




GPU,型号是
AMD Radeon 780M显卡,
16GB内存,
3A游戏不怎么玩,卡有点浪费。最近大模型很火,就看看都有哪些使用场景,以及能不能用
AMD 780M核显
GPU跑大模型应用。
使用 ollama
和 open webui
搭建本地 ChatGPT
应用
ChatGPT此前有用过,感觉其知识检索和问答能力非常好,只是不知道怎么实现的。接下来就在尝试在本地部署一个。
ollama,用于在本地运行流行的大模型,包括
Facebook、
Google、阿里云的。框架也支持多种操作系统平台(如
Windows、
MAC、
Linux)的。
ollama似乎还不支持
AMD 780核显。官方支持的显卡类型包括:
"gfx900""gfx906:xnack-""gfx908:xnack-""gfx90a:xnack+""gfx90a:xnack-""gfx940" "gfx941"gfx942""gfx1010""gfx1012""gfx1030" "gfx1100""gfx1101""gfx1102",偏偏
AMD 780M的显示核心代号为
gfx1103,不在上面的支持列表中。
https://github.com/likelovewant/ollama-for-amd。安装部署了一下果然支持。项目里也给出了常见大大模型数据集大小和下载方法。
| Model | Parameters | Size | Download |
|---|---|---|---|
| Llama 3.2 | 3B | 2.0GB | ollama run llama3.2 |
| Llama 3.2 | 1B | 1.3GB | ollama run llama3.2:1b |
| Llama 3.2 Vision | 11B | 7.9GB | ollama run llama3.2-vision |
| Llama 3.2 Vision | 90B | 55GB | ollama run llama3.2-vision:90b |
| Llama 3.1 | 8B | 4.7GB | ollama run llama3.1 |
| Llama 3.1 | 70B | 40GB | ollama run llama3.1:70b |
| Llama 3.1 | 405B | 231GB | ollama run llama3.1:405b |
| Phi 3 Mini | 3.8B | 2.3GB | ollama run phi3 |
| Phi 3 Medium | 14B | 7.9GB | ollama run phi3:medium |
| Gemma 2 | 2B | 1.6GB | ollama run gemma2:2b |
| Gemma 2 | 9B | 5.5GB | ollama run gemma2 |
| Gemma 2 | 27B | 16GB | ollama run gemma2:27b |
| Mistral | 7B | 4.1GB | ollama run mistral |
| Moondream 2 | 1.4B | 829MB | ollama run moondream |
| Neural Chat | 7B | 4.1GB | ollama run neural-chat |
| Starling | 7B | 4.1GB | ollama run starling-lm |
| Code Llama | 7B | 3.8GB | ollama run codellama |
| Llama 2 Uncensored | 7B | 3.8GB | ollama run llama2-uncensored |
| LLaVA | 7B | 4.5GB | ollama run llava |
| Solar | 10.7B | 6.1GB | ollama run solar |
ollama
部署
ollama的部署方法参考项目文档即可,这里特别提示的是设置几个
windows环境变量。在命令行下如果系统环境变量没有生效,也可以手动设置一下,然后再启动
ollama。命令如下:
C:\Users\MQ>set OLLAMA_HOST=0.0.0.0:8000
