




业务场景:
应用使用的为磐维分布式版本oracle兼容模式,业务逻辑中使用sql脚本 for循环对十几张进行insert操作,每次insert插入一条数据,循环100w次。
问题现象:
业务对比集中式和分布式版本,发现分布式插入效率没有集中式高,需要定位优化。
问题分析:
查看sql脚本逻辑,for循环对十几张进行insert操作,每次insert插入一条数据,循环100w次。
脚本内容如下:

此脚本逻辑,算法效率为N*M,N为外部循环次数100w,M为内部的 insert 条数,此种算法并不是最优。
分布式的架构与集中式架构存在差异性,集中式架构只有一个datanode组件参与insert计算,分布式架构则是cn、gtm、datanode均参与insert计算,如下图所示。
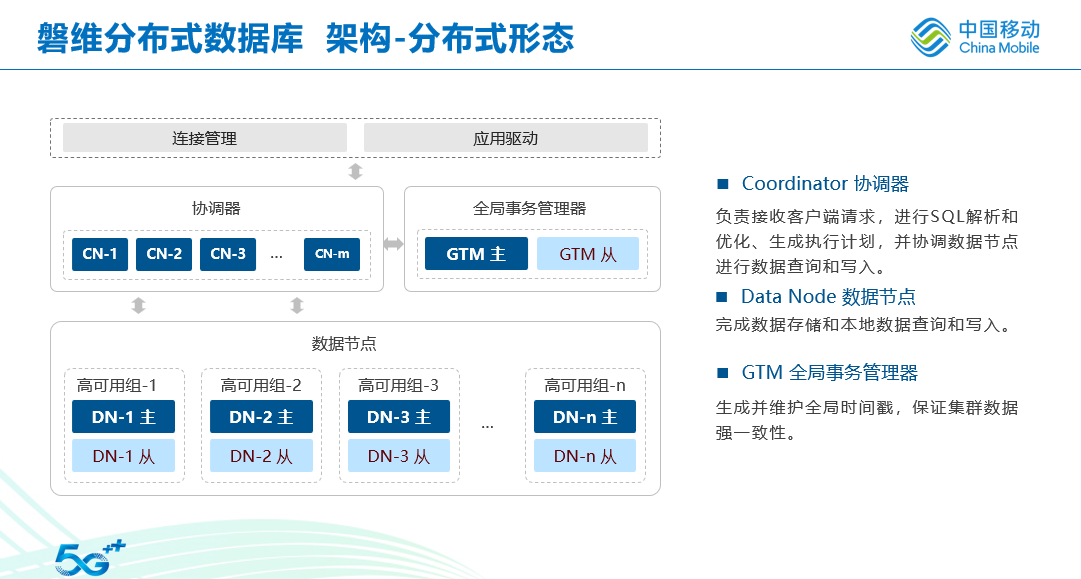
分布式架构决定了单条insert一条数据要比集中式慢。无形中也放大了上面N*M 算法效率慢的现象。
问题解决:
两种办法:
1:业务脚本只是简单的循环 insert插入,并未其他逻辑,采用数据库内置函数generate_series(),消除 N*M循环算法,采用数据库内部的 max(N,M) 算法,提高性能。
generate_series()函数用法如下:

