 INSERT 语句合并或 UPDATE 语句执行为批量物理计划),则每个元素返回 -2,表示执行成功但更新行数未知。
(六)结果集处理
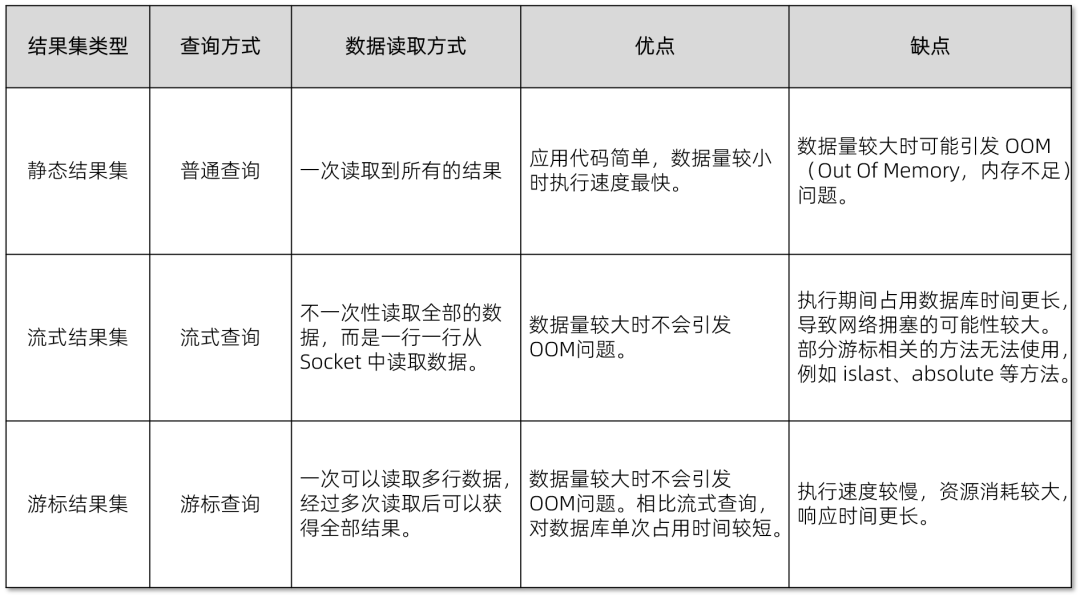
在结果集返回时,OceanBase 支持三种方式:静态结果集、流式结果集和游标结果集。
👉 静态结果集(RowDataStatic):默认的方式,适用于普通查询。
👉 流式结果集(RowDataDynamic):逐行查询数据,更适合大数据量场景。
👉 游标结果集(RowDataCursor):基于游标的查询方式,适合多行数据的处理。
(七)不同类型结果集的优劣比较
对于不同类型结果集的特性,我们可以总结如下:
(八)不同类型结果集的使用方法
针对不同类型结果集,我们可以如下配置:
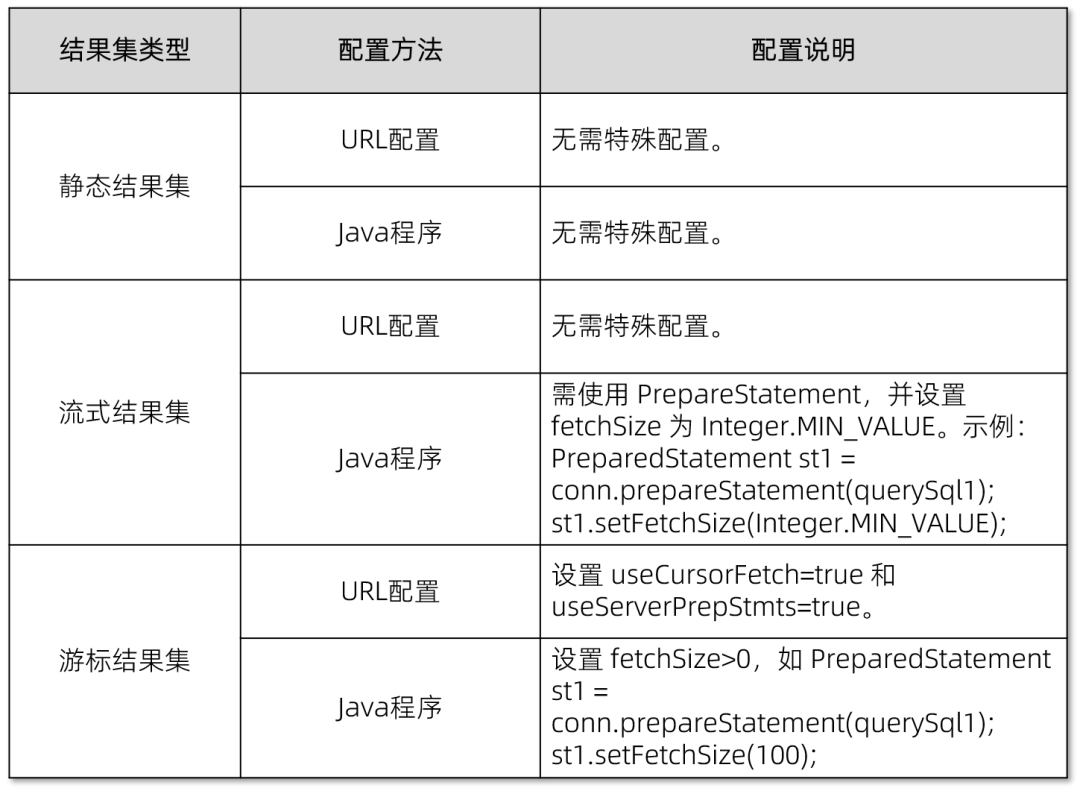
🚩 JDBC 参数 useCursorFetch:

🧡 注意:
设置 useCursorFetch=true 将自动启用 useServerPrepStmts=true。
(九)结果集处理建议
根据结果集大小选择相应的处理方式:
👉 小数据量查询:使用静态结果集。
👉 大数据量场景:应控制结果集大小(如分页),采用游标或流式结果集。
(十)注意事项与说明
👉 在 MySQL 租户模式下,设置 ResultSet.TYPE_SCROLL_INSENSITIVE 会使用全量结果集。
👉 URL 中设置 useCursorFetch=true 时,useServerPrepStmts 被强制设置为 true;如需批量更新,请配置独立数据源(因更新批量优化依赖 useServerPrepStmts=false)。
👉 MySQL RENTAL 游标结果集限制 ps 参数为 65535,需避免超限。
👉 流式结果集下,部分游标相关接口不可用,例如 isLast()、absolute() 等方法。
👉 如果客户端处理缓慢,且服务器未向 IO 写数据,可能导致超时(数据库写数据时会刷新超时时间,由 net_write_timeout 控制,默认 60s)。可通过 JDBC URL 设置 netTimeoutForStreamingResults 来避免超时,默认值为 600s。
👉 在大数据量情况下,游标结果集的 Observer 侧需落盘,execute 后的第一个响应可能较慢。
(十一)配置示例
1、使用游标结果集
PreparedStatement st1 = conn.prepareStatement(querySql1);st1.setFetchSize(100);
2、使用流式结果集
PreparedStatement st1 = conn.prepareStatement(querySql1);st1.setFetchSize(Integer.MIN_VALUE);
五、应用连接池配置优化指南
(一)基本连接池参数概述
为了确保数据库连接的高效管理,以下是一些重要的连接池参数:
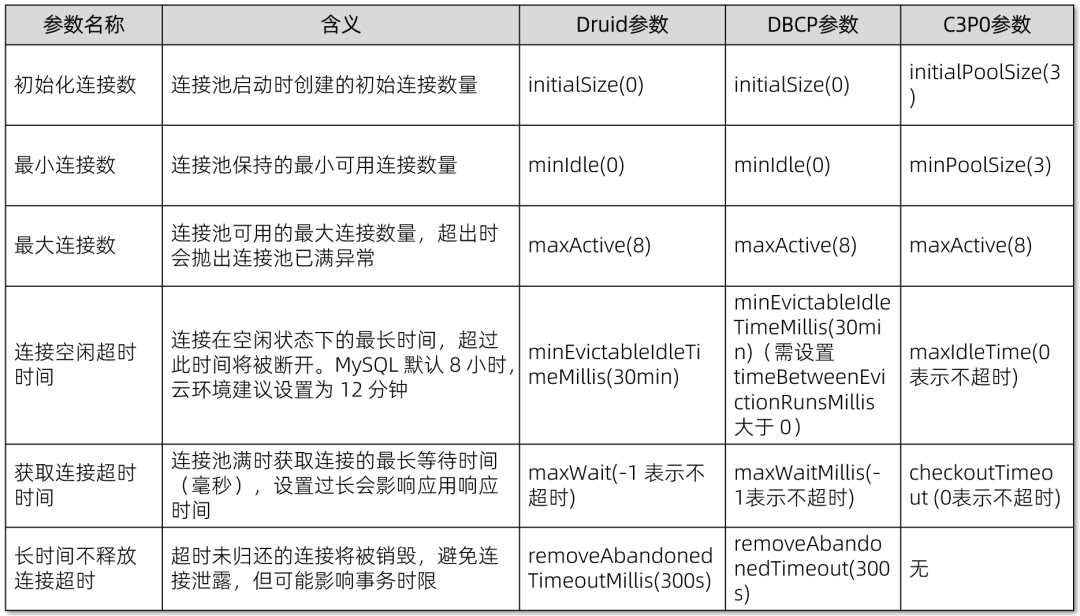
(二)连接池设置建议
为了获得最佳的性能,建议:
👉 控制台日常连接数建议设置为 2,具体值可根据业务并发和事务时间调整。
👉 推荐设置连接空闲超时时间为 30 分钟。
👉 通过心跳、testOnBorrow 等机制定期校验连接的有效性,确保在超时时间内未使用的连接被主动断开。
(三)Druid 连接池配置
对于 Java 程序,建议使用 Druid 连接池,版本要求为 V1.2.8 及以上。
1、Druid 连接池主要参数配置示例
maxActive: 100initialSize: 5maxWait: 10000minIdle: 5timeBetweenEvictionRunsMillis: 60000minEvictableIdleTimeMillis: 300000maxEvictableIdleTimeMillis: 1800000validationQuery: select 1;testWhileIdle: truetestOnBorrow: truetestOnReturn: falseremoveAbandoned: falseremoveAbandonedTimeout: 180
