





❝深夜11点,办公室里的小王对着监控屏幕陷入沉思。又一次大查询引发的"系统假死"让他抓耳挠腮。
这一幕像极了餐厅里的"霸王餐"场景 - 一个大胃王包场吃自助,其他食客只能在门外饿肚子。
"为什么我们的查询总像堵车的上班族,一个大货车就能让整条路动弹不得?"这个问题困扰着无数数据工程师。直到Apache Doris的Pipeline执行引擎横空出世,将"老式蒸汽机"般的火山模型升级成了"智能地铁网络"。
来,一起走进一段令人捧腹的技术进化史。通过老张和小王的深夜"卧谈会",揭秘Doris是如何从一个"单排选手"变成"团队竞技高手"的...
Doris执行引擎的跃迁之路
"老张,我们的数据查询系统又卡住了!"深夜,数据工程师小王一脸焦虑地冲进办公室。老张放下手中的咖啡杯,无奈地摇摇头:"又是火山爆发了吗?"
别误会,这里说的"火山"可不是自然界的那种,而是Apache Doris早期2.0之前的版本使用的火山模型执行引擎。好比,这个执行引擎就像一个老式的工厂流水线:工人A必须等工人B处理完才能继续干活,一个人打瞌睡,整条线都得跟着犯困。
这不,小王正对着监控屏幕手舞足蹈:"你看这个大查询,像个巨型鲸鱼一样,把我们的CPU资源都吞了!其他查询都在门外排队喝西北风。"老张笑着说:"这就是经典的'鲸吞效应',一个大查询独占线程,其他查询只能当望友。"
在火山模型时代,这样的"惨案"屡见不鲜。单个查询独占线程不说,CPU资源利用率低得像个早起的公园 - 空空荡荡。更糟的是,当多个查询同时到来,系统就像赶集的农贸市场,乱作一团。
幸运的是,Doris团队没有坐以待毙。他们决定给这座"火山"来次大改造,推出了全新的Pipeline->X执行模型。这就像把老式工厂升级成了智能制造车间:多条生产线并行运转,机器人自动调度,工序无缝衔接。
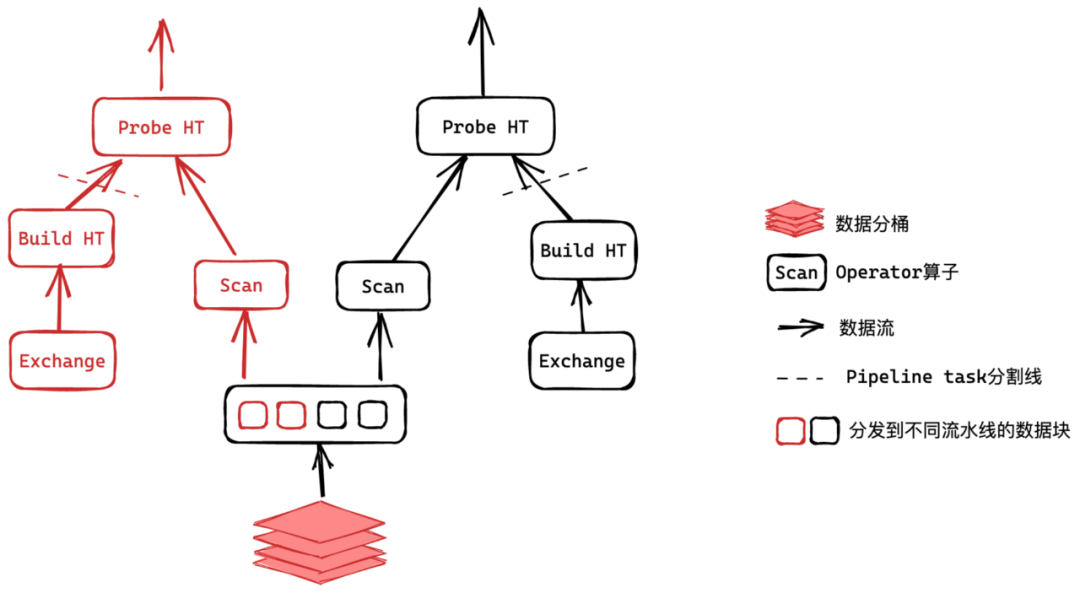
"你瞧,"老张指着新上线的监控大屏,"Pipeline模型就像给系统装上了'变形金刚'芯片。查询不再是一个庞然大物,而是被智能拆分成多个轻巧的管道。每个管道都能独立运行,彼此互不添堵。"
