





本文字数:11186;估计阅读时间:28 分钟
本篇为第三篇《管理数据》,正文如下:
部署 ClickHouse 以支持可观测性 (Observability) 通常会涉及管理大规模数据集。为此,ClickHouse 提供了一系列功能,专门用于简化数据管理。

分区功能允许在磁盘上根据某列或 SQL 表达式对数据进行逻辑划分。每个分区可以独立操作,例如单独删除。这使得用户能够根据时间高效地在存储层之间迁移分区或其子集,或者自动过期和清理数据。
分区是在创建表时通过 PARTITION BY 子句指定的。此子句支持对任意列进行 SQL 表达式计算,计算结果决定数据行将被分配到哪个分区。
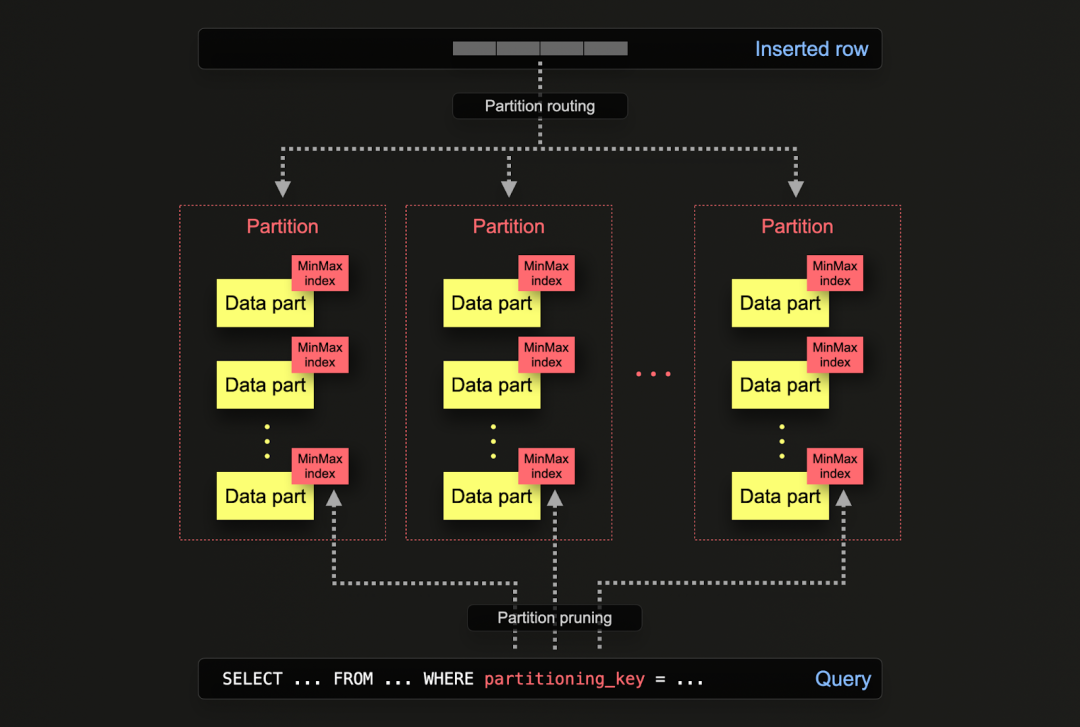
在磁盘上,每个分区通过共享的文件夹名称前缀实现逻辑关联,支持独立查询。例如,默认的 otel_logs 模式按天分区,使用表达式 toDate(Timestamp)。当数据写入 ClickHouse 时,系统会对每行数据执行该表达式。如果结果分区已经存在,数据将被路由到对应分区;如果是某天的第一条记录,系统会自动创建一个新分区。
CREATE TABLE default.otel_logs(...)ENGINE = MergeTreePARTITION BY toDate(Timestamp)ORDER BY (ServiceName, SeverityText, toUnixTimestamp(Timestamp), TraceId)
可以对分区执行多种操作,包括备份、列级别的修改、通过变更操作 (mutation) 来调整或删除数据行,以及清除索引(如二级索引)。
例如,假设 otel_logs 表按天分区。如果其中存储了结构化日志数据集,则该表会包含多天的日志数据:
SELECT Timestamp::Date AS day,count() AS cFROM otel_logsGROUP BY dayORDER BY c DESC┌────────day─┬───────c─┐│ 2019-01-22 │ 2333977 ││ 2019-01-23 │ 2326694 ││ 2019-01-26 │ 1986456 ││ 2019-01-24 │ 1896255 ││ 2019-01-25 │ 1821770 │└────────────┴─────────┘5 rows in set. Elapsed: 0.058 sec. Processed 10.37 million rows, 82.92 MB (177.96 million rows/s., 1.42 GB/s.)Peak memory usage: 4.41 MiB.
