





“数据就像魔方,每个维度都藏着独特的故事。
你是否遇到过这样的场景:老板要看用户数据,同事说"去重一下吧",结果等了一个世纪那么久,服务器都快冒烟了。又或者费尽心思优化SQL,看着那个孤独的DISTINCT,望眼欲穿...
数据去重就像减肥,每个人都知道要做,但怎么做才最高效?精确统计像是严格的断食,准确但煎熬;近似计算则像是快乐减肥,轻松但总觉得差了点什么。
今天我们就来聊聊基于Doris如何用"妙手"解决这个让工程师们又爱又恨的去重难题。

Doris数据去重的艺术
大规模数据处理中,去重计算就像一把双刃剑。记得刚入行时,一位资深数据工程师给我讲过这样一个故事:他们的广告平台每天要处理上亿级别的用户行为数据,最初用普通的DISTINCT计算,结果到了月底跑统计时,整个集群就像陷入泥潭,性能直线下降。
这个经典场景道出了大数据从业者的共同烦恼 - 如何在保证准确性和性能之间找到最佳平衡点?
今天我们就来聊聊Apache Doris在面对这个挑战时提供的两种绝妙解决方案:BITMAP精确去重和HLL近似去重。就像中国功夫讲究刚柔并济,这两种方案各有特色,恰如太极的阴阳两面,完美互补。