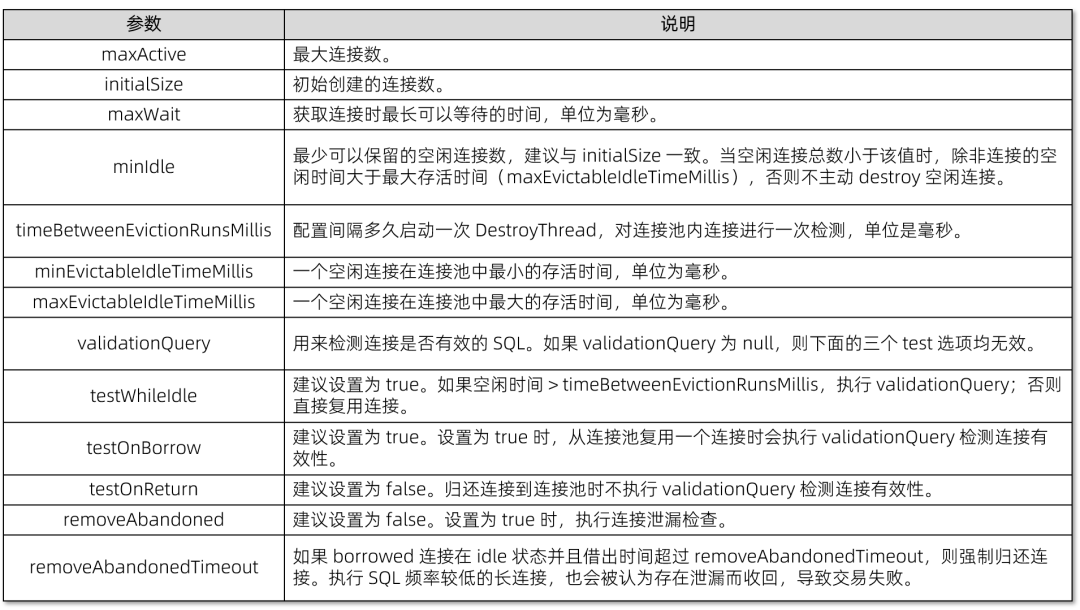
2、Druid 连接池参数说明
以下是参数说明的整理表格:
3、Druid 连接池完整示例
📕 添加 Maven 依赖:
<dependency><groupId>com.alibaba</groupId><artifactId>druid</artifactId><version>1.2.8</version></dependency>
📕 配置样例:
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close"><!-- 基本属性 url、user、password --><property name="url" value="${jdbc_url}" /><property name="username" value="${jdbc_user}" /><property name="password" value="${jdbc_password}" /><!-- 连接池基本配置 --><property name="initialSize" value="20" /><property name="minIdle" value="10" /><property name="maxActive" value="100" /><property name="maxWait" value="1000" /><property name="timeBetweenEvictionRunsMillis" value="60000" /><property name="minEvictableIdleTimeMillis" value="300000" /><property name="testOnBorrow" value="true" /><property name="testOnReturn" value="false" /><property name="testWhileIdle" value="true" /><property name="validationQuery" value="select 1 from dual" /><property name="keepAlive" value="true" /><!-- 各种配置可根据业务需求适当调整 --></bean>
(四)其他连接池配置示例
1、DBCP 连接池
📕 添加依赖:
<dependencies><dependency><groupId>com.alipay.oceanbase</groupId><artifactId>oceanbase-client</artifactId><version>3.2.3</version></dependency><dependency><groupId>org.apache.commons</groupId><artifactId>commons-pool2</artifactId><version>2.7.0</version></dependency><dependency><groupId>commons-logging</groupId><artifactId>commons-logging</artifactId><version>1.2</version></dependency><dependency><groupId>org.apache.commons</groupId><artifactId>commons-dbcp2</artifactId><version>2.7.0</version></dependency><dependency><groupId>org.junit.jupiter</groupId><artifactId>junit-jupiter-api</artifactId><version>5.7.0</version></dependency></dependencies>
📕 配置文件示例(dbcp.properties):
