





❝在 Doris 执行查询时,当碰到查询性能未达预期时,建议做进一步分析情况。
本文将结合实际Case,一起学习如何通过Profile快速定位Doris查询瓶颈。

1 如何获取profile
参考文档:查询性能分析
我们时常遇到对应 SQL 执行时间不及预期的情况,为了优化 SQL 达到预期查询时延,通过 Profile 我们能够看出可以做哪些优化。现在说明在不同环境下应该如何拿到对应 Query 的 Profile。
使用请求方式(Doris 集群能够正常访问外网):HTTP://FE_IP:HTTP_PORT GET API/Profile
开启 Profile 上报参数 enable_profile
该参数开启的是 session 变量,此变量不建议全局开启(由于 Profile 收集会产生一定的开销,因此默认情况下它是关闭的)。
--开启变量
mysql> set enable_profile=true;
Query OK, 0 rows affected (0.00 sec)
--确认变量是否正常开启
mysql> show variables like '%profile%';
+----------------+-------+---------------+---------+
| Variable_name | Value | Default_Value | Changed |
+----------------+-------+---------------+---------+
| enable_profile | true | false | 1 |
+----------------+-------+---------------+---------+
1 row in set (0.00 sec)
执行对应 Query
集群在多个 FE 的情况下,需要到开启 Profile 上报参数的 FE 上执行对应 Query, 参数并没有全局生效。
--开启变量
mysql> set enable_profile=true;
Query OK, 0 rows affected (0.00 sec)
--确认变量是否正常开启
mysql> show variables like '%profile%';
+----------------+-------+---------------+---------+
| Variable_name | Value | Default_Value | Changed |
+----------------+-------+---------------+---------+
| enable_profile | true | false | 1 |
+----------------+-------+---------------+---------+
1 row in set (0.00 sec)
--执行对应 Query
mysql> select id,name from test.test where name like "%RuO%";
+---------------------------+-----------------------------------------------------------------------------------------------------------------------------+
| id | name |
+---------------------------+-----------------------------------------------------------------------------------------------------------------------------+
| 1ZWXYGbb8nr5Pi29J4cEMyEMb | ZN1nqzBRSl1rTrr99rnX1aplxhRuOUTLw6so7rzjlRQ317gTPxh0dHljmrARDJjH7FjRkJW9c7YuUBmWikq7eNgmFKJPreWirDrGrFzUYH4eP6kDtSA3UTnNIIj |
+---------------------------+-----------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.01 sec)
获取 Profile
集群在多个 FE 的情况下,需要访问执行对应 Query 的 FE HTTP 界面( HTTP://FE_IP:HTTP_PORT) 的 QueryProfile 页面,点击对应 Profile ID 查看对应 Profile,还可以在 Profile 界面下载对应 Profile。