可以通过查询系统表简单地查看当前的分区:
SELECT DISTINCT partitionFROM system.partsWHERE `table` = 'otel_logs'┌─partition──┐│ 2019-01-22 ││ 2019-01-23 ││ 2019-01-24 ││ 2019-01-25 ││ 2019-01-26 │└────────────┘5 rows in set. Elapsed: 0.005 sec.
此外,我们可能会设置另一个表,例如 otel_logs_archive,用于归档较早的数据。通过分区移动,数据可以高效迁移到此归档表中(这仅需更改元数据)。
CREATE TABLE otel_logs_archive AS otel_logs--move data to archive tableALTER TABLE otel_logs(MOVE PARTITION tuple('2019-01-26') TO TABLE otel_logs_archive--confirm data has been movedSELECTTimestamp::Date AS day,count() AS cFROM otel_logsGROUP BY dayORDER BY c DESC┌────────day─┬───────c─┐│ 2019-01-22 │ 2333977 ││ 2019-01-23 │ 2326694 ││ 2019-01-24 │ 1896255 ││ 2019-01-25 │ 1821770 │└────────────┴─────────┘4 rows in set. Elapsed: 0.051 sec. Processed 8.38 million rows, 67.03 MB (163.52 million rows/s., 1.31 GB/s.)Peak memory usage: 4.40 MiB.SELECT Timestamp::Date AS day,count() AS cFROM otel_logs_archiveGROUP BY dayORDER BY c DESC┌────────day─┬───────c─┐│ 2019-01-26 │ 1986456 │└────────────┴─────────┘1 row in set. Elapsed: 0.024 sec. Processed 1.99 million rows, 15.89 MB (83.86 million rows/s., 670.87 MB/s.)Peak memory usage: 4.99 MiB.
这种方法优于其他方式,例如使用 INSERT INTO SELECT,将数据重写到目标表。
分区移动
在表之间移动分区需要满足多个条件。例如,表的结构、分区键、主键以及索引或投影必须一致。有关在 ALTER DDL 中指定分区的更多详细信息,请参考相关文档。
此外,通过分区删除数据是一种高效的方法。这种方式比使用变更操作或轻量级删除更节省资源,因此建议优先采用。
ALTER TABLE otel_logs(DROP PARTITION tuple('2019-01-25'))SELECTTimestamp::Date AS day,count() AS cFROM otel_logsGROUP BY dayORDER BY c DESC┌────────day─┬───────c─┐│ 2019-01-22 │ 4667954 ││ 2019-01-23 │ 4653388 ││ 2019-01-24 │ 3792510 │└────────────┴─────────┘
注意
当设置 ttl_only_drop_parts=1 时,TTL 功能会利用这一特性以更高效地管理数据。详细内容请参阅使用 TTL 进行数据管理的相关文档。
应用场景
以上说明了分区如何帮助高效地移动和操作数据。在实际应用中,分区操作在可观测性 (Observability) 场景中最常用于以下两种情况:
1. 分层存储架构:数据在冷热存储层之间迁移(参见存储层),以支持冷热分层的架构设计。
2. 高效删除:当数据达到指定的 TTL 时,可以快速清理(参见使用 TTL 进行数据管理)。
我们将在后续部分深入分析这两种场景。
查询性能