C:\Users\MQ>set OLLAMA_REGIONS=*
C:\Users\MQ>set OLLAMA_MODELS=C:\Users\MQ\.ollama\models
C:\Users\MQ>set |findstr OLLAMA
OLLAMA_HOST=0.0.0.0:8000
OLLAMA_MODELS=C:\Users\MQ\.ollama\models
OLLAMA_ORIGINS=*
OLLAMA_REGIONS=*
C:\Users\MQ>ollama serve
2024/12/01 10:58:15 routes.go:1189: INFO server config env="map[CUDA_VISIBLE_DEVICES: GPU_DEVICE_ORDINAL: HIP_VISIBLE_DEVICES: HSA_OVERRIDE_GFX_VERSION: HTTPS_PROXY: HTTP_PROXY: NO_PROXY: OLLAMA_DEBUG:false OLLAMA_FLASH_ATTENTION:false OLLAMA_GPU_OVERHEAD:0 OLLAMA_HOST:http://0.0.0.0:8000 OLLAMA_INTEL_GPU:false OLLAMA_KEEP_ALIVE:5m0s OLLAMA_LLM_LIBRARY: OLLAMA_LOAD_TIMEOUT:5m0s OLLAMA_MAX_LOADED_MODELS:0 OLLAMA_MAX_QUEUE:512 OLLAMA_MODELS:C:\\Users\\MQ\\.ollama\\models OLLAMA_MULTIUSER_CACHE:false OLLAMA_NOHISTORY:false OLLAMA_NOPRUNE:false OLLAMA_NUM_PARALLEL:0 OLLAMA_ORIGINS:[* http://localhost https://localhost http://localhost:* https://localhost:* http://127.0.0.1 https://127.0.0.1 http://127.0.0.1:* https://127.0.0.1:* http://0.0.0.0 https://0.0.0.0 http://0.0.0.0:* https://0.0.0.0:* app://* file://* tauri://* vscode-webview://*] OLLAMA_SCHED_SPREAD:false OLLAMA_TMPDIR: ROCR_VISIBLE_DEVICES:]"
time=2024-12-01T10:58:15.739+08:00 level=INFO source=images.go:755 msg="total blobs: 23"
time=2024-12-01T10:58:15.740+08:00 level=INFO source=images.go:762 msg="total unused blobs removed: 0"
time=2024-12-01T10:58:15.740+08:00 level=INFO source=routes.go:1240 msg="Listening on [::]:8000 (version 0.4.1-1-g14a68a0)"
time=2024-12-01T10:58:15.741+08:00 level=INFO source=common.go:49 msg="Dynamic LLM libraries" runners="[cpu_avx2 rocm cpu cpu_avx]"
time=2024-12-01T10:58:15.741+08:00 level=INFO source=gpu.go:221 msg="looking for compatible GPUs"
time=2024-12-01T10:58:15.741+08:00 level=INFO source=gpu_windows.go:167 msg=packages count=1