小王眼前一亮:"原来如此!我看这些管道像极了地铁线路,乘客分流有序,到站自动调度,运行互不干扰。"
"没错!"老张接着说,"而且我们还给它加了个'Local Shuffle',有点像是给地铁加了个智能调度系统。数据再也不会像原来那样,挤得一个站台水泄不通,其他站台门可罗雀。"
"只需要简单地设置enable_local_shuffle为 True 则打开 Local Shuffle 优化。Local Shuffle 将尽可能将数据均匀分布给不同的 Pipeline Task 从而尽可能避免数据倾斜":
set enable_local_shuffle = true;
最让人惊喜的是Doris 2.1版本后PipelineX的登场。它不仅解决了数据分布不均的问题,还像个精明的资源管家,通过共享状态复用,省下了不少重复初始化的开销。
"看这性能曲线,"小王指着监控图表,"跟坐上了火箭似的!查询响应时间砍掉一半还多,系统吞吐量蹭蹭往上涨。"
老张欣慰地点点头:"这就是技术进步的魅力。从最初的'火山喷发'到现在的'流水线生产',每一步优化都让系统更强大。"
正说着,系统告警声突然响起。小王紧张地看向屏幕,老张却胸有成竹地笑了:"放心,有了Pipeline执行引擎,这种小场面轻松搞定!"
Doris Pipeline的技术细节与创新
"说实话,我还是很好奇Pipeline到底是怎么做到这么神奇的效果。"小王掏出笔记本,准备一探究竟。
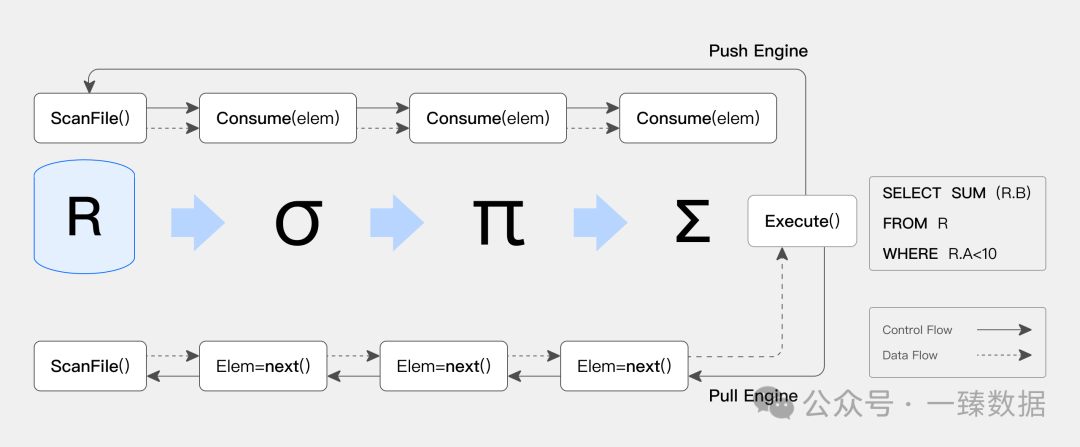
老张在白板上画起了架构图:"传统火山模型像个'等火车'的系统 - 数据在算子间靠Pull模式传递,上游必须等下游处理完才能继续。这就好比一个算子对另一个算子说:'嘿,给我点数据呗',然后就开始傻等。"
"而Pipeline模型玩了个花活。"老张继续解释,"它把SQL查询切分成多个Pipeline Task,每个Task就像一个独立的小分队。数据不用'等要',而是主动'推送' - 就像快递小哥主动送货上门。"
小王若有所思:"听起来像把'被动式营业'变成了'主动出击'啊!"