BITMAP精确去重:追求极致准确性的艺术
设想一个电商平台的日常场景:每个用户都有独特的行为轨迹,从浏览商品到下单支付,产生海量的行为数据。传统的去重方案在处理这些数据时往往力不从心,就像用小勺子舀大海。Doris创新性地引入和优化了BITMAP正交计算的概念。
核心创新点在于将BITMAP列的值按Range范围划分到不同的分桶中,确保各个分桶中的BITMAP值相互正交。打个形象的比喻,这就像把一个大型超市的商品按区域分类存放,每个区域独立管理,既不重叠也不遗漏。当需要统计整体数据时,各个区域的数据可以快速汇总,极大提升了计算效率。
比如在用户画像分析中,我们可能需要精确统计"25-35岁的北京用户中同时购买了手机和笔记本电脑的人数"。使用BITMAP正交计算,可以这样优雅地实现:
SELECT BITMAP_COUNT(
orthogonal_bitmap_intersect(
user_id,
tag,
'age_25_35',
'location_beijing',
'bought_phone',
'bought_laptop'
)
) FROM user_behavior_bitmap;
这种方案不仅保证了结果的精确性,还通过分布式计算显著提升了性能。在实际业务中,当数据量达到百亿级别时,查询性能相比传统方案提升了3-5倍。
HLL近似去重:概率统计的艺术之美
统计学告诉我们,在处理海量数据时,有时"差不多"就OK了。HyperLogLog(HLL,可替count distinct)就像一个数学魔法师,用极小的存储空间就能给出惊人准确的估算结果。它的原理让我想起小时候玩的抛硬币游戏 - 通过观察连续出现正面的次数,居然就能推算出大致抛了多少次。
HLL在Doris中的实现精妙绝伦。它的时间复杂度是O(n),空间复杂度仅为O(mloglogn),在保证1-2%误差范围内完成去重统计。这就像是一位经验丰富的餐厅经理,不用一个个数就能准确预估今天的客流量。
我们来看一个实际的日活用户(DAU)统计场景。假设一个互联网应用每天产生5000万用户访问记录,需要按小时、天、周、月多个维度统计UV。传统方案需要存储完整的用户ID,而使用HLL的表结构设计如下:
CREATE TABLE user_visits(
visit_time DATETIME,
channel VARCHAR(66),
user_id HLL HLL_UNION,
)
AGGREGATE KEY(visit_time, channel)
DISTRIBUTED BY HASH(channel);
数据导入时,只需要简单地使用HLL_HASH转换:
INSERT INTO user_visits
SELECT visit_time, channel, HLL_HASH(user_id)
FROM raw_visits;
查询各时间维度的UV简单高效:
-- 小时级UV
SELECT DATE_FORMAT(visit_time, '%Y-%m-%d %H'),
HLL_UNION_AGG(user_id)
FROM user_visits
GROUP BY DATE_FORMAT(visit_time, '%Y-%m-%d %H');
这种方案在处理百亿级数据时,查询性能提升了10倍以上,同时保持了极高的准确性。真正做到了性能和精度的完美平衡。
智能选择:如何选对最佳去重方案
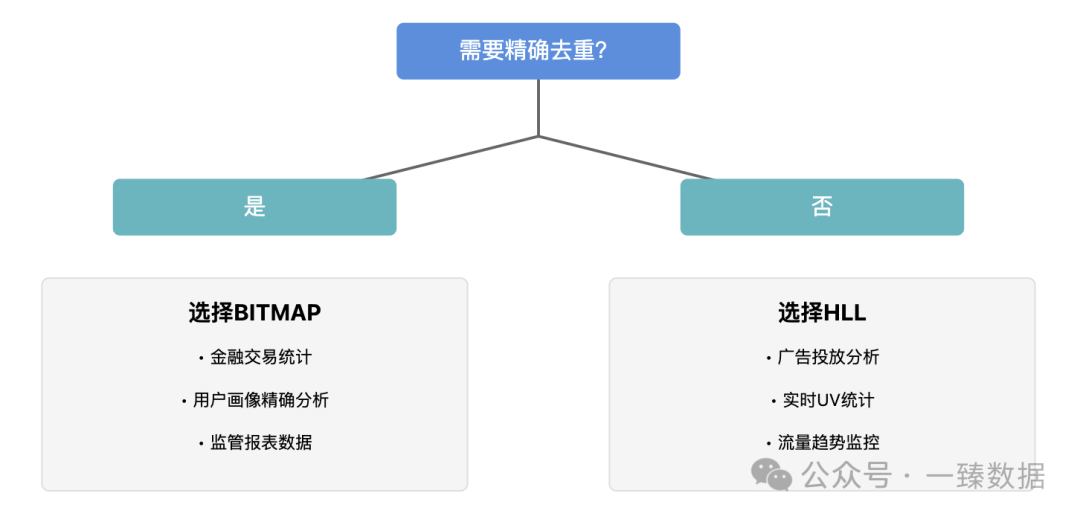
数据处理就像武功修炼,没有最好的武功,只有最适合的心法。在实际业务中,BITMAP和HLL各自有最适合的应用场景。让我分享一些实战经验。
高精度场景下的BITMAP实践
金融类业务最讲究"分毫不差"。记得一个支付平台的案例,需要精确统计用户的各项业务指标用于监管报表。这时BITMAP成为不二之选。推荐的技术要点:
-- 设计要点:hid列作为分桶依据
CREATE TABLE payment_stats (
biz_date DATE,
user_type INT,
hid SMALLINT, -- 分桶ID
user_bitmap BITMAP BITMAP_UNION
)
AGGREGATE KEY(biz_date, user_type, hid)
DISTRIBUTED BY HASH(hid) BUCKETS 32;
-- 导入时
SET user_bitmap = BITMAP_HASH(user_id)
关键是分桶数量的选择(1个Bucket建议存~10G数据),这就像太极拳讲究"以柔克刚",通过合理分解化解数据处理的压力。
高性能场景下的HLL应用
广告和推荐系统最需要的是快速响应。一个短视频平台每天处理100亿级别的用户互动数据,用HLL完美解决了实时人群分析的难题:
-- 灵活的多维度统计
SELECT
video_category,
region,
HLL_UNION_AGG(viewer_id) as uv,
HLL_UNION_AGG(liker_id) as like_uv,
HLL_UNION_AGG(sharer_id) as share_uv
FROM user_behavior
GROUP BY video_category, region;
处理海量数据时,一些小技巧可以让性能更上一层楼:
预聚合是关键 - 通过合理设计Rollup和运用agg表 批量导入优于频繁小批量更新 合理使用分区分桶,避免数据倾斜
数据去重就像是厨师掌握火候,既要保证菜品的美味,又要控制好烹饪时间。Doris的这两种去重方案就像是厨师手中的两把刀,精确去重是切片刀,精准但需要技巧;近似去重则是片刀,快速但需要把握尺度。
下期,我们将一起探讨Doris其它更有趣有用有价值的内容,敬请期待!

一臻数据致力于大数据AI时代的前沿内容分享,会持续分享更多有趣有用有态度的知识。同时也欢迎大家投稿,共建共进,帮助圈友们冲破认知壁垒,实现自我提升!
另外,整理了份《一臻数据知识库》,其中包含 Apache Doris 和 Data+AI 的学习资料、学习课程、白皮书、研究报告、行业标准 和 实践指南 等内容,会持续更新,欢迎关注公众号,免费领取。
资料获取 🔗 欢迎扫描下方二维码图片 备注【Doris】免费领取❗️

往期推荐

点击下方蓝字关注一臻数据