time=2024-12-01T10:58:15.741+08:00 level=INFO source=gpu_windows.go:214 msg="" package=0 cores=8 efficiency=0 threads=16
time=2024-12-01T10:58:16.197+08:00 level=INFO source=types.go:123 msg="inference compute" id=0 library=rocm variant="" compute=gfx1103 driver=6.1 name="AMD Radeon 780M Graphics" total="33.7 GiB" available="33.6 GiB"
Windows里
运行输入
ollama启动,这样右小角会有个任务图标提示。
ollama运行后就是下载需要的大模型。这里我下载了部分大模型看了看。
C:\Users\MQ>ollama list
NAME ID SIZE MODIFIED
qwen2.5:7b 845dbda0ea48 4.7 GB 15 hours ag
mxbai-embed-large:latest 468836162de7 669 MB 17 hours ago
dolphin-llama3:latest 613f068e29f8 4.7 GB 17 hours ago
llama3.1:latest 42182419e950 4.7 GB 18 hours ago
nomic-embed-text:latest 0a109f422b47 274 MB 2 weeks ago
大模型测试

llama3大模型测试
GPU显卡能力。
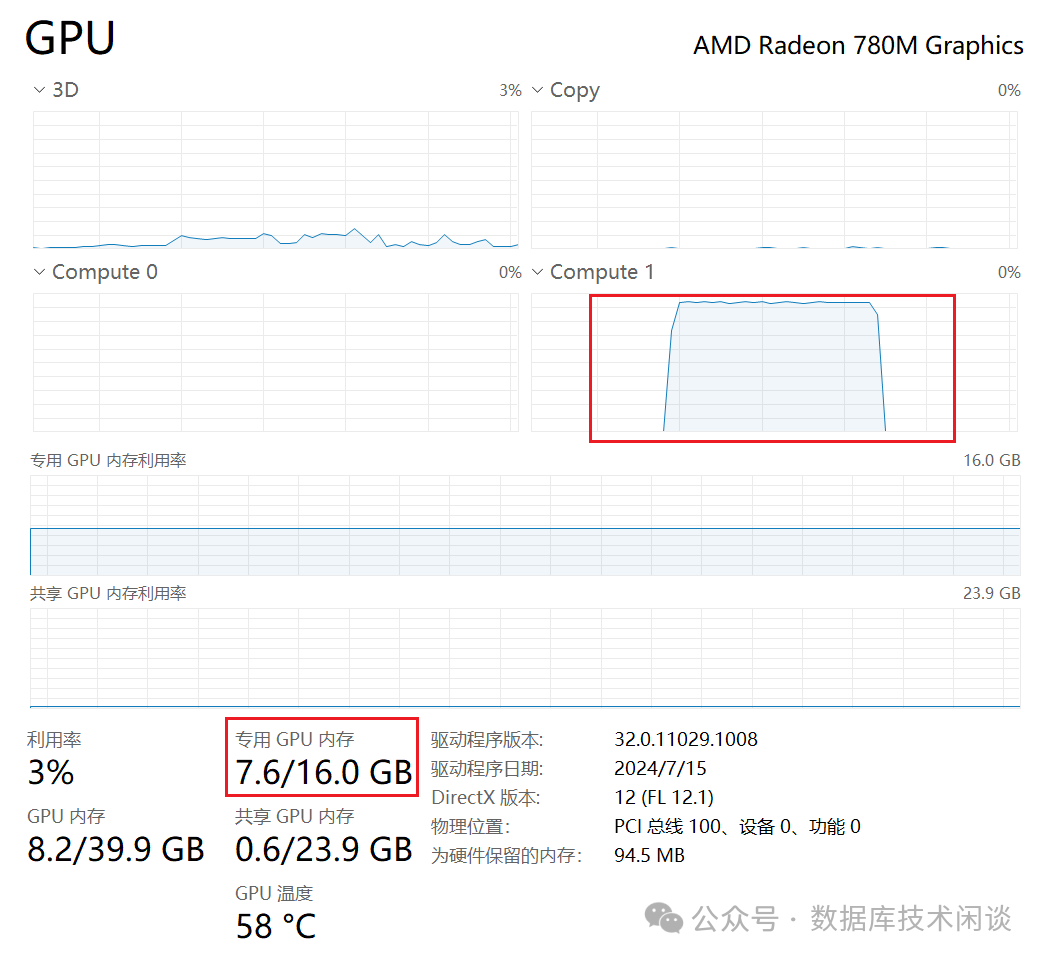
llama3 gpu监控

llama3的训练数据截止到 2021年12月31日。

ChatGPT的使用体验比起来还差点意思。所以还需要下载一个开源框架
open webui配合
ollama使用。
Open WebUI是一个可扩展、功能丰富且用户友好的自托管
WebUI,旨在完全离线操作。它支持各种 LLM 运行程序,包括
Ollama和
OpenAI兼容的 API。
Ollama WebUI
部署
Ollama WebUI是一个革命性的 LLM 本地部署框架,具有类似 ChatGPT 的 Web 界面。安装方式支持
docker。前提是先安装了
ollama,然后同机部署
webui,命令如下:
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data -e OLLAMA_BASE_URL=http://192.168.0.102:8000 --name open-webui --restart always ghcr.io/open-webui/open-webui:main
-e OLLAMA_BASE_URL=http://192.168.0.102:8000。这是前面
ollama启动后监听的
ip和端口信息。我的
docker跟
ollama不是在一个虚拟机环境中,所以需要指定这个参数。
(base) mq@OBPILOT:/mnt/c/Users/MQ$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
5e8f9555c9ab ghcr.io/open-webui/open-webui:main "bash start.sh" 19 hours ago Up 4 seconds (health: starting) 0.0.0.0:3000->8080/tcp, :::3000->8080/tcp open-webui
ollama webui
使用
http://172.20.143.100:3000。第一次访问会要求本地注册一个账户。

open webuiChatGPT确实比较像。这问题回答的质量差强人意,这可能是大模型自身的问题,也可能是内容的问题。当使用者问的问题不是自己擅长的领域时,大模型的回答还是有很大帮助。

ollama webui的作用不仅仅如此,它还有个官网
https://openwebui.com/,上面有很多开发者贡献的大模型,很多是在大厂大模型基础上定制修改的。
openwebui官网
