今天分享的是ACL2024的一篇论文:
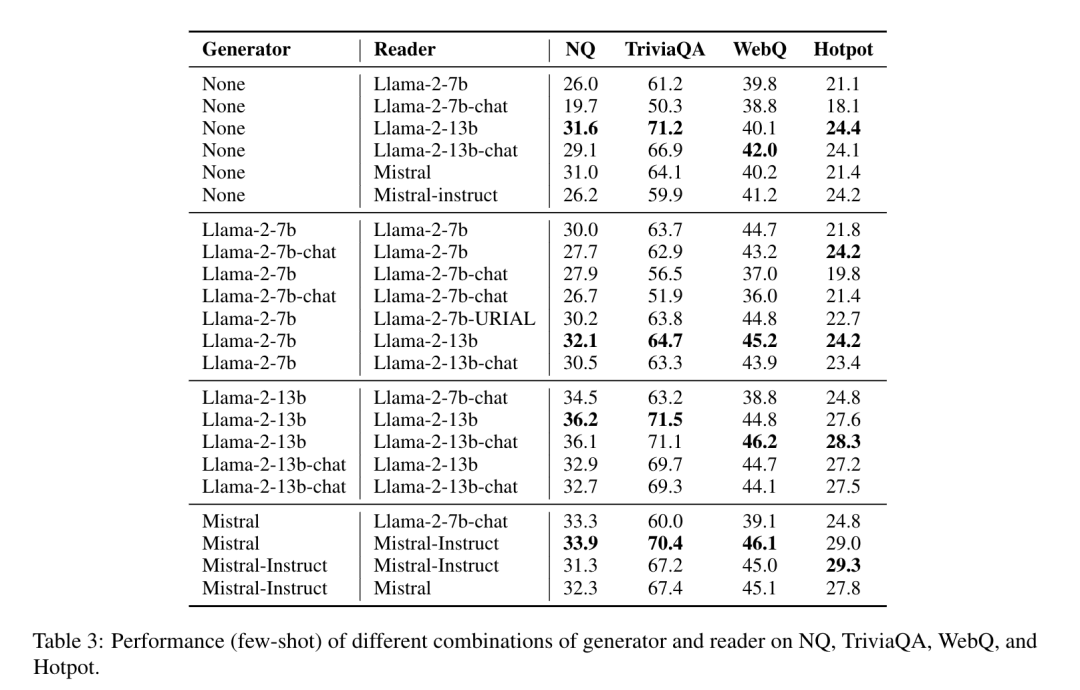
A+B: A General Generator-Reader Framework for Optimizing LLMs to Unleash Synergy Potentia。 A+B: 一种通用生成器+阅读器框架,用于优化大型语言模型以释放协同潜力。 论文链接: https://arxiv.org/abs/2406.03963 本文提出了一种名为“A + B”的通用生成器-阅读器框架,旨在优化大语言模型(LLM)并发挥其协同潜力。该框架通过将检索增强生成(RAG)中的检索阶段替换为LLM自身的生成阶段,以解决检索器性能的瓶颈问题。研究通过对基础模型和类型的不同组合进行系统研究,发现LLM的base版本和chat版本分别适合作为生成器A和阅读器B。这些组合在复杂场景下 consistently 表现优于单一模型。
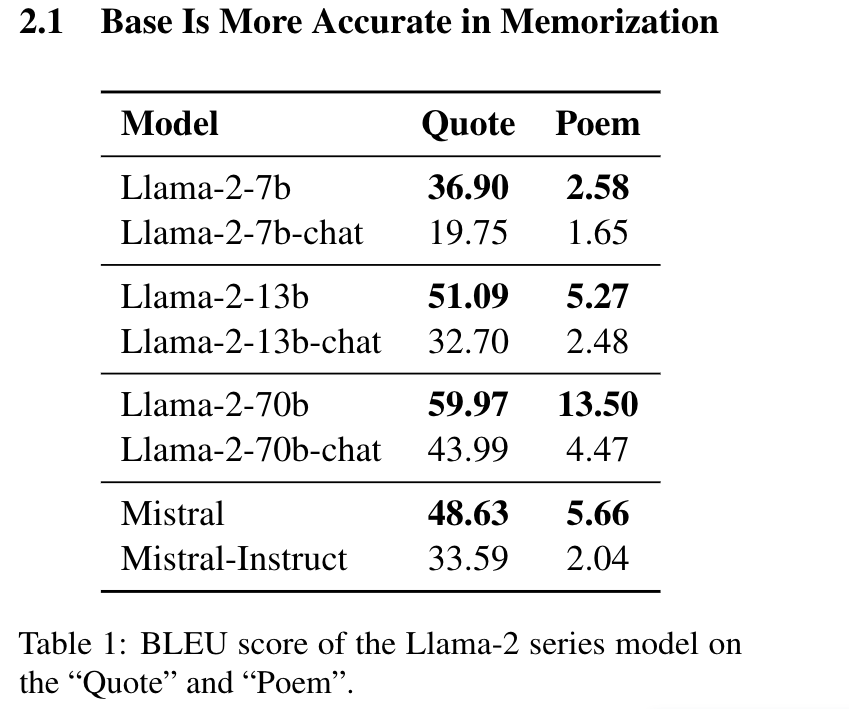
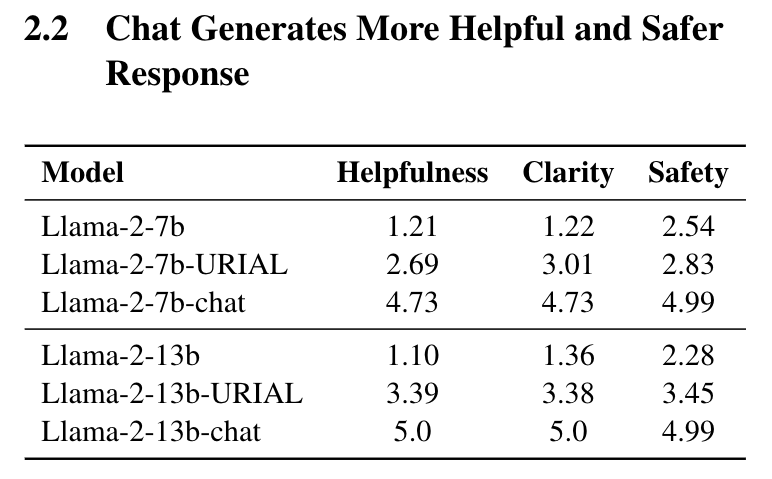