分区可以提升查询性能,但效果依赖于具体的访问模式。如果查询仅针对少量分区(如单个分区),性能通常会有所改善,尤其是在分区键不包含在主键中,并且查询通过分区键筛选时。然而,涉及多个分区的查询可能会因数据部分增加而变慢。如果分区键已经是主键的前几个字段,针对单个分区的性能优势会大幅降低甚至不存在。此外,当每个分区中的值是唯一时,分区还可以优化 GROUP BY 查询。总体而言,用户应优先优化主键,并仅在访问模式对某些可预测的子集(如按天分区,且查询主要集中于最近一天的数据)有明确需求时,考虑使用分区作为查询优化手段。有关这一优化行为的具体示例,请参考相关文档【https://medium.com/datadenys/using-partitions-in-clickhouse-3ea0decb89c4】。
在基于 ClickHouse 的可观测性 (Observability) 解决方案中,TTL 是一项关键功能,用于高效管理和保留数据。面对海量数据的持续增长,TTL 可以自动处理旧数据的过期和删除,优化存储资源的使用,同时保持系统性能,无需手动干预。通过聚焦于最新和最相关的数据,TTL 不仅能让数据库保持精简,还能降低存储成本并提升查询效率。此外,它还能帮助用户遵守数据保留政策,系统性地管理数据生命周期,从而增强可观测性方案的可持续性和可扩展性。
在 ClickHouse 中,TTL 可以在表级或列级进行配置。
表级 TTL
在日志和跟踪的默认架构中,通常包含一个 TTL 设置,用于在指定时间段后删除数据。这个 TTL 配置通过 ttl 键在 ClickHouse 导出器中指定,例如:
exporters:clickhouse:endpoint: tcp://localhost:9000?dial_timeout=10s&compress=lz4&async_insert=1ttl: 72h
目前,TTL 的时间配置支持 Golang Duration 语法。建议用户以小时(h)为单位设置 TTL,并确保该设置与分区周期保持一致。例如,如果表是按天分区,则 TTL 应为天数的倍数(如 24h、48h、72h)。这样可以自动为表添加 TTL 子句,例如 ttl: 96h。
PARTITION BY toDate(Timestamp)ORDER BY (ServiceName, SpanName, toUnixTimestamp(Timestamp), TraceId)TTL toDateTime(Timestamp) + toIntervalDay(4)SETTINGS index_granularity = 8192, ttl_only_drop_parts = 1
默认情况下,当 ClickHouse 合并数据部分时,过期数据会被清理。如果检测到数据已过期,ClickHouse 会触发一次非计划合并以完成删除操作。
计划的 TTL
TTL 不会立即生效,而是根据系统的计划触发。MergeTree 表的 merge_with_ttl_timeout 设置定义了执行带 TTL 的合并操作之间的最小时间间隔(以秒为单位)。默认值为 14400 秒(4 小时)。需要注意,这只是最低间隔,实际触发时间可能更长。如果该值设置过低,可能会导致频繁的非计划合并,从而消耗大量系统资源。用户可以通过命令 ALTER TABLE my_table MATERIALIZE TTL 强制执行 TTL。
重要提示:建议启用 ttl_only_drop_parts=1(默认架构已包含此设置)。启用后,当某个数据部分内的所有行都已过期时,ClickHouse 会直接删除整个部分。与部分清理过期数据行(在 ttl_only_drop_parts=0 下通过资源密集型变更操作实现)相比,删除完整部分的方式更高效,允许设置更短的 merge_with_ttl_timeout 时间,并显著降低系统性能的影响。如果数据按与 TTL 过期相同的单位(例如天)分区,则数据部分会自然限定在该时间区间内,从而使 ttl_only_drop_parts=1 得以高效应用。
列级 TTL
在上述表级数据过期的基础上,ClickHouse 还支持为列单独设置 TTL。当数据逐渐变得不再需要时,可以删除那些对调查价值较低且占用资源的列。例如,我们建议在日志数据中保留 Body 列,以防需要引用在插入时未提取的动态元数据(如新的 Kubernetes 标签)。但在经过一定时间(如 1 个月)后,如果这些元数据被确认无用,就可以删除 Body 列以优化存储开销。
以下示例展示了如何在 30 天后删除 Body 列。
CREATE TABLE otel_logs_v2(`Body` String TTL Timestamp + INTERVAL 30 DAY,`Timestamp` DateTime,...)ENGINE = MergeTreeORDER BY (ServiceName, Timestamp)
注意