"精辟!更绝的是它的调度系统。"老张指着图上的事件驱动层,"不再是死板的轮询等待,而是基于事件触发。就像你订外卖,不用一直盯着手机看骑手到哪了,有状态更新自然会通知你。"
"等等!"小王突然想到什么,"那像Join这种需要等所有数据就绪才能处理的操作怎么办?"
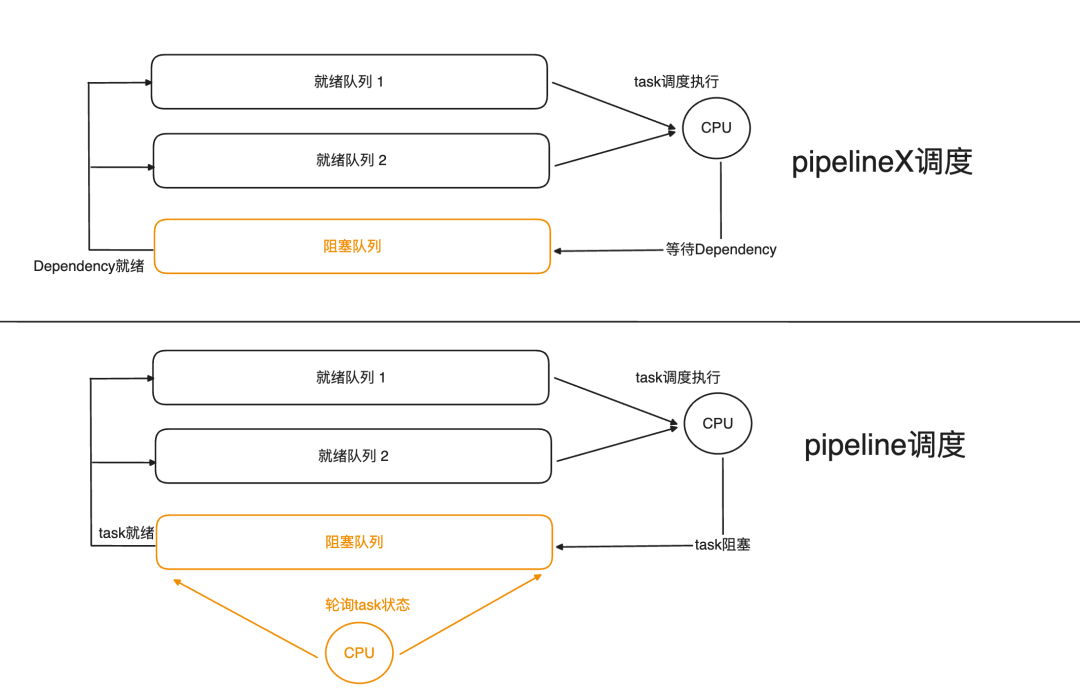
老张神秘一笑:"这就是PipelineX的高明之处。它通过Dependency机制管理任务间的依赖关系。就像项目管理里的甘特图,清晰定义了任务的前置条件。一旦条件满足,相关Task自动进入就绪队列。"
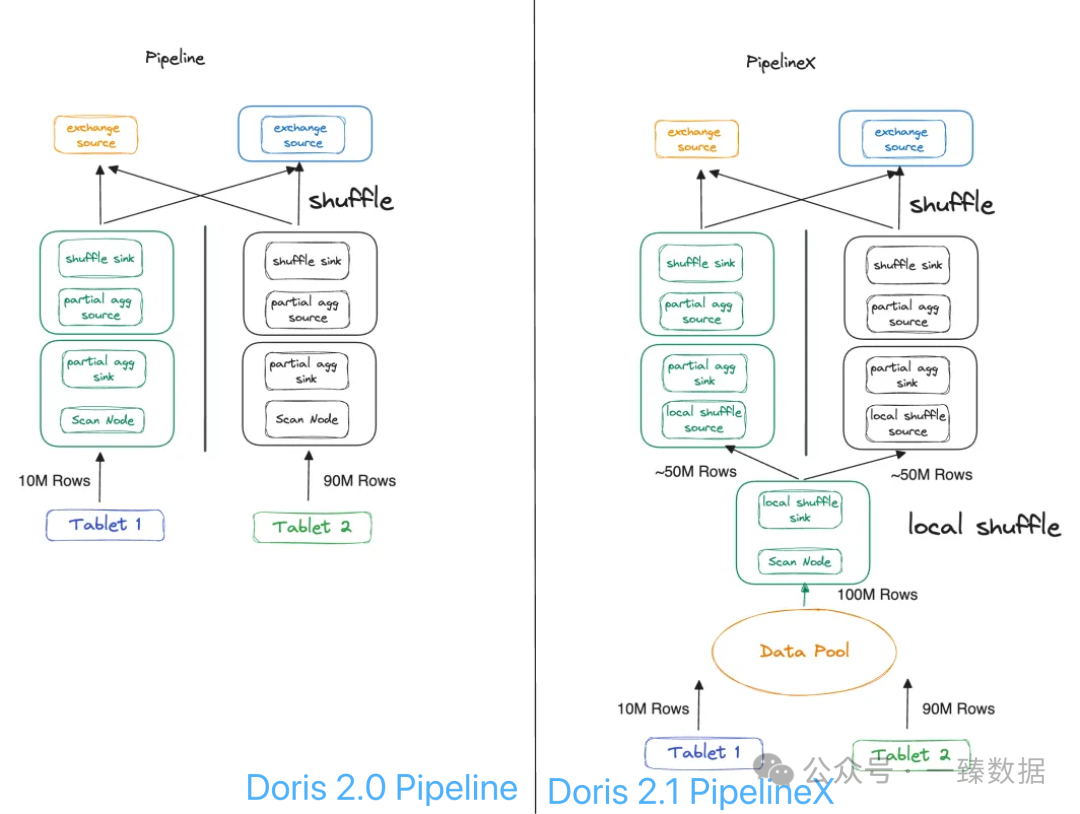
"Local Shuffle更是个点睛之笔,"老张补充道,"它让数据分布更均匀,就像高速公路的匝道管制 - 车流不会集中在某几个车道上。结合共享状态设计,还能避免重复的资源初始化,CPU利用率蹭蹭往上涨。"
"说到性能提升,来看个真实案例。"老张调出一组数据,"某电商平台的大促活动,原本一个复杂的数据分析查询要跑15分钟,可能还会影响其他业务查询。升级Pipeline后,不仅时间缩短到3分钟,而且多个查询能和谐共处,系统吞吐量提升了4倍。"
小王眼睛一亮:"这不就解决了我们之前'一卡全卡'的问题吗!"
"没错!这就是为什么我对刚才的告警这么淡定。"老张笑道,"Pipeline模型就像给系统装上了'智能大脑',能自动平衡资源,防止单个查询把系统拖垮。"
"不过,"老张话锋一转,"Pipeline的故事还没完。团队正在研究NUMA本地性优化、自适应并发调整等新特性。就像手机每年都有新款,数据库也在不断进化。"
听完这些,小王激动地合上笔记本:"太棒了!看来我得好好研究一下这些新特性。说不定下次就轮到我来解决线上问题了!"
Doris Pipeline的未来启示录
"你说得对,技术确实在不断进化。"老张翻开笔记本电脑,打开一个技术规划文档。"来看看Pipeline后续的'进化路线图'。"
"首先是NUMA本地性优化。"老张指着路线图说,"现代服务器都是多CPU多核心架构,内存访问延迟差异很大。例如,你住在北京,去上海取个快递,那肯定比在本地取件慢得多。NUMA优化就是让数据处理尽可能在'本地'完成。"
小王插话道:"就像网购选择就近仓库发货?"