driverClassName=com.alipay.oceanbase.jdbc.Driverurl=jdbc:oceanbase://10.100.xxx.xxx:18817/test?useSSL=false&useServerPrepStmts=true&serverTimezone=UTCusername=$user_namepassword=******initialSize=30maxTotal=30maxIdle=10minIdle=5maxWaitMillis=1000removeAbandonedOnMaintenance=trueremoveAbandonedOnBorrow=trueremoveAbandonedTimeout=1
2、C3P0 连接池
📕 添加依赖:
<dependency><groupId>com.mchange</groupId><artifactId>c3p0</artifactId><version>0.9.5</version></dependency>
📕 示例代码:
import com.mchange.v2.c3p0.ComboPooledDataSource;import java.beans.PropertyVetoException;import java.sql.Connection;import java.sql.PreparedStatement;import java.sql.ResultSet;import java.sql.SQLException;public class C3P0PoolTest {private static ComboPooledDataSource dataSource = new ComboPooledDataSource("oboracle");public void init() throws PropertyVetoException {dataSource.setDriverClass("com.oceanbase.jdbc.Driver");dataSource.setJdbcUrl("jdbc:oceanbase://10.100.xxx.xxx:30035/test?useSSL=false");dataSource.setUser("test@tt3");dataSource.setPassword("test");dataSource.setInitialPoolSize(3);dataSource.setMaxPoolSize(10);dataSource.setMinPoolSize(3);dataSource.setAcquireIncrement(3);}public void testInsert() throws SQLException, PropertyVetoException {init();try (Connection connection = dataSource.getConnection()) {connection.setAutoCommit(false);connection.prepareStatement("create table t1(c1 binary_double)").execute();try (PreparedStatement ps = connection.prepareStatement("insert into t1 values('2.0')")) {ps.execute();}try (ResultSet resultSet = connection.createStatement().executeQuery("select * from t1")) {while (resultSet.next()) {int count = resultSet.getMetaData().getColumnCount();for (int i = 1; i <= count; i++) {System.out.println(resultSet.getMetaData().getColumnName(i) + ":" + resultSet.getString(i));}}}}}}