要设置列级 TTL,用户需要自定义表的架构。这一功能无法通过 OTel 收集器配置。
尽管我们推荐使用 ZSTD(1) 作为默认压缩算法来处理可观测性 (Observability) 数据集,但用户也可以尝试其他压缩算法或更高的压缩级别,例如 ZSTD(3)。除了在架构初始化时定义压缩配置外,还可以设置在特定时间段后更改压缩算法。例如,一些算法可以显著提高压缩率,但可能会降低查询性能。对于查询频率较低的旧数据,这种折衷是可以接受的;而对于频繁使用的近期数据,则更适合使用性能更优的压缩方式。
以下示例展示了如何在 4 天后切换为使用 ZSTD(3) 压缩数据,而不是删除数据。
CREATE TABLE default.otel_logs_v2(`Body` String,`Timestamp` DateTime,`ServiceName` LowCardinality(String),`Status` UInt16,`RequestProtocol` LowCardinality(String),`RunTime` UInt32,`Size` UInt32,`UserAgent` String,`Referer` String,`RemoteUser` String,`RequestType` LowCardinality(String),`RequestPath` String,`RemoteAddress` IPv4,`RefererDomain` String,`RequestPage` String,`SeverityText` LowCardinality(String),`SeverityNumber` UInt8,)ENGINE = MergeTreeORDER BY (ServiceName, Timestamp)TTL Timestamp + INTERVAL 4 DAY RECOMPRESS CODEC(ZSTD(3))
性能评估
我们建议用户在选择压缩级别和算法时,同时评估其对数据插入和查询性能的影响。例如,增量编解码器 (Delta Codec) 对压缩时间戳特别有效,但如果时间戳属于主键的一部分,则可能会导致过滤性能下降。
关于 TTL 配置的更多细节和示例,请参考相关文档【https://clickhouse.com/docs/en/engines/table-engines/mergetree-family/mergetree#table_engine-mergetree-multiple-volumes】。这些示例包括如何为表和列添加或修改 TTL,以及 TTL 如何支持构建存储层次结构(如热-温架构)。有关更多信息,请参阅存储层的说明。
在 ClickHouse 中,用户可以通过不同的磁盘类型创建存储层,例如将热点数据存储在 SSD 上,而将历史数据存储在 S3 上。这样的架构能够有效降低存储成本,同时由于历史数据查询频率较低,其性能要求(查询 SLA)可以适当放宽。
不适用于 ClickHouse Cloud
ClickHouse Cloud 不支持多层存储。它将所有数据存储在 S3 中,并通过 SSD 缓存节点提供快速访问。因此,存储层功能在 ClickHouse Cloud 中并无必要。
为了创建存储层,用户需要先定义磁盘,并基于这些磁盘制定存储策略。在创建表时,可以为其指定存储卷。数据会根据磁盘的填充率、数据部分大小和卷的优先级在磁盘之间自动迁移。更多细节请参考相关文档【https://clickhouse.com/docs/en/engines/table-engines/mergetree-family/mergetree#table_engine-mergetree-multiple-volumes】。
虽然用户可以手动使用 ALTER TABLE MOVE PARTITION 命令在磁盘之间移动数据,但也可以通过 TTL 自动控制卷之间的数据迁移。有关完整示例,请参考相应的文档。
随着系统不断演进,日志和跟踪的架构难免会发生变化,例如在监控新系统时需要支持额外的元数据或新的 pod 标签。通过采用 OTel 架构生成数据,并以结构化的方式捕获事件,ClickHouse 的架构能够很好地适应这些变化。然而,当新元数据被引入或查询模式发生变化时,用户可能需要调整架构以满足新的需求。
为了避免架构更改带来的系统停机,可以采用以下方法:
使用默认值
用户可以为新列设置默认值。在插入数据时,如果未显式提供该列的值,系统将使用预定义的默认值。
架构更改可以先于物化视图的转换逻辑或 OTel 收集器配置的调整进行,这样新的列在更改完成后会被自动发送到目标表。