"对极了!"老张笑道,"这样可以大幅减少跨NUMA节点的数据访问,提升处理效率。
"再看这个自适应并发特性。"老张切换到一张性能曲线图,"系统能根据负载情况自动调整并发度。好比春运期间动态增开列车,平时则按正常班次运行。这样既保证高峰期性能,又避免资源浪费。"
"有点意思。"小王点点头,"不用手动调参确实省心不少。"
小王突然想到什么:"说到性能,之前一个大客户抱怨查询速度不够快,我们能用这些未来特性帮他们优化吗?"
"这正是Pipeline->X模型的魅力所在。"老张开始在白板上设计方案,"我们可以结合业务特点,提前规划'专属加速方案':
用Local Shuffle解决数据倾斜(已有) 开启NUMA优化提升本地访问效率(未来) 让自适应并发处理好负载波动(未来) 结合数据落盘技术进一步提升查询的性能及可靠性(可测)
"听起来很完美!"小王兴奋地说,"不过这些优化会不会很难调试?"

老张神秘一笑:"Doris 2.1后的新版本已经优化了Profile机制。你看这个性能面板,所有Dependency的状态一目了然,跟开了'上帝视角'似的。",以 Profile 中的 Scan operator 和 Exchange Source Operator 为例:
Scan Operator:OLAP_SCAN_OPERATOR的执行总时间是 457.750ms(包括 Scanner 读数据和执行时间),因 Scanner 扫描数据阻塞了 436.883ms。
OLAP_SCAN_OPERATOR (id=4. table name = Z03_DI_MID):
- ExecTime: 457.750ms
- WaitForDependency[OLAP_SCAN_OPERATOR_DEPENDENCY]Time: 436.883ms
Exchange Source Operator:EXCHANGE_OPERATOR的执行时间为 86.691us,等待上游数据的时间为 409.256us。
EXCHANGE_OPERATOR (id=3):
- ExecTime: 86.691us
- WaitForDependencyTime: 0ns
- WaitForData0: 409.256us
正说着,老张的手机响了。"说曹操曹操到,刚才那个大客户的CTO请我们周一去做技术交流。正好可以聊聊这些规划的新特性。"
小王立刻来了精神:"带上我一个!我得好好学习这些黑科技。"
"年轻人有上进心好啊!"老张拍拍小王的肩膀,"不过记住,技术创新不是为了炫技,而是解决实际问题,就像Doris Pipeline->X模型,本质上是让数据处理更高效、更可靠。"
走出办公室时,小王若有所思:"感觉Doris Pipeline就像一个不断进化的生命体,越来越强大。"
"说得对!"老张笑道,"这就是开源的魅力 - 集众人之智,让技术不断向前。期待下个版本会带来什么惊喜!"
夜已深,但技术的未来仍在闪耀。Apache Doris的Pipeline->X执行模型,正在书写着新的篇章。
看着远处的灯火,我们知道,这不仅仅是一个技术进化的故事,更是工程师们追求卓越的"凌晨4点"。而这个"4点",只是个开始...
下期,我们将一起探讨其它更有趣有用有价值的内容,敬请期待!

一臻数据致力于大数据AI时代的前沿内容分享,会持续分享更多有趣有用有态度的知识。同时也欢迎大家投稿,共建共进,帮助圈友们冲破认知壁垒,实现自我提升!
另外,整理了份《一臻数据知识库》,其中包含 Apache Doris 和 Data+AI 的学习资料、学习课程、白皮书、研究报告、行业标准 和 实践指南 等内容,会持续更新,欢迎关注公众号,免费领取。
资料获取 🔗 欢迎扫描下方二维码图片 备注【Doris】免费领取❗️

往期推荐

点击下方蓝字关注一臻数据