3、Tomcat 连接池
📕 配置文件示例:
<Resource name="jdbc"auth="Container"type="javax.sql.DataSource"maxActive="100"maxIdle="30"maxWait="10000"username="root"password=""driverClassName="com.oceanbase.jdbc.Driver"url="jdbc:oceanbase://10.100.xxx.xxx:18815/test?characterEncoding=UTF-8" />
📕 在项目的 web.xml 中进行配置:
<resource-ref><res-ref-name>jdbc</res-ref-name><res-type>javax.sql.DataSource</res-type><res-auth>Container</res-auth></resource-ref>
3、Proxool 连接池
📕 添加依赖:
<dependency><groupId>proxool</groupId><artifactId>proxool-cglib</artifactId><version>0.9.1</version></dependency><dependency><groupId>proxool</groupId><artifactId>proxool</artifactId><version>0.9.1_20141120</version></dependency>
📕 配置文件示例:
jdbc-1.proxool.alias=testjdbc-1.proxool.driver-class=com.oceanbase.jdbc.Driverjdbc-1.proxool.driver-url=jdbc:oceanbase://10.100.xxx.xxx:30035/testjdbc-1.user=test@tt3jdbc-1.password=testjdbc-1.proxool.maximum-connection-count=8jdbc-1.proxool.minimum-connection-count=5jdbc-1.proxool.prototype-count=4jdbc-1.proxool.verbose=truejdbc-1.proxool.statistics=10s,1m,1djdbc-1.proxool.statistics-log-level=error
4、HikariCP 连接池
📕 添加依赖:
<dependency><groupId>com.alipay.oceanbase</groupId><artifactId>oceanbase-client</artifactId><version>3.2.3</version></dependency><dependency><groupId>com.zaxxer</groupId><artifactId>HikariCP</artifactId><version>3.3.1</version></dependency>
📕 配置文件示例(jdbc.properties):
jdbcUrl=jdbc:oceanbase://10.100.xxx.xxx:18817/test?useSSL=false&useServerPrepStmts=true&serverTimezone=UTCusername=$user_namepassword=******dataSource.cachePrepStmts=truedataSource.prepStmtCacheSize=250dataSource.prepStmtCacheSqlLimit=2048dataSource.useServerPrepStmts=truedataSource.useLocalSessionState=truedataSource.rewriteBatchedStatements=truedataSource.cacheResultSetMetadata=truedataSource.cacheServerConfiguration=truedataSource.elideSetAutoCommits=truedataSource.maintainTimeStats=false