ollama webui中也是很方便。不过这些模型没看出有什么有趣的。
backyard.ai。
backyard AI
backyard AI是一个免费的 AI 聊天应用程序,允许用户通过文本和语音与可自定义的 AI 角色互动,具有故事书、语法和高级模型参数等功能,同时保持隐私并支持离线工作。
https://backyard.ai/hub,也支持 APP 下载本地部署。
backyard AIADM 780M核显。
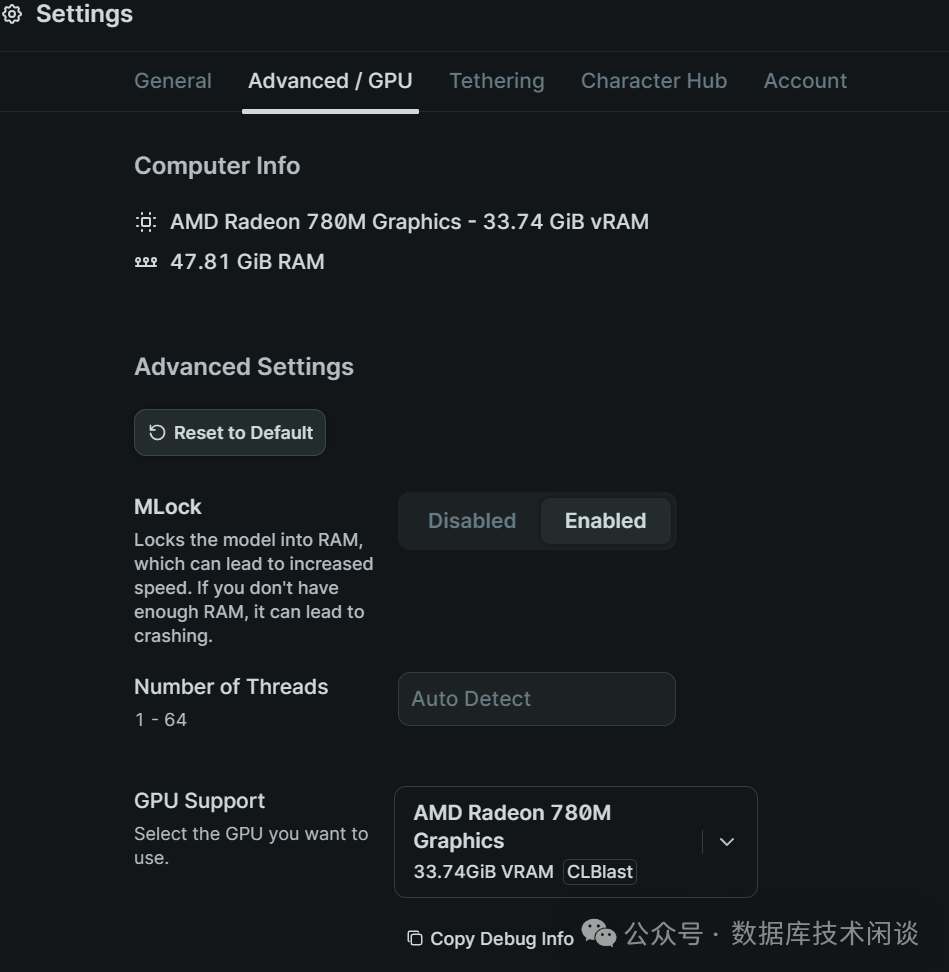
GPU设置
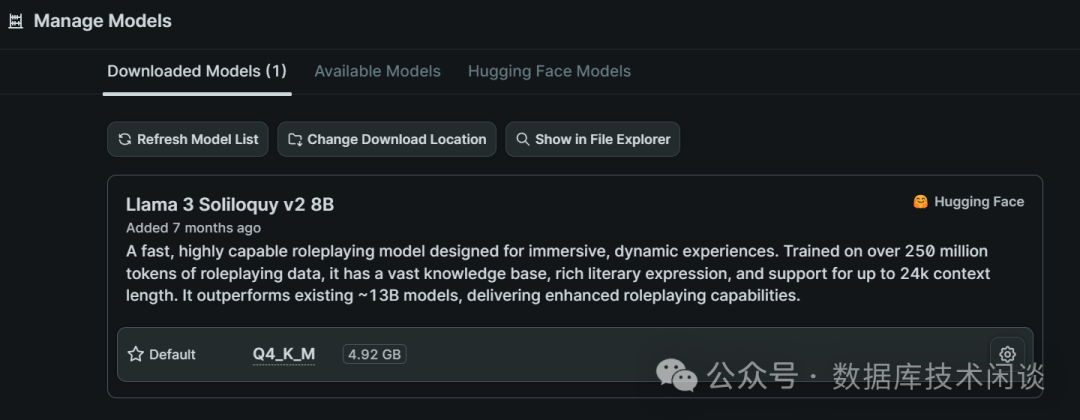
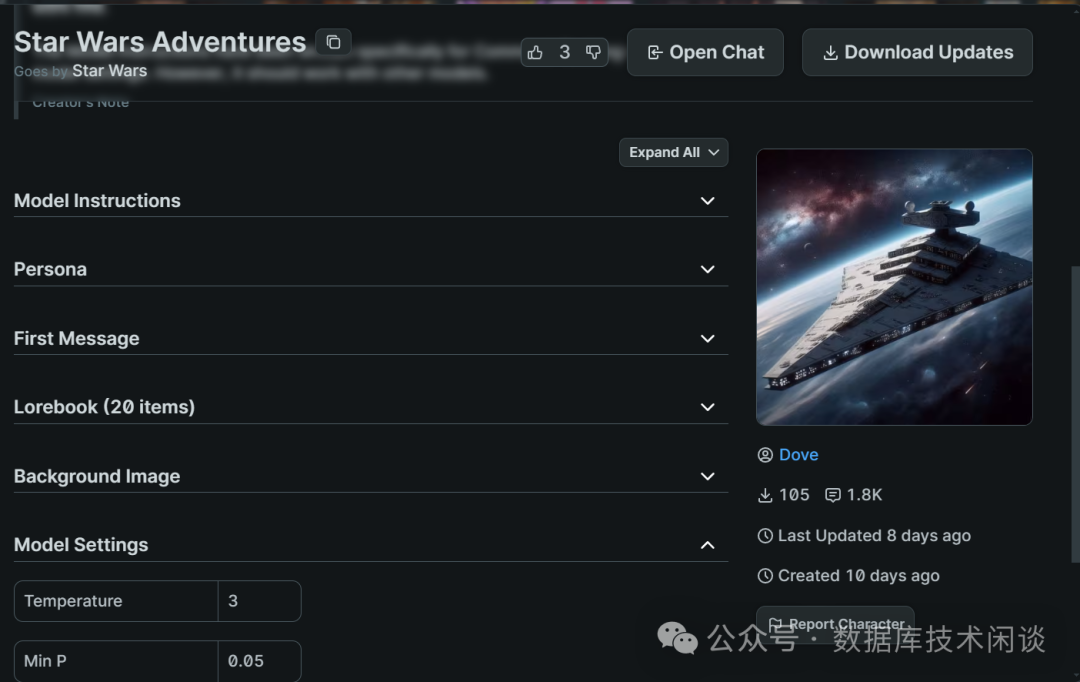
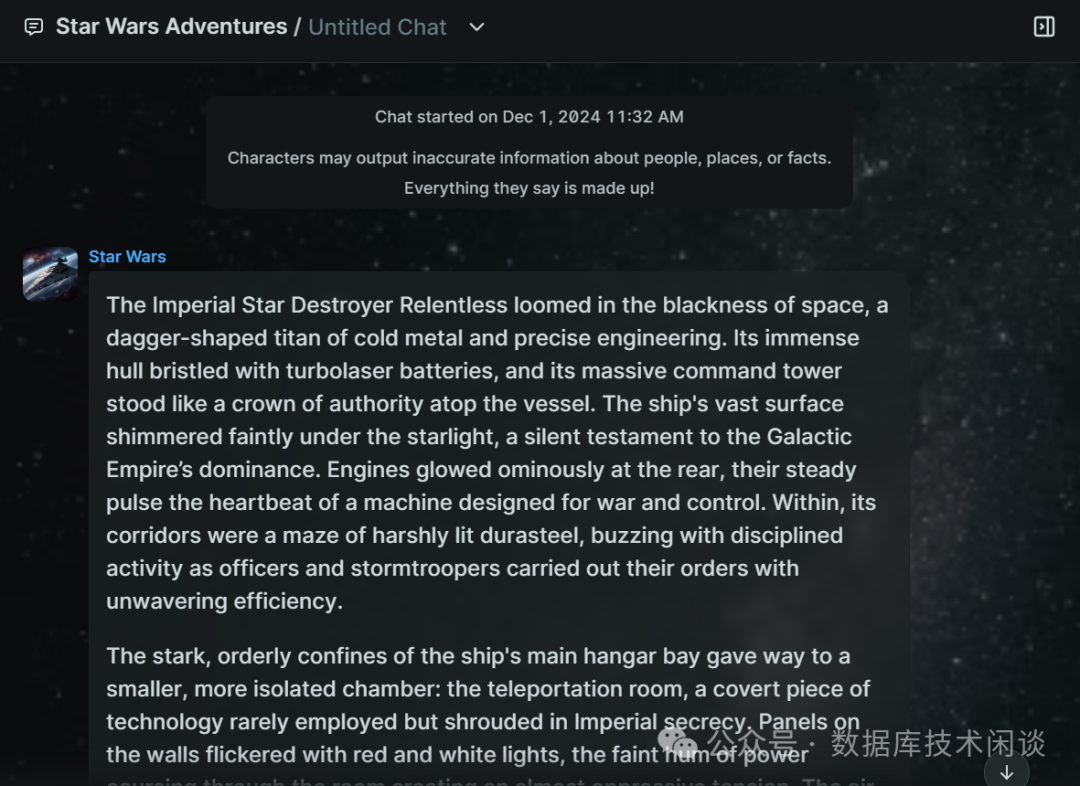

AI会回复英文,估计翻译是调用的网络哪个平台的翻译服务。整个
AI里的描述估计是以星球大战小说或影视剧本文本做训练的。
AI场景功能估计还能做到更惊艳。
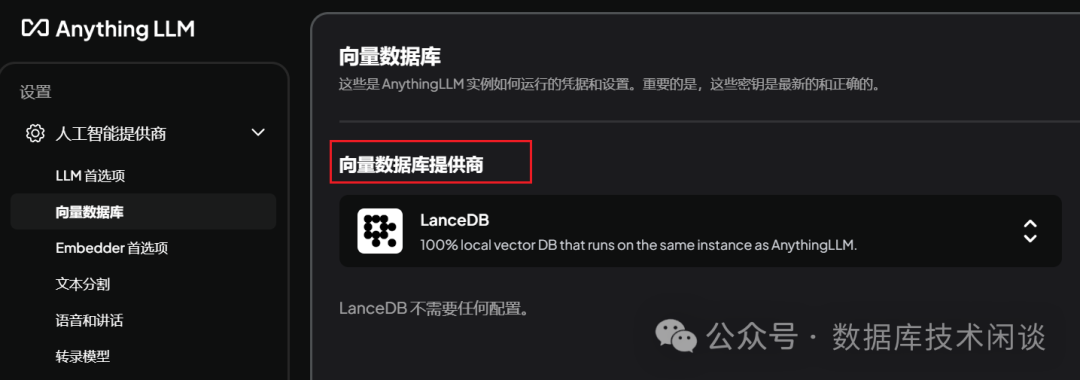
Anything LLM
AnythingLLM是
Mintplex Labs Inc.开发的一款开源
ChatGPT等效工具,用于在安全的环境中与文档等进行聊天,专为想要使用现有文档进行智能聊天或构建知识库的任何人而构建。开源地址:
https://github.com/Mintplex-Labs/anything-llmAnythingLLM也是一个集成了
RAG和
AI Agent功能的 AI 桌面应用。软件部署也很简单,第一次运行后也需要做一些配置。
ollama。
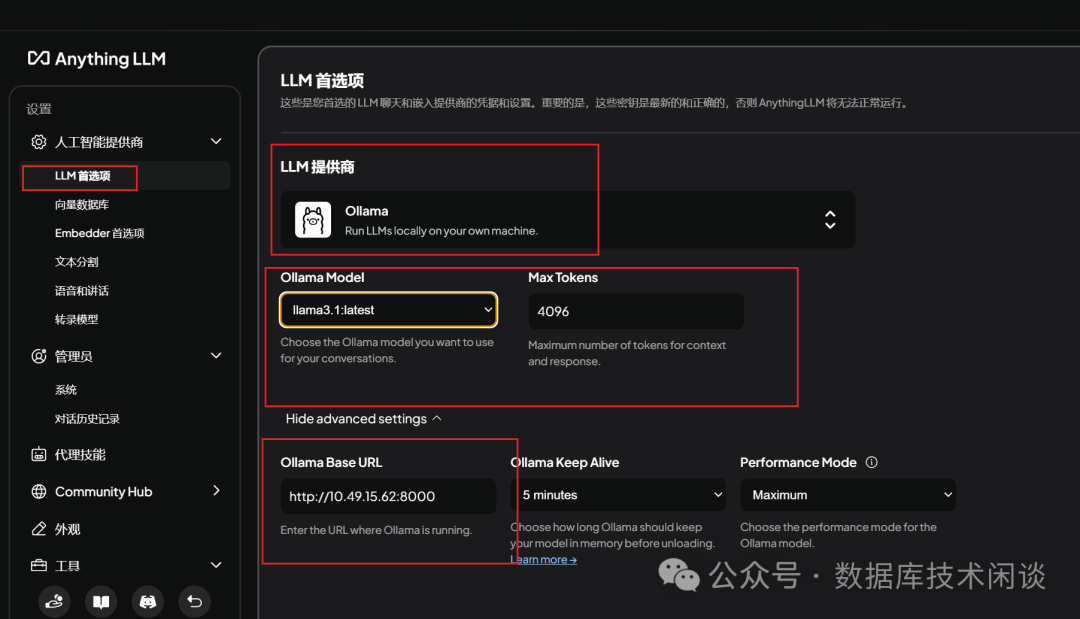
AnythingLLM配置大模型框架
OceanBase,所以就选默认的。
RAG
和向量数据库介绍
RAG是什么?为什么这里要用到
RAG?这个我不熟悉,就交给大模型自己回答吧。:)
Retriveal Augmented Generation(RAG)检索增强生成,是一种结合了知识检索和生成模型的技术方法,用于减少“幻觉”的产生,主要使用在问答系统,为用户提供正确的答案。
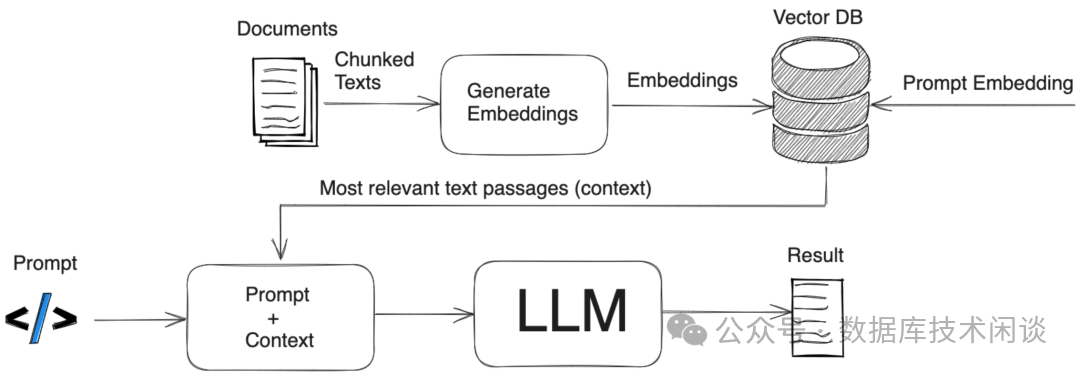
RAG应用框架
RAG应用框架中就有个向量数据库。向量数据库是RAG方式的一个重要的数据来源。
Vector Database)是一种专门用于存储和查询向量数据的数据库系统。传统的数据库主要侧重于存储和查询结构化数据,而向量数据库则专注于处理和索引高维
度向量数据。它的主要特点是能够高效地存储和检索大规模向量数据。
RAG这是一门新的领域,跟数据库的“向量”距离有一点远,非我所长,这里就不“胡说八道”了。有兴趣的可以看看蚂蚁
AI团队的微信公众号和视频号:
EosphorosAI,里面有很多实践分享(见文末链接)。
ORACLE、
MySQL和
PostgreSQL也都支持向量类型和查询方法。
OceanBase数据库也不甘落后,在最近的发布会上也公布了向量查询的功能和性能 。后面我还会借助
OceanBase数据库看看所谓的向量查询到底是什么。
AnythingLLM的有趣用法,就是分析文档。
AnythingLLM
分析文档
AnythingLLM的对话框里,是可以直接发送文档(
txt、
csv或
pdf等)。发送文档后,
AnythingLLM会解析文档,以向量的格式将解析结果存储到向量数据库里。所以这里还需要设置一下向量处理模型。
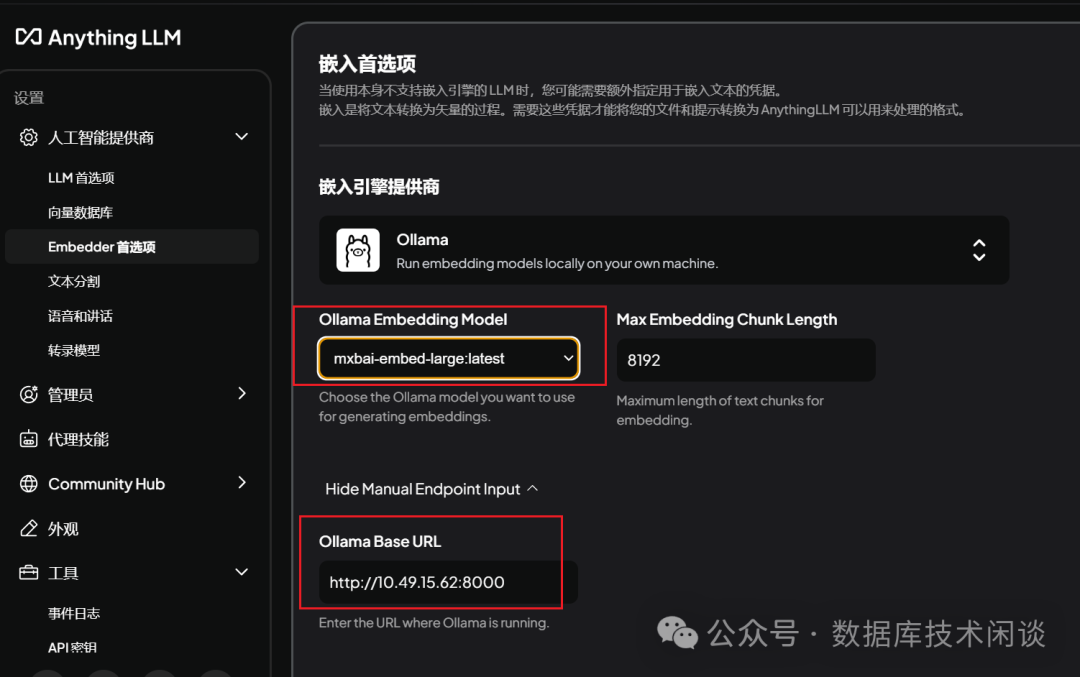
mxbai-embed-large:latest替换了
AnythingLLM默认的嵌入式模型。
OceanBase和
GaussDB的部署文档,然后提一个还是有一定难度的问题试试看。
GPU想了一会,通常说的脑子要冒烟了,在这里还是更形象具体(开个玩笑,实际上大部分问题,
GPU都不超过十几秒就返回了)。
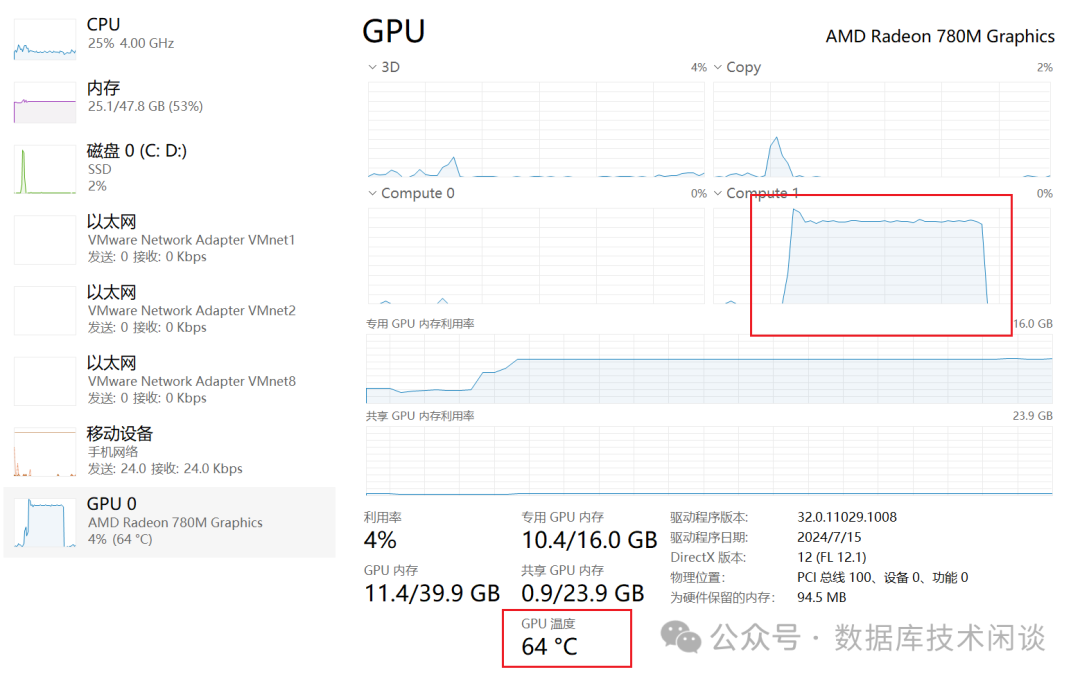
OceanBase社区团队开发的
AI互动项目。
OceanBase AI 动手实战营