在完成架构更改后,可以重新配置 OTel 收集器。假设用户遵循“使用 SQL 提取结构”中推荐的流程,其中 OTel 收集器将数据发送到 Null 表引擎,并由物化视图提取目标架构并存储到目标表,则可以通过 ALTER TABLE ... MODIFY QUERY 语法修改视图逻辑。以下是一个示例,展示了目标表及其物化视图的用法(类似于“使用 SQL 提取结构”中的流程),以便从 OTel 结构化日志中提取目标架构:
CREATE TABLE default.otel_logs_v2(`Body` String,`Timestamp` DateTime,`ServiceName` LowCardinality(String),`Status` UInt16,`RequestProtocol` LowCardinality(String),`RunTime` UInt32,`UserAgent` String,`Referer` String,`RemoteUser` String,`RequestType` LowCardinality(String),`RequestPath` String,`RemoteAddress` IPv4,`RefererDomain` String,`RequestPage` String,`SeverityText` LowCardinality(String),`SeverityNumber` UInt8)ENGINE = MergeTreeORDER BY (ServiceName, Timestamp)CREATE MATERIALIZED VIEW otel_logs_mv TO otel_logs_v2 ASSELECTBody,Timestamp::DateTime AS Timestamp,ServiceName,LogAttributes['status']::UInt16 AS Status,LogAttributes['request_protocol'] AS RequestProtocol,LogAttributes['run_time'] AS RunTime,LogAttributes['user_agent'] AS UserAgent,LogAttributes['referer'] AS Referer,LogAttributes['remote_user'] AS RemoteUser,LogAttributes['request_type'] AS RequestType,LogAttributes['request_path'] AS RequestPath,LogAttributes['remote_addr'] AS RemoteAddress,domain(LogAttributes['referer']) AS RefererDomain,path(LogAttributes['request_path']) AS RequestPage,multiIf(Status::UInt64 > 500, 'CRITICAL', Status::UInt64 > 400, 'ERROR', Status::UInt64 > 300, 'WARNING', 'INFO') AS SeverityText,multiIf(Status::UInt64 > 500, 20, Status::UInt64 > 400, 17, Status::UInt64 > 300, 13, 9) AS SeverityNumberFROM otel_logs
假设我们希望从 LogAttributes 中提取一个名为 Size 的新列。可以通过 ALTER TABLE 命令将该列添加到表的架构中,并为其指定默认值:
ALTER TABLE otel_logs_v2(ADD COLUMN `Size` UInt64 DEFAULT JSONExtractUInt(Body, 'size'))
在上述示例中,默认值被设置为 LogAttributes 中的 size 键(如果该键不存在,则默认值为 0)。这意味着,对于那些未插入该键值的行,查询该列时需要访问 Map,可能会导致性能下降。为了优化查询性能,可以将默认值设置为常量(例如 0),从而降低对未插入值的行的查询成本。通过查询该表,我们可以验证 Map 中的值已成功填充到 Size 列中:
SELECT SizeFROM otel_logs_v2LIMIT 5┌──Size─┐│ 30577 ││ 5667 ││ 5379 ││ 1696 ││ 41483 │└───────┘5 rows in set. Elapsed: 0.012 sec.