Doris 集群访问外网受到限制
集群不能正常访问外网时,需要通过 API 的方式拿到对应 Profile
(HTTP://FE_IP:HTTP_PORT/API/Profile?Query_ID=)
IP 和端口是指执行对应 Query 的 FE 对应 IP 和端口。此时获取对应 Query 的 Profile 步骤前两步和正常访问外网时是一样的,第三步获取 Profile 时会有差别。
根据对应 Query 找到 Profile ID
-- 新版本已废弃
mysql> show query profile "/";
+-----------------------------------+-----------+---------------------+---------------------+-------+------------+------+------------+-------------------------------------------------------+
| Profile ID | Task Type | Start Time | End Time | Total | Task State | User | Default Db | Sql Statement |
+-----------------------------------+-----------+---------------------+---------------------+-------+------------+------+------------+-------------------------------------------------------+
| 1b0bb22689734d30-bbe56e17c2ff21dc | QUERY | 2024-02-28 11:00:17 | 2024-02-28 11:00:17 | 7ms | EOF | root | | select id,name from test.test where name like "%RuO%" |
| 202fb174510c4772-965289e8f7f0cf10 | QUERY | 2024-02-25 19:39:20 | 2024-02-25 19:39:20 | 19ms | EOF | root | | select id,name from test.test where name like "%KJ%" |
+-----------------------------------+-----------+---------------------+---------------------+-------+------------+------+------------+-------------------------------------------------------+
2 rows in set (0.00 sec)
查询 Profile 并将 Profile 重定向到一个文本中
# 模板:
CURL -X GET -u user:password http://fe_ip:http_port/api/profile?query_id=1b0bb22689734d30-bbe56e17c2ff21dc > test.profile
[user@VM-10-6-centos profile]$ curl -X GET -u root:root http://127.0.0.1:8030/api/profile?query_id=1b0bb22689734d30-bbe56e17c2ff21dc > test.profile
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 1211 0 1211 0 0 168k 0 --:--:-- --:--:-- --:--:-- 168k
返回的 Profile 换行符为 \ \n 分析起来很不方便,可以在文本编辑工具中将 \ \n 替换为 \n
[user@VM-10-6-centos profile]$ cat test.profile
{"msg":"success","code":0,"data":{"profile":"Query:\n Summary:\n
Profile ID: 1b0bb22689734d30-bbe56e17c2ff21dc\n - Task Type: QUERY\n
Start Time: 2024-02-28 11:00:17\n - End Time: 2024-02-28 11:00:17\n
Total: 7ms\n - Task State: EOF\n - User: root\n - Default Db: \n
Sql Statement: select id,name from test.test where name like \"%RuO%\"\n Execution Summary:\n
Workload Group: \n - Analysis Time: 1ms\n
Plan Time: 2ms\n - JoinReorder Time: N/A\n
CreateSingleNode Time: N/A\n - QueryDistributed Time: N/A\n
Init Scan Node Time: N/A\n - Finalize Scan Node Time: N/A\n
Get Splits Time: N/A\n - Get PARTITIONS Time: N/A\n
Get PARTITION FILES Time: N/A\n - Create Scan Range Time: N/A\n
Schedule Time: N/A\n - Fetch Result Time: 0ms\n - Write Result Time: 0ms\n
Wait and Fetch Result Time: N/A\n - Doris Version: doris-2.0.4-rc06-003a815b63\n
Is Nereids: Yes\n - Is Pipeline: Yes\n - Is Cached: Yes\n
Total Instances Num: 0\n - Instances Num Per BE: \n
Parallel Fragment Exec Instance Num: 48\n - Trace ID: \n"},"count":0}
替换后的效果如下
{"msg":"success","code":0,"data":{"profile":"Query:
Summary:
- Profile ID: 1b0bb22689734d30-bbe56e17c2ff21dc
- Task Type: QUERY
- Start Time: 2024-02-28 11:00:17
- End Time: 2024-02-28 11:00:17
- Total: 7ms
- Task State: EOF
- User: root
- Default Db:
- Sql Statement: select id,name from test.test where name like \"%RuO%\"
Execution Summary:
- Workload Group:
- Analysis Time: 1ms
- Plan Time: 2ms
- JoinReorder Time: N/A
- CreateSingleNode Time: N/A
- QueryDistributed Time: N/A
- Init Scan Node Time: N/A
- Finalize Scan Node Time: N/A
- Get Splits Time: N/A
- Get PARTITIONS Time: N/A
- Get PARTITION FILES Time: N/A
- Create Scan Range Time: N/A
- Schedule Time: N/A
- Fetch Result Time: 0ms
- Write Result Time: 0ms
- Wait and Fetch Result Time: N/A
- Doris Version: doris-2.0.4-rc06-003a815b63
- Is Nereids: Yes
- Is Pipeline: Yes
- Is Cached: Yes
- Total Instances Num: 0
- Instances Num Per BE:
- Parallel Fragment Exec Instance Num: 48
- Trace ID:
"},"count":0}
2 如何分析profile
如何确认慢在哪里
注:以下profile分析以2.1为例,其他版本可供参考
首先通过 Execution Summary 这部分来确定一下查询的瓶颈是在FE还是BE上。FE的情况比较少,如果是的话,看下是否有压测/线上压力情况/是否FE有GC等等,重点去看FE的CPU的压力情况。绝大部分情况都是BE这边的,然后如果是BE这边慢的话,重点去按照后面的分析去看看各个部分的算子的情况。