https://gitee.com/oceanbase-devhub/ai-workshop-2024这里面也给出了
RAG应用的框架图。
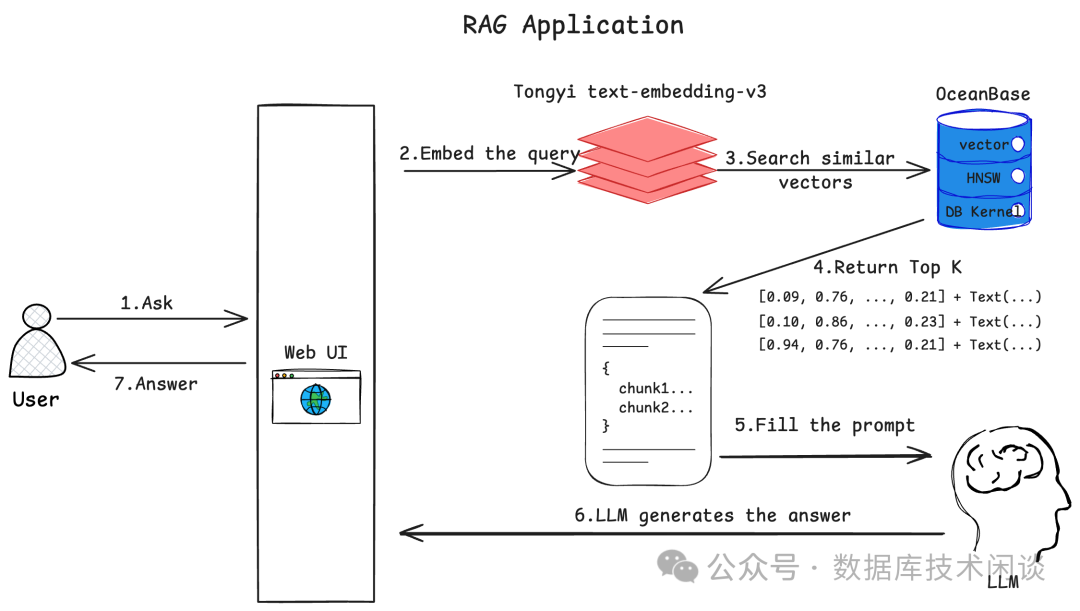
RAG Application用户在 Web 界面中输入想要咨询的问题并发送给机器人 机器人将用户提出的问题使用文本嵌入模型转换为向量 将用户提问转换而来的向量作为输入在 OceanBase
中检索最相似的向量OceanBase
返回最相似的一些向量和对应的文档内容机器人将用户的问题和查询到的文档一起发送给大语言模型并请它生成问题的回答 大语言模型分片地、流式地将答案返回给机器人 机器人将接收到的答案也分片地、流式地显示在 Web 界面中,完成一轮问答
OceanBase AI
项目部署
Readme.md。其他地方写的部署方法(包括我这里写的)都不可靠。其原因是每个人环境可能有不同,所以碰到的问题也不尽相同。此外就是这个源码和发布会经常性更新。所以以前的问题可能不是问题,以前没有的问题现在可能有了。
Python环境,大概
3.9~3.10都可以(
3.10我是没有跑通,
3.9.5是跑通了)。这里推荐先部署
conda软件来管理
Python环境。
sh Anaconda3-2024.10-1-Linux-x86_64.sh
conda create --name python3.9.5 python=3.9.5
conda activate python3.9.5
(base) mq@OBPILOT:~$ conda info --env
# conda environments:
#
base * /home/mq/anaconda3
python3.9.5 /home/mq/anaconda3/envs/python3.9.5
(base) mq@OBPILOT:~$ conda activate python3.9.5
(python3.9.5) mq@OBPILOT:~$
git clone https://gitee.com/oceanbase-devhub/ai-workshop-2024.git
.env(python3.9.5) mq@OBPILOT:~/gitee/ai-workshop-2024$ cat .env
API_KEY=sk-4b85613d2726432f97f2****d50bfe30
LLM_MODEL="qwen-turbo-2024-11-01"
LLM_BASE_URL="https://dashscope.aliyuncs.com/compatible-mode/v1"
HF_ENDPOINT=https://hf-mirror.com
BGE_MODEL_PATH=BAAI/bge-m3
OLLAMA_URL=
OLLAMA_TOKEN=
# OPENAI_EMBEDDING_API_KEY 一项请填写和 API_KEY 一样的值
OPENAI_EMBEDDING_API_KEY=sk-4b85613d2726432f97f2****d50bfe30
OPENAI_EMBEDDING_BASE_URL="https://dashscope.aliyuncs.com/compatible-mode/v1/embeddings"
OPENAI_EMBEDDING_MODEL=text-embedding-v3
UI_LANG="zh"
# 如果你使用的是 OB Cloud 的实例,请根据实例的连接信息更新下面的变量
DB_HOST="127.0.0.1"
DB_PORT="2881"
DB_USER="root@test"
DB_NAME="test"
DB_PASSWORD=""
API_KEY。按上面配置文件记录的需要提供阿里云百炼里平台里的大模型调用的
API KEY。地址:
https://bailian.console.aliyun.com/。第一次需要登录阿里云账户,并且免费开通大模型服务。
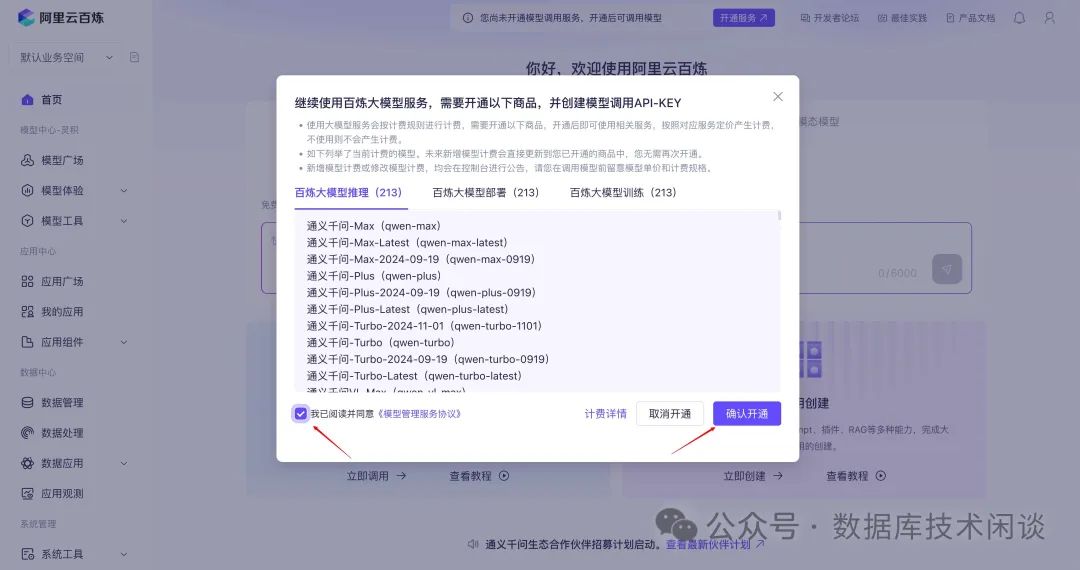
API KEY,创建属于你的
API-KEY。
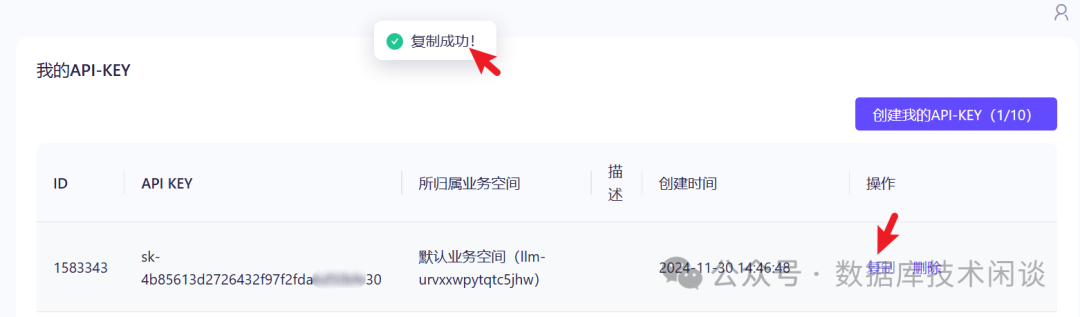
API-KEY.env后面是向量数据库的配置地址。这里使用的