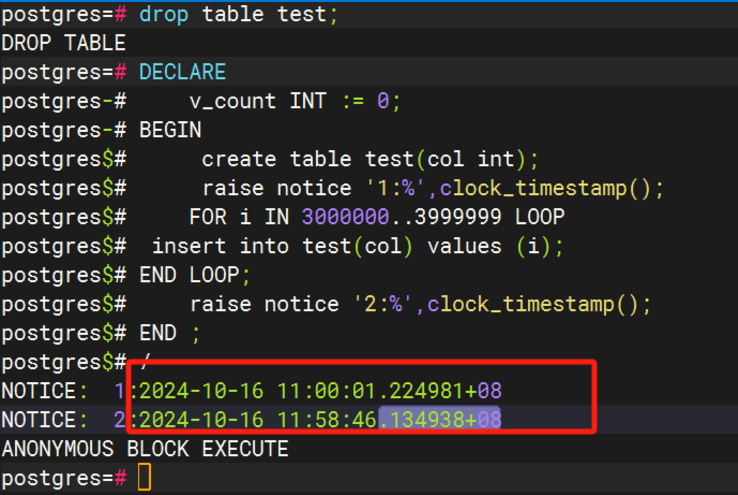
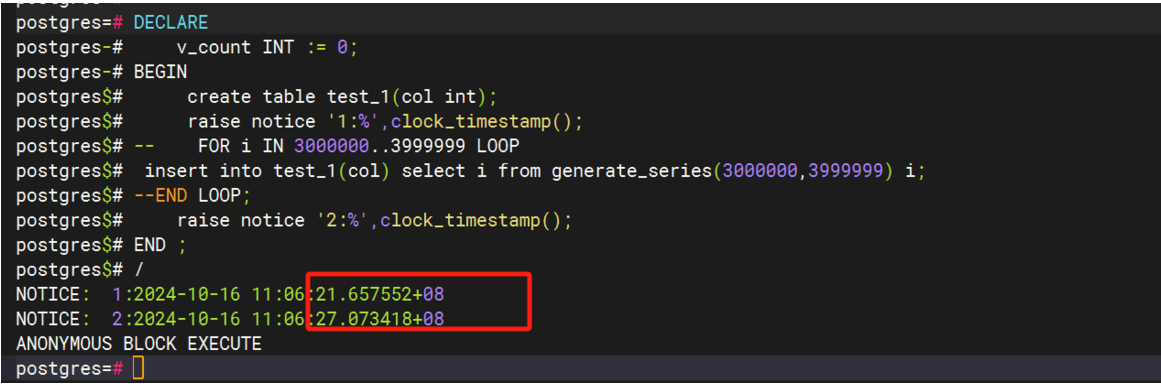
Demo测试如下,第一张优化之前的执行将近1小时,第二张优化后执行6s。
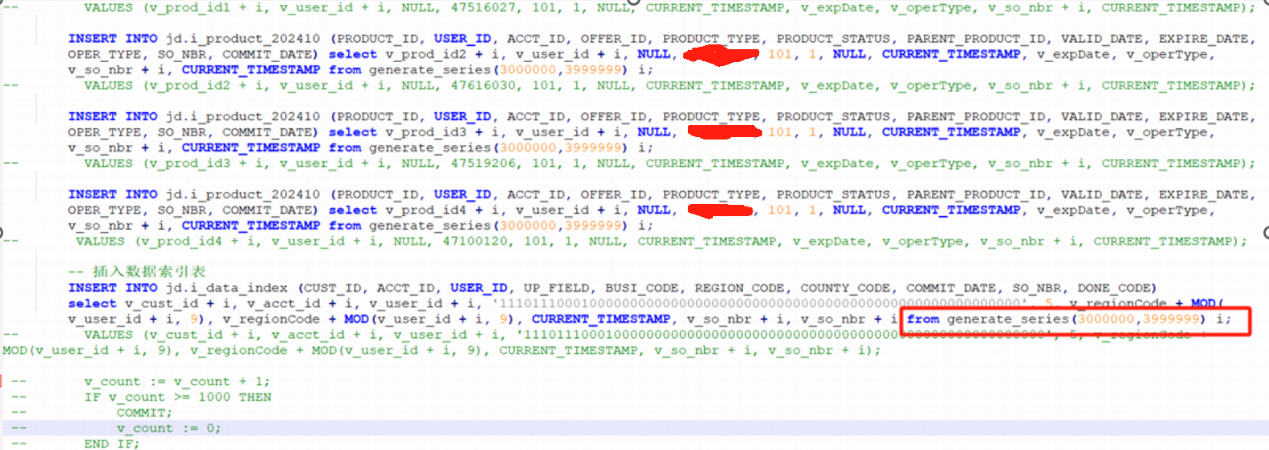
优化后的业务sql如下,执行耗时25s,符合预期。
2:当sql脚本比较复杂时,通过将脚本中涉及十几张拆分为几个sql脚本,并行执行,发挥PanweiDB分布式数据库的并行能力,提高业务性能。
问题总结:
业务使用磐维分布式版本oracle兼容模式时,应用使用的为磐维分布式版本oracle兼容模式,业务逻辑中使用sql脚本 for循环对十几张进行insert操作,每次insert插入一条数据,循环100w次。经过以上分析,分布式架构原因导致比集中式慢,未发挥PanweiDB的分布式能力。解决方法:1.使用数据库内置函数generate_series():消除 N*M循环算法,采用数据库内部的 max(N,M) 算法,提高性能587倍。2.将脚本按照表数量拆分多个脚本,并行执行,发挥PanweiDB分布式数据库的并行能力。