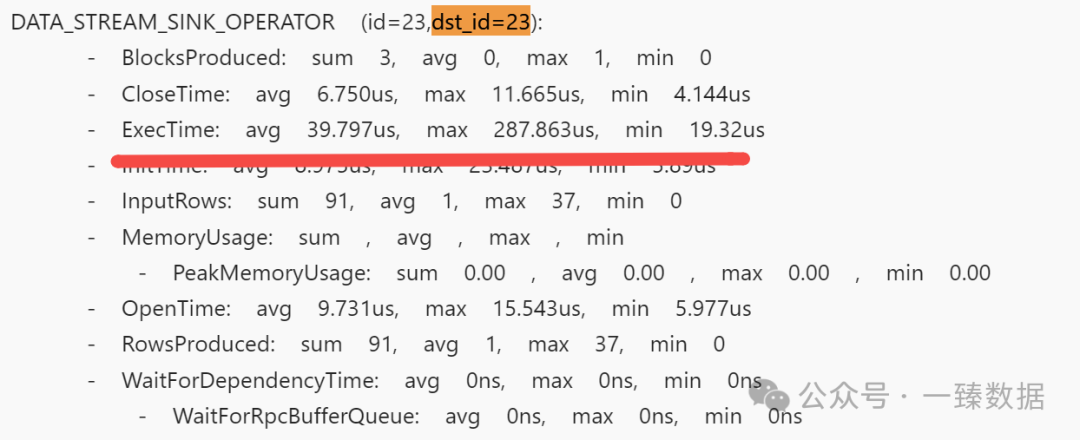
2.1的profile经过profile merge之后,显示是很精简的,我们需要通过去看每个算子的查询时间,来看具体卡在那里。这里我们重点关注,我下面划线的部分,很快就能定位到对应的问题:
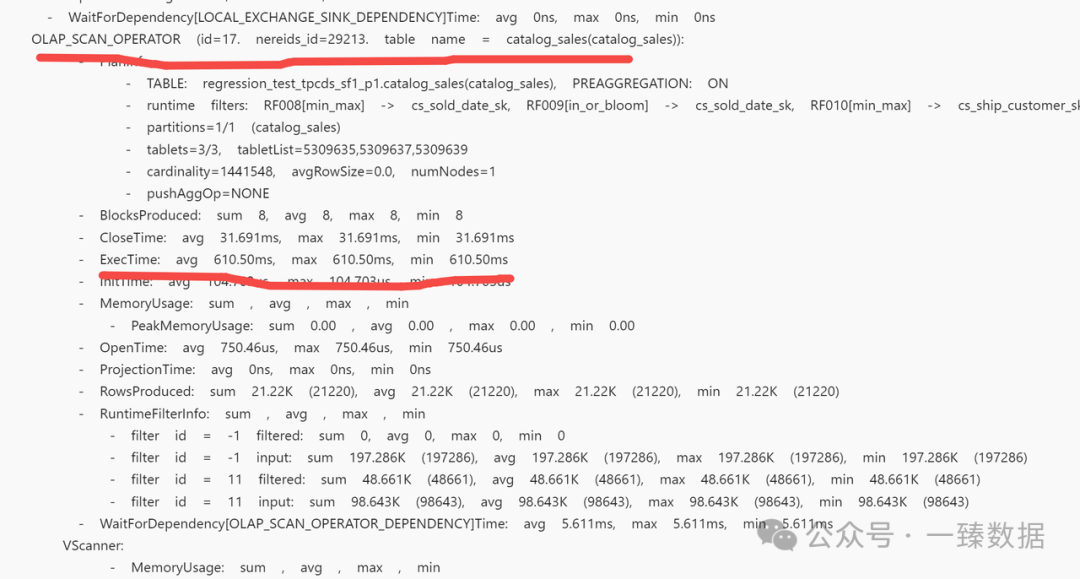
基本上顺着找下来ExecTime最大的就是最耗时的节点,顺着这个id继续往下看。如果没有最大的,大家都差不多,说明没有明确的热点。
ps:如果是使用2.1.4 selectdb以后包的webui,则可以直接看慢在哪里
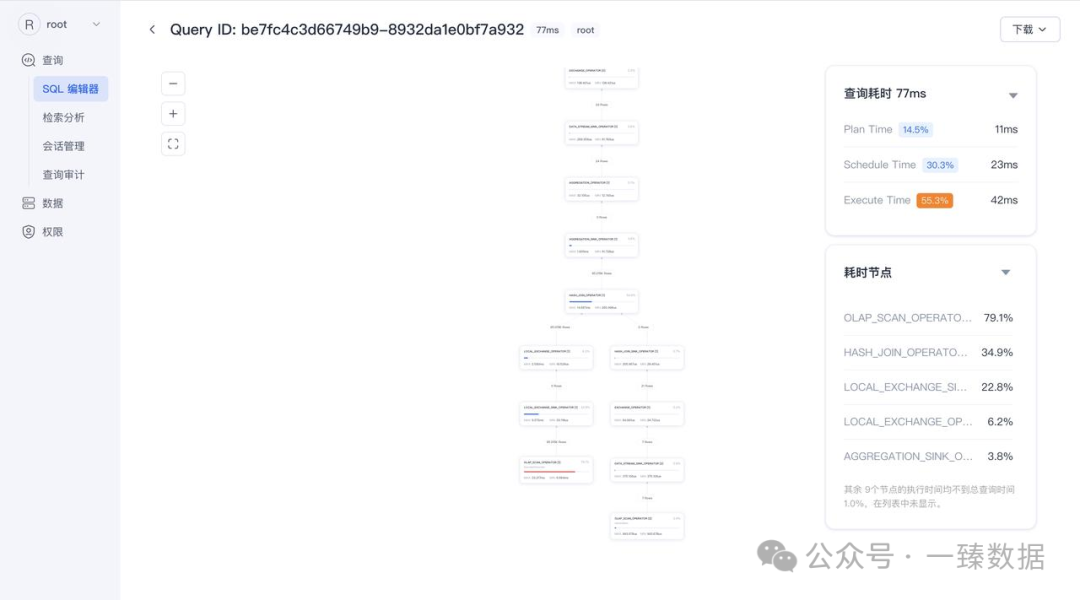
常见问题的处理方案
如果发现热点出在nested loop join上的话,首先看一下能否通过改sql的方式,让nested loop join变成hash join 那么性能能得到明显的提升
热点在join上的话,问题排查就会更加复杂一些了:
2.1 首先看join order的顺序,这个是重中之重
(1)最简单条目数上看是否合理,如果右表条目数显著大于左表,需要社区的同学介入进行问题的排查调优
Build端:

Probe端:
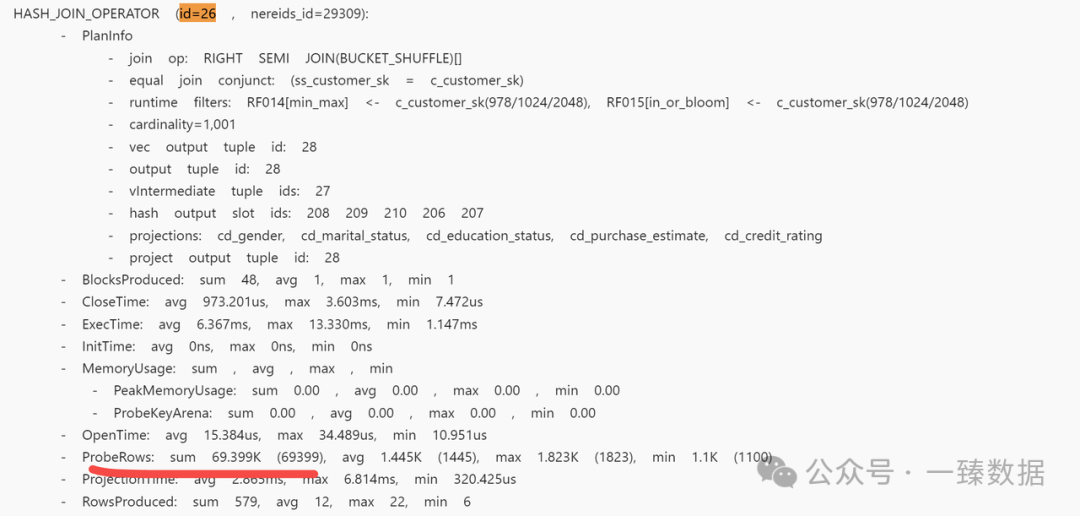
(2)这种情况相对少见,如果出现左右表数据量差不多,或者右表的条目数显著小于左表时候,也不一定join reorder是合理情况。这个时候需要判断右表的列是不是显著的大于左表,比如右表是一个大宽表,而左表可能只扫描一列,这种情况下导致的性能问题也认为是join reorder的问题.
2.2 Runtime filter
(1) 排查rf是否生效,等待时间是否合理,是否应该规划的rf没有规划