OceanBase的
MySQL租户。所以部署前还需要有一个
OceanBase 4.3.3.1数据库。参考我以前的文章有手动部署方法,这里图简单就直接用
docker部署一个。
docker run --name=ob433 -e MODE=mini -e OB_MEMORY_LIMIT=8G -e OB_DATAFILE_SIZE=10G -e OB_CLUSTER_NAME=ailab2024 -e OB_SERVER_IP=127.0.0.1 -p 0.0.0.0:2881:2881 -d quay.io/oceanbase/oceanbase-ce:4.3.3.1-101000012024102216
docker容器映射
IP的时候用
0.0.0.0:2881:2881,不然不好远程用客户端工具访问这个数据库。
pyproject.toml,这个里面会有相关依赖包的信息。依赖包通过
poetry管理。所以还需要事先安装
poetry包。
python -m pip install poetry
poetry lock
poetry install
python包,都写到这个配置文件中,然后再次运行上面命令。下面是我运行成功后的配置文件示例。
(python3.9.5) mq@OBPILOT:~/gitee/ai-workshop-2024$ cat pyproject.toml
[tool.poetry]
name = "ai-workshop"
version = "0.1.0"
description = ""
authors = ["yuyi <yuyi.wsy@oceanbase.com>"]
readme = "README.md"
package-mode = false
[tool.poetry.dependencies]
python = ">=3.9,<3.9.7 || >3.9.7,<4.0"
langchain = "^0.3.0"
langchain-openai = "^0.2.0"
streamlit = "^1.38.0"
pyobvector = "^0.1.14"
langchain-community = { git = "https://github.com/oceanbase-devhub/langchain-community.git", rev = "main" }
[build-system]
requires = ["poetry-core"]
build-backend = "poetry.core.masonry.api"
[[tool.poetry.source]]
name = "PyPI"
priority = "supplemental"
[[tool.poetry.source]]
name = "aliyun"
url = "https://mirrors.aliyun.com/pypi/simple/"
priority = "primary"
解析文档
doc_repos/。
git clone --single-branch --branch V4.3.4 https://github.com/oceanbase/oceanbase-doc.git doc_repos/oceanbase-doc
# 把文档的标题转换为标准的 markdown 格式
poetry run python convert_headings.py doc_repos/oceanbase-doc/zh-CN
# 生成文档向量和元数据
poetry run python embed_docs.py --doc_base doc_repos/oceanbase-doc/zh-CN/640.ob-vector-search
embed_docs.py脚本,通过指定文档目录和对应的组件后,该脚本就会遍历目录中的所有
markdown格式的文档,将长文档进行切片后使用嵌入模型转换为向量,并最终将文档切片的内容、嵌入的向量和切片的元信息(
JSON格式,包含文档标题、相对路径、组件名称、切片标题、级联标题)一同插入到
OceanBase的同一张表中,作为预备数据待查。
OceanBase众多文档中与向量检索有关的几篇文档。

运行 AI
应用
AI应用。命令如下:
poetry run streamlit run --server.runOnSave false chat_ui.py
(python3.9.5) mq@OBPILOT:~/gitee/ai-workshop-2024$ poetry run streamlit run --server.runOnSave false chat_ui.py
You can now view your Streamlit app in your browser.
Local URL: http://localhost:8501
Network URL: http://172.20.143.100:8501浏览器打开上面提示的地址。
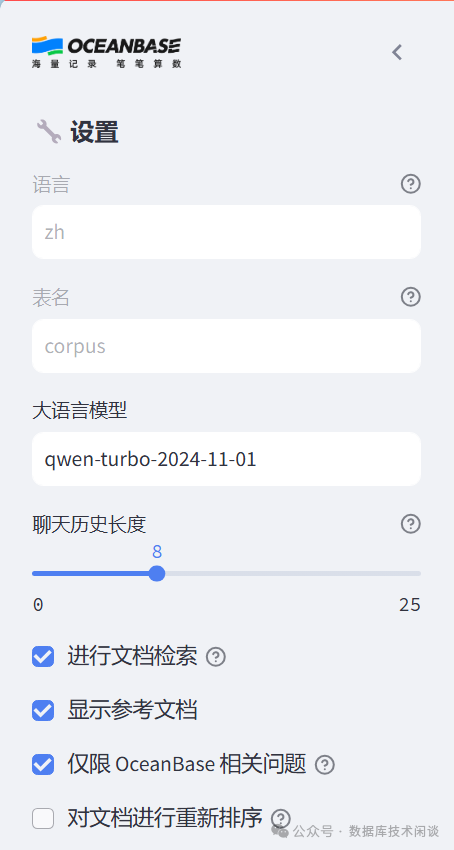
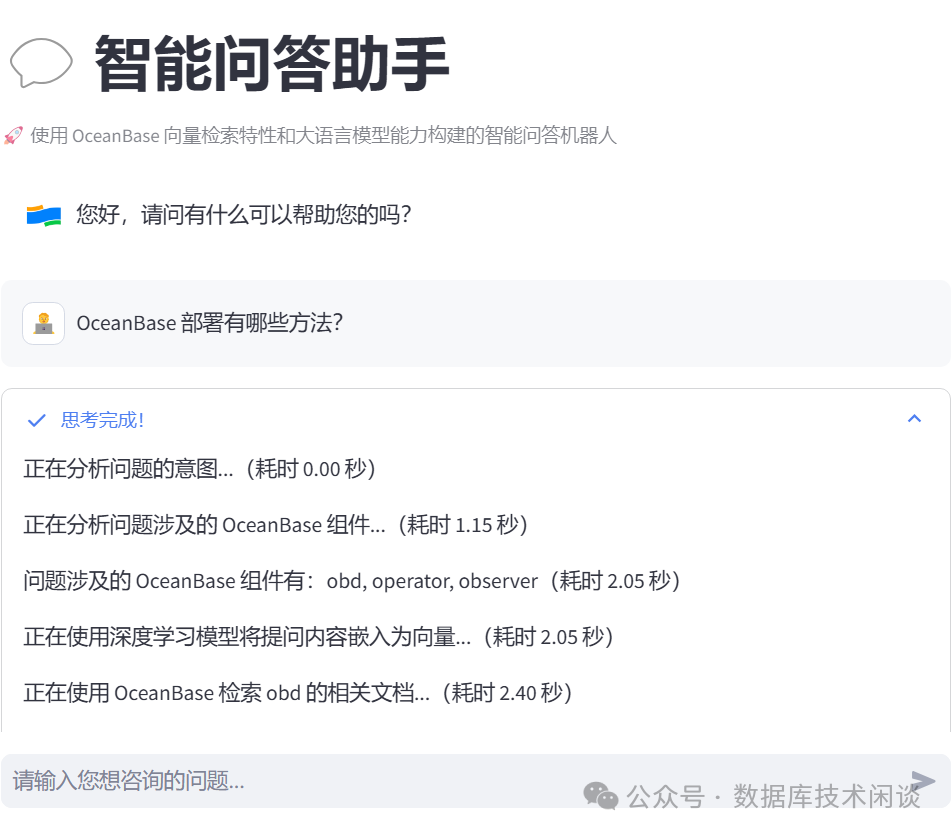

obsidian笔记内容放进去,然后问一个跟
OceanBase无关的问题。
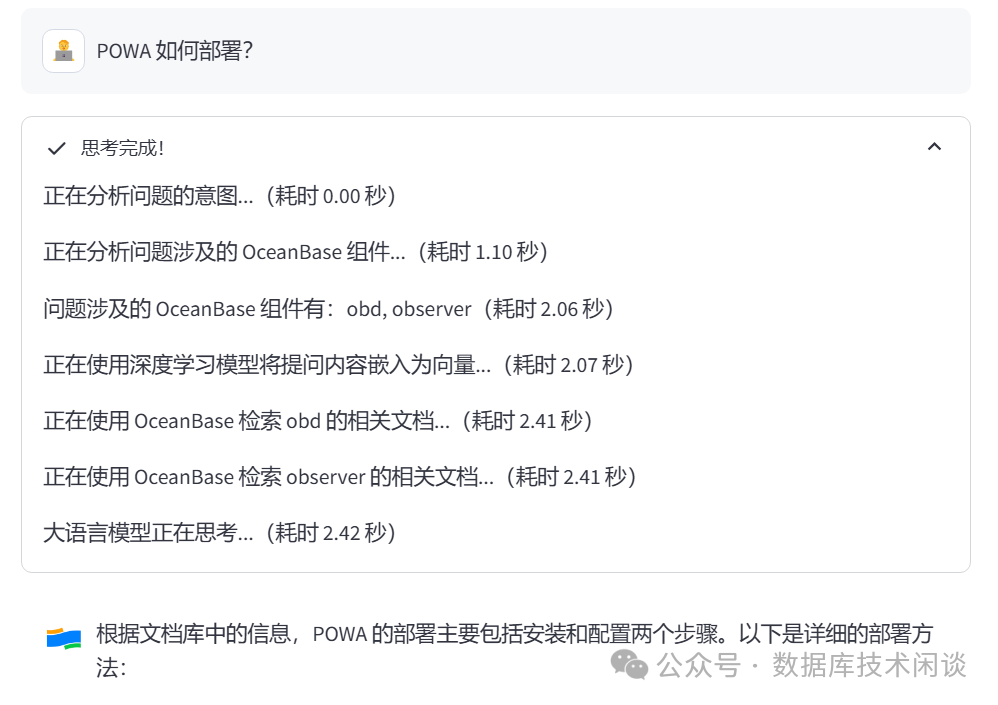
数据库向量查询
DEMO使用了
OceanBase做向量查询。
OceanBase不是专门的向量数据库,只是提供了一些向量查询(项目中叫向量检索)。
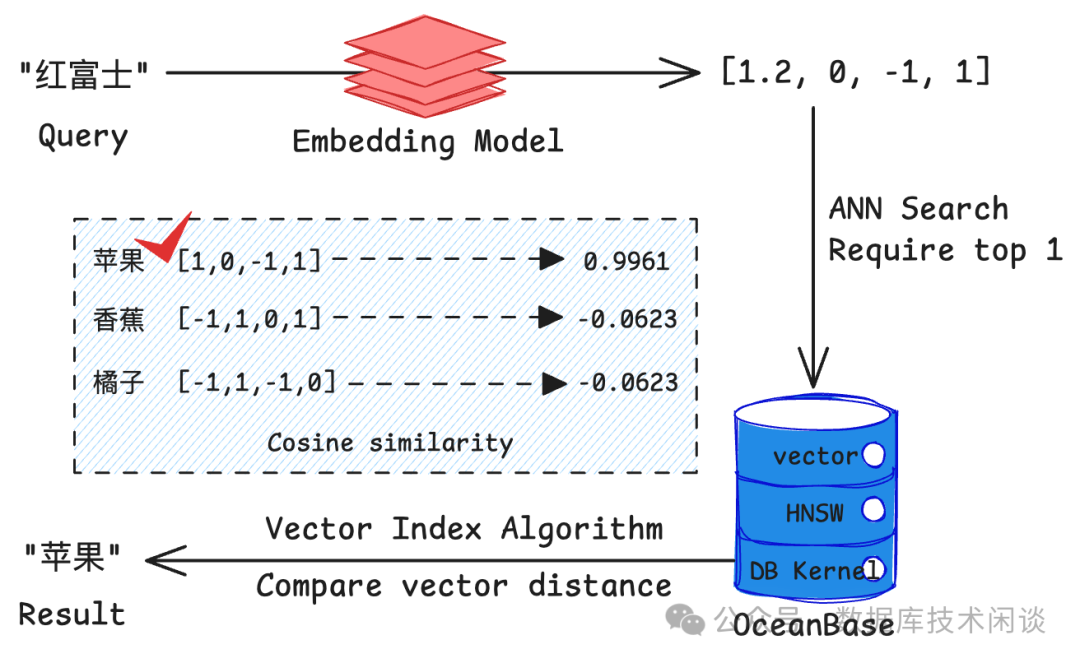
基于向量间的距离(如欧氏距离)或相似度(如余弦相似度)进行搜索 通常使用近似最近邻( Approximate Nearest Neighbor, ANN
)算法来提高检索效率OceanBase 4.3.3
支持 HNSW 算法,这是一种高效的 ANN 算法使用 ANN 可以快速从百万甚至亿级别的向量中找到近似最相似的结果 相比传统关键词搜索,向量检索能更好地理解语义相似性
OceanBase在关系型数据库模型基础上将“向量”作为一种数据类型进行了完好的支持,使得在 OceanBase 一款数据库中能够同时针对向量数据和常规的结构化数据进行高效的存储和检索。在本项目中,我们会使用
OceanBase建立
HNSW (Hierarchical Navigable Small World)向量索引来实现高效的向量检索,帮助我们快速找到与用户问题最相关的文档片段。
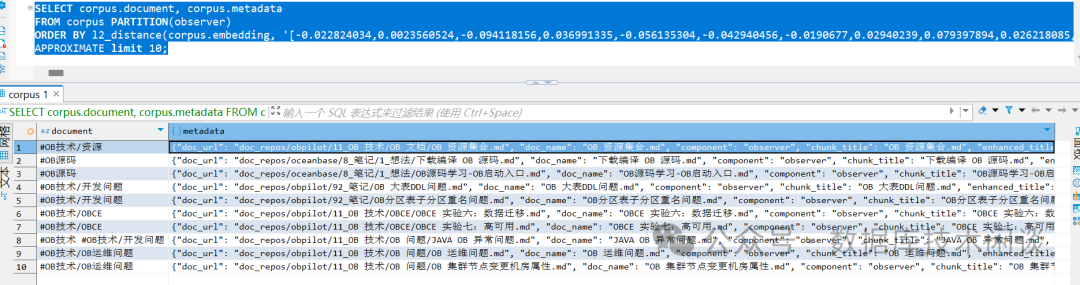
show create table corpus;
CREATE TABLE `corpus` (
`id` varchar(4096) NOT NULL,
`embedding` VECTOR(1024) DEFAULT NULL,
`document` longtext DEFAULT NULL,
`metadata` json DEFAULT NULL,
`component_code` int(11) NOT NULL,
PRIMARY KEY (`id`, `component_code`),
VECTOR KEY `vidx` (`embedding`) WITH (DISTANCE=L2,M=16,EF_CONSTRUCTION=256,LIB=VSAG,TYPE=HNSW, EF_SEARCH=64) BLOCK_SIZE 16384
) DEFAULT CHARSET = utf8mb4 ROW_FORMAT = DYNAMIC COMPRESSION = 'zstd_1.3.8' REPLICA_NUM = 1 BLOCK_SIZE = 16384 USE_BLOOM_FILTER = FALSE TABLET_SIZE = 134217728 PCTFREE = 0
partition by list(component_code)
(partition `observer` values in (1),
partition `ocp` values in (2),
partition `oms` values in (3),
partition `obd` values in (4),
partition `operator` values in (5),
partition `odp` values in (6),
partition `odc` values in (7),