为了确保未来的数据在插入时自动填充该值,可以使用 ALTER TABLE 命令修改物化视图,如以下示例所示:
ALTER TABLE otel_logs_mvMODIFY QUERYSELECTBody,Timestamp::DateTime AS Timestamp,ServiceName,LogAttributes['status']::UInt16 AS Status,LogAttributes['request_protocol'] AS RequestProtocol,LogAttributes['run_time'] AS RunTime,LogAttributes['size'] AS Size,LogAttributes['user_agent'] AS UserAgent,LogAttributes['referer'] AS Referer,LogAttributes['remote_user'] AS RemoteUser,LogAttributes['request_type'] AS RequestType,LogAttributes['request_path'] AS RequestPath,LogAttributes['remote_addr'] AS RemoteAddress,domain(LogAttributes['referer']) AS RefererDomain,path(LogAttributes['request_path']) AS RequestPage,multiIf(Status::UInt64 > 500, 'CRITICAL', Status::UInt64 > 400, 'ERROR', Status::UInt64 > 300, 'WARNING', 'INFO') AS SeverityText,multiIf(Status::UInt64 > 500, 20, Status::UInt64 > 400, 17, Status::UInt64 > 300, 13, 9) AS SeverityNumberFROM otel_logs
此后插入的新行将会在插入时自动填充 Size 列,从而简化后续查询操作。
创建新表
除了修改现有表的架构,用户还可以选择直接创建一个包含新架构的目标表。之后,使用 ALTER TABLE MODIFY QUERY 命令更新相关的物化视图,使其指向新表。通过这种方式,用户可以对表进行版本管理,例如创建 otel_logs_v3。
此方法会产生多个版本化表,需要在查询时同时访问多个表。为此,用户可以使用 merge 函数,该函数支持表名的通配符匹配。以下示例展示了如何同时查询 otel_logs 表的 v2 和 v3 版本:
SELECT Status, count() AS cFROM merge('otel_logs_v[2|3]')GROUP BY StatusORDER BY c DESCLIMIT 5┌─Status─┬────────c─┐│ 200 │ 38319300 ││ 304 │ 1360912 ││ 302 │ 799340 ││ 404 │ 420044 ││ 301 │ 270212 │└────────┴──────────┘5 rows in set. Elapsed: 0.137 sec. Processed 41.46 million rows, 82.92 MB (302.43 million rows/s., 604.85 MB/s.)
如果用户希望避免直接使用 merge 函数,可以通过 Merge 表引擎向最终用户提供一个整合多个表的统一视图。以下示例展示了如何使用 Merge 表引擎:
CREATE TABLE otel_logs_mergedENGINE = Merge('default', 'otel_logs_v[2|3]')SELECT Status, count() AS cFROM otel_logs_mergedGROUP BY StatusORDER BY c DESCLIMIT 5┌─Status─┬────────c─┐│ 200 │ 38319300 ││ 304 │ 1360912 ││ 302 │ 799340 ││ 404 │ 420044 ││ 301 │ 270212 │└────────┴──────────┘5 rows in set. Elapsed: 0.073 sec. Processed 41.46 million rows, 82.92 MB (565.43 million rows/s., 1.13 GB/s.)
当需要添加新表时,可以通过 EXCHANGE 表语法轻松更新整合。比如,添加一个 v4 表时,可以先创建新表,然后通过原子交换操作将其与之前的版本合并:
CREATE TABLE otel_logs_merged_tempENGINE = Merge('default', 'otel_logs_v[2|3|4]')EXCHANGE TABLE otel_logs_merged_temp AND otel_logs_mergedSELECT Status, count() AS cFROM otel_logs_mergedGROUP BY StatusORDER BY c DESCLIMIT 5┌─Status─┬────────c─┐│ 200 │ 39259996 ││ 304 │ 1378564 ││ 302 │ 820118 ││ 404 │ 429220 ││ 301 │ 276960 │└────────┴──────────┘5 rows in set. Elapsed: 0.068 sec. Processed 42.46 million rows, 84.92 MB (620.45 million rows/s., 1.24 GB/s.)
 注册ClickHouse中国社区大使,领取认证考试券
注册ClickHouse中国社区大使,领取认证考试券

试用阿里云 ClickHouse企业版
轻松节省30%云资源成本?阿里云数据库ClickHouse架构全新升级,推出和原厂独家合作的ClickHouse企业版,在存储和计算成本上带来双重优势,现诚邀您参与100元指定规格测一个月的活动,了解详情:https://t.aliyun.com/Kz5Z0q9G


征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出&图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com