五、总结
(一)JDBC 参数设置
在数据库应用性能优化的过程中,JDBC 参数设置至关重要:
1、超时配置:
👉 建议设置 socketTimeout,并根据应用特点进行调整。若不设置,默认超时时间为 0ms,即永不超时。
👉 建议设置 connectTimeout,并根据应用特点进行调整。若不设置,默认连接建立超时时间为 30000ms。
👉 对于 SQL 的超时时间,可以通过 OceanBase 的 SESSION 变量 ob_query_timeout 和 ob_trx_timeout 来控制。
2、Session 变量:
建议设置 useLocalSessionState=true,通过 JDBC 接口配置 autocommit、readonly、isolation 等 Session 变量。这能避免通过 SQL 语句访问数据库获取 Session 状态,从而提高交易性能。
3、批量操作:
建议启用 allowMultiQueries=true,支持使用分号(;)将多个 SQL 拼接为一个请求,从而减少应用与数据库之间的交互,提高性能。对于批量插入操作,推荐设置 rewriteBatchedStatements=true 和 useServerPrepStmts=false,并使用 addBatch + executeBatch 方式。
4、大结果集处理:
建议控制结果集的大小,如使用分页查询,并结合游标结果集与流式结果集。可以通过设置 useCursorFetch=true 和 useServerPrepStms=true,在 Java 程序中用 setFetchSize(>0) 设置游标结果集,或用 setFetchSize(Integer.MIN_VALUE) 切换为流式结果集。
(二)连接池参数配置
在进行连接池配置时,应考虑以下几点:
👉 根据业务需求合理设置连接池的初始、最小和最大连接数。
👉 合理配置连接的最大空闲时间,以避免长连接被意外断开。
👉 对于 SQL 处理频率较低的长连接,建议关闭空闲连接的回收,或设置较大的最大空闲时间;而对于频繁使用的连接池,则应打开空闲连接的回收。
(三)连接探活配置
设置 testWhileIdle=true 以在连接空闲时验证有效性,testOnBorrow=true 在借用时验证,testOnReturn=false 在归还时不进行检测。如果网络环境不稳定,则建议将 testOnBorrow 设置为 true。
(四)应用程序与数据库驱动配置
在应用程序配置中,我们需要更加关注以下方面:
1、连接超时设置:
前端程序连接数据库时,建议将 JDBC 连接超时设置为 1 秒,以便于快速检测连接失败并进行重连。由于频繁的重试可能导致网络拥塞和系统负载,建议在重连机制中设置间隔时间。
2、日志记录:
应确保程序日志记录标准 OceanBase 错误码及连接的数据库信息(如 IP、PORT、用户名),以助于 DBA 快速排查问题,维护系统稳定。
3、版本兼容性:
确保程序中使用的 JDBC 驱动库与线上数据库服务器版本兼容,以避免因版本不匹配引起的潜在问题和运行故障。
4、切换数据库:
不推荐使用 use 语句,而是应通过 Connection.setCatalog(dbname) 方法设置当前数据库,以提高代码的可读性和可维护性。
5、Session 状态变量:
在设置 ReadOnly 等 Session 状态时,建议使用 JDBC 接口(如 setReadOnly 或 setTransactionIsolation),以确保代码的一致性和安全。
6、事务处理:
执行单个事务时,无论是单条 SQL 还是多条 SQL,都必须在执行前重新获取数据库连接(通过 getConnection)。在事务执行完毕后,务必关闭连接(通过 closeConnection)。每个事务的处理步骤应为:
👉 getConnection:获取数据库连接。
👉 执行事务语句。
👉 closeConnection:关闭数据库连接。