(2)是否规划多余或者无用的rf,导致了性能的问题,和无谓的等待时间

2.3 join列的优化
(1)能建非null的列就一定建成非null,尤其是join列和group by列
(2)能建立定长列就不用变长列:比如用户的id,订单id,ip地址,很多时候可以用bigint代替string
(3)join的shuffle方式是否合理,如果Join之前的Exchange很费:
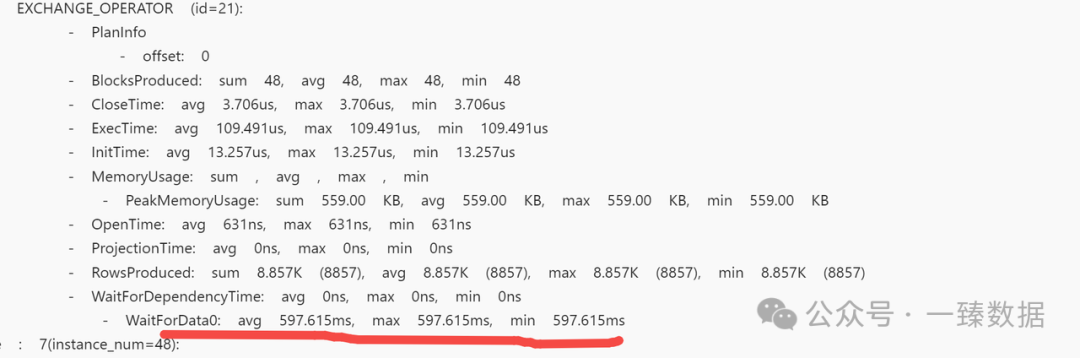
注:下面这个图搜的id应该也是21
Broadcast <-> shuffle 能否用colocate优化 Bucket shuffle的优化
2.4 热点在agg上
(1) 参考join列的优化方式来进行优化
(2) 表结构调整,比如能不能group by的列作为表的分桶列,或者分区列,这种对单表聚合的优化有奇效
2.5 scan上慢,这种情况就比较复杂了,通常的经验如下
参考下面步骤进行排查
在Doris 里不同的表引擎的查询性能差异比较大,查询性能由好到差依次为 duplicate key > merge on write unique key > merge on read unique key == aggregate key。
所以一般的时候,如果没有特殊要求,都建立duplicate key ,可以避免很多问题。
使用以下sql 检查,是否分桶有数据倾斜问题
select 分桶列,count(*) from table grou p by 分桶列 order by count(*) desc limit 100;
注意key列的顺序问题。因为doris 底层存储引擎按照key列 做了排序存储,这样可以快速的做hash查找。
2.6 观察表的compaction情况
(1) 找到慢scan的tablet:

(2) 找到compaction情况的链接:

这里需要查看多个副本的情况,如果有慢副本的话,可以通过set use_fix_replica 绕过。但是对应的情况要找官方同学来进行分析。
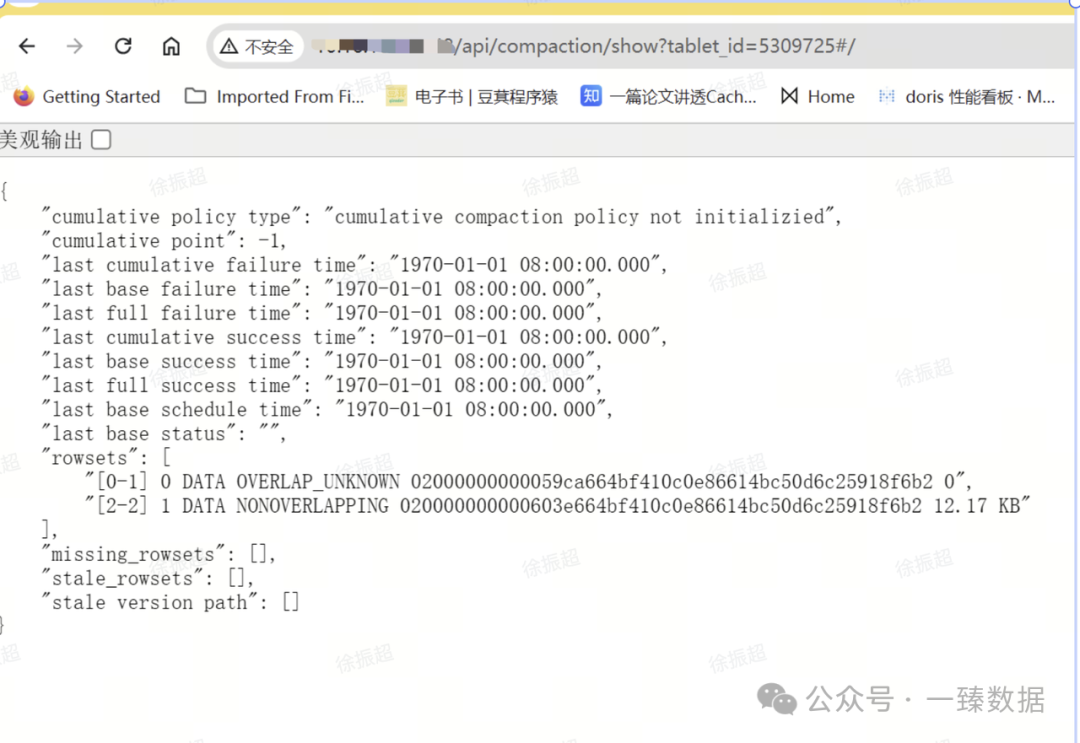
常见会出现慢的就是这么几大算子,也给了一些初步判断和定位方式。如果对于慢的算子,仍然没有头绪的话,可以找Doris社区同学协助处理。
下期,我们将一起探讨其它更有趣有用有价值的内容,敬请期待!

一臻数据致力于大数据AI时代的前沿内容分享,会持续分享更多有趣有用有态度的知识。同时也欢迎大家投稿,共建共进,帮助圈友们冲破认知壁垒,实现自我提升!
另外,整理了份《一臻数据知识库》,其中包含 Apache Doris 和 Data+AI 的学习资料、学习课程、白皮书、研究报告、行业标准 和 实践指南 等内容,会持续更新,欢迎关注公众号,免费领取。
资料获取 🔗 欢迎扫描下方二维码图片 备注【Doris】免费领取❗️

往期推荐

点击下方蓝字关注一臻数据