partition `p10` values in (DEFAULT));
SELECT corpus.document, corpus.metadata
FROM corpus PARTITION(observer)
ORDER BY l2_distance(corpus.embedding, '[-0.022824034,0.0023560524,-0.094118156,0.036991335,-0.056135304,-0.042940456,-0.0190677,0.02940239,0.079397894,0.026218085,-0.02469267,-0.012374937,0.007202823,-0.002078379,0.031747717,-0.051177703,0.071694545,
<.... 省略若干行 ... >
-0.02610368,-0.0013573818,-0.0069406424,-0.01040143,-0.03712481,-0.039813355,-0.021355823,0.06334289,0.0072933948,0.0029721775,-0.010668377,-0.0028720722,-0.03817353,-0.0060206256,0.0634573,0.006320942,0.051559057,-0.059796304]')
APPROXIMATE limit 10;
SQL。
DEMO,不知道后续还会不会继续打磨。
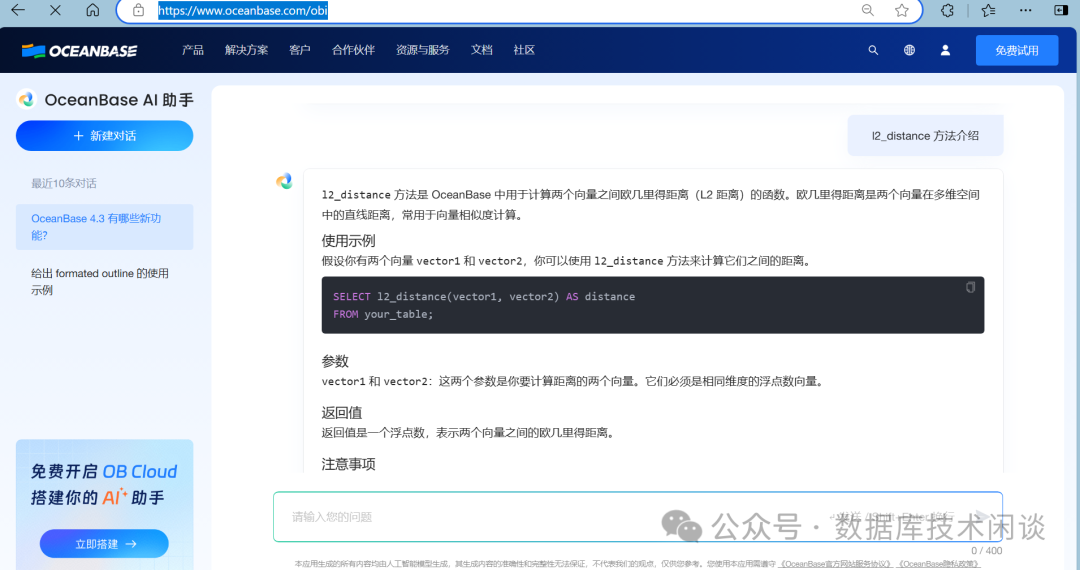
OceanBaes官网是专门推出了一个查询文档的
AI助手,使用的应该就是跟上面类似的技术。地址:
https://www.oceanbase.com/obi。
AI作图。
Stable Diffusion
大模型以及 AI
作图
Stable Diffusion是
2022年发布的深度学习文本到图像生成模型。它主要用于根据文本的描述产生详细图像,尽管它也可以应用于其他任务,如内补绘制、外补绘制,以及在提示词指导下产生图生图的转变。
Stable Diffusion模型开发的应用很多,其中有一款叫:
A绘世。
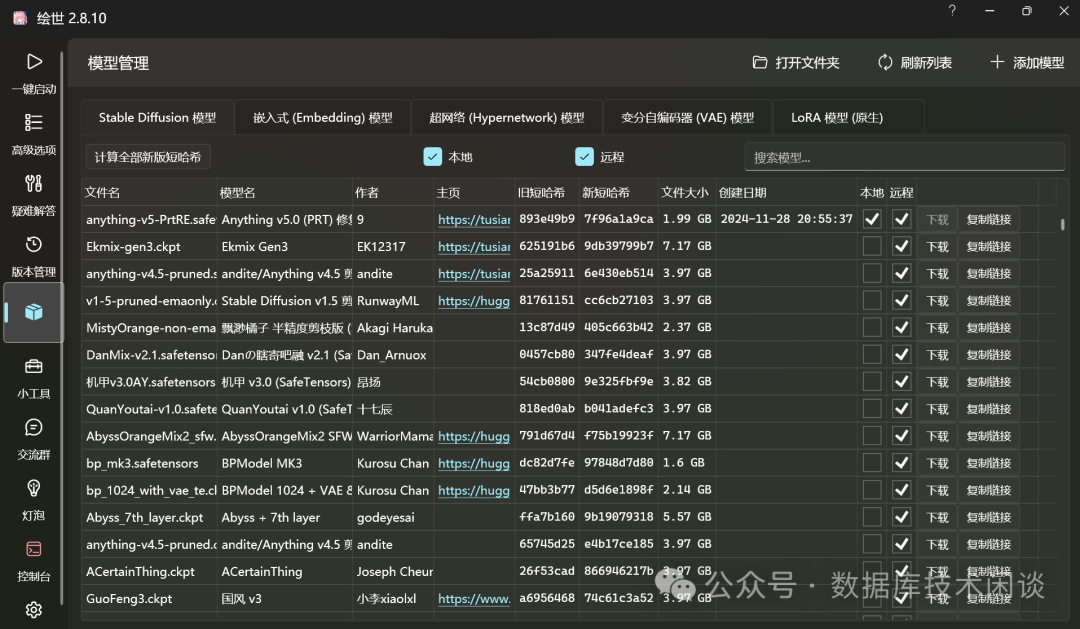
AMD 780M核显。这个产品网上介绍很多,这里就对使用效果给一个展示。
web服务。生成图片的内容取决于输入的参数,参数非常多。
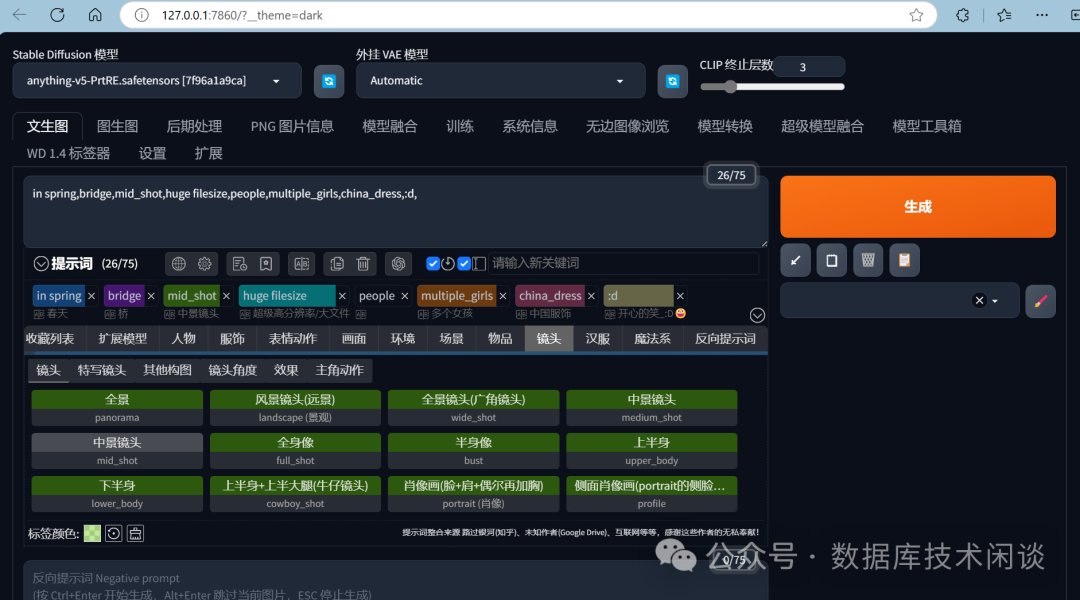
GPU生成图片的速度一般在
20s左右,如果设置的参数很多,分辨率极高,可能需要几分钟。

AI作图很强,仍不免有时候生成的图片局部细节感觉有点违和(别扭)。这个估计跟输入参数和模型的能力有关系。想要“画”一副好看的画,也是要花很多精力去调参。
参考:
https://www.wjd8.cn/archives/wei-ming-ming-wen-zhangOllama
:支持AMD 780M
核显GPU
的项目:https://github.com/likelovewant/ollama-for-amdOpen WebUI
:本地化的ChatGPT
聊天平台:https://openwebui.com/Backyard AI
全面的AI
聊天平台:https://backyard.ai/AnythingLLM: The all-in-one AI APP
:https://github.com/Mintplex-Labs/anything-llmOceanBase AI
动手实战营:https://gitee.com/oceanbase-devhub/ai-workshop-2024阿里云百炼助手: https://bailian.console.aliyun.com/OceanBase
文档AI
助手:https://www.oceanbase.com/obiOB 4.2 集群手动部署方法从大数据到大模型:现代应用的数据范式体验SQL+AI,用OceanBase搭建你的AI助手
如果还有什么有趣的使用场景,欢迎留言!
文章转载自数据库技术闲谈,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
