





Pinecone向量数据库现在可以直接运行GenAI推理,以提升检索增强型生成(RAG)的性能。
Pinecone提供向量嵌入数据库,供AI语言模型在构建聊天机器人用户请求的响应时使用。向量嵌入是文本、图像、音频和视频对象在语义搜索中使用的多维符号表示,被大型语言模型(LLMs)和小语言模型(SMLs)所使用。该公司表示,其数据库现在包括完全托管的嵌入和重排模型,以及一种“新颖方法”的稀疏嵌入检索功能,与其现有的密集检索特性相结合。

Edo Liberty
Pinecone首席执行官Edo Liberty(前AWS和Yahoo研究总监)表示:“通过将内置的、完全托管的推理能力直接集成到我们的向量数据库中,以及新的检索功能,我们不仅简化了开发过程,还显著提高了AI驱动解决方案的性能和准确性。”
现在被称为平台的数据库增加了以下功能:
- pinecone-rerank-v0专有重排模型
- pinecone-sparse-english-v0专有稀疏嵌入模型
- 新的稀疏向量索引类型
- Cohere的Rerank 3.5模型集成
- 新的安全特性,包括基于角色的访问控制(RBAC)、审计日志、客户管理的加密密钥(CMEK)和AWS PrivateLink专用端点的普遍可用性
GenAI语言模型在对向量数据库进行语义搜索时使用的密集检索,利用所有相关向量。稀疏检索是一种关键词搜索方法,其中只有特定的单词和术语被向量化,而向量嵌入中的所有其他维度被赋予零值。关键词可以被表示为稀疏向量,每个关键词对应向量空间中的一个维度。
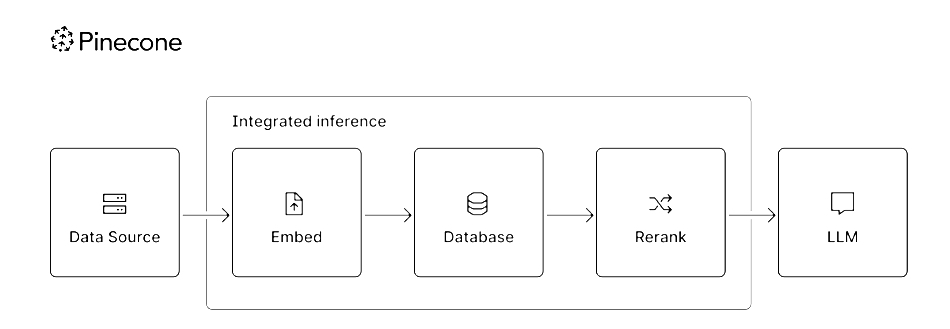
Pinecone集成推理图
该公司表示,它已与Cohere合作,在Pinecone平台内原生托管Cohere Rerank 3.5,并且可以通过Pinecone API选择。它说Rerank 3.5擅长理解跨语言的复杂业务信息,使其成为全球组织在金融、医疗保健、公共部门等行业的理想选择。
Pinecone表示,其新的专有重排和嵌入模型,以及像Cohere的Rerank 3.5这样的第三方模型,为客户提供“快速、便捷的高质量检索”。这些增强功能显著简化了基于AI的应用开发。
“基于AI的应用”意味着不太可能产生幻觉或生成虚构的响应。
该公司表示,其研究表明,要从GenAI模型中获得最佳性能,需要结合三个关键组件:
- 密集向量检索以捕捉深层语义相似性
- 快速而精确的稀疏检索,使用专有的稀疏索引算法进行关键词和实体搜索
- 一流的重排模型,结合密集和稀疏结果,最大化相关性
重排模型接收信息检索管道的第一个响应,并重新排序(重排)列出的条目,以确保更相关的条目排名更高,以提高检索效果。
Pinecone声称,通过在其数据库中结合稀疏检索、密集检索和重排能力,“开发者将能够创建端到端检索系统,比单独使用密集或稀疏检索提供高达48%,平均24%更好的性能。”它说:
- pinecone-rerank-v0在Benchmarking-IR (BEIR)基准测试上,比行业领先模型提高搜索准确性高达60%,平均9%
- pinecone-sparse-english-v0提高了基于关键词的查询性能,提供比BM25在Text Retrieval Conference (TREC) Deep Learning Tracks上高达44%,平均23%更好的归一化折扣累积增益(NDCG@10)
Pinecone通过其基础设施提供这些功能,通过单一API提供。它表示,开发者现在可以开发GenAI检索应用,“无需承担管理模型托管、集成或基础设施的负担”,“消除了担心向量或数据通过多个提供商路由的需求”。
客户可以通过AWS Marketplace访问Pinecone。