在知识密集型任务中必须考虑两个关键方面:准确的知识和高质量的生成。前者要求大语言模型生成与事实知识一致的内容,而后者则要求回答的内容既有帮助又无害,与人类偏好相符。最近,研究人员注意到微调可能会无意中削弱大语言模型传达事实信息的能力。具体而言,经过监督微调(SFT)的LLMs在评估事实知识和推理能力的基准测试中的表现较其基础模型明显下降。 这一观察引发了一个重要问题:未对齐和已对齐模型是否更适合于特定角色在知识密集型任务中,例如作为生成器和阅读器?为此,文章进行预实验,以评估不同版本的大型语言模型——未对齐和已对齐——在知识记忆和回应生成方面的表现。 预实验分为两个部分,分别是评估模型的知识记忆能力和模型的回答的有效性。实验结果来看,base模型 更能记住训练阶段的数据,而chat模型 更能生成与人类偏好相符的有效回答。 base模型 负责根据输入查询生成相关信息。需要高度的事实准确性,以确保生成的内容与事实相符。可以使用不同类型或版本的 LLM,例如未经对齐的基础模型,它们在知识记忆方面表现出色。
chat模型 负责解释生成的内容并提供适当的回答。需要认知推理和与人类偏好的一致性,以确保生成的回答既安全又有用。可以使用经过对齐的聊天模型,它们在生成符合人类偏好的回答方面表现出色。
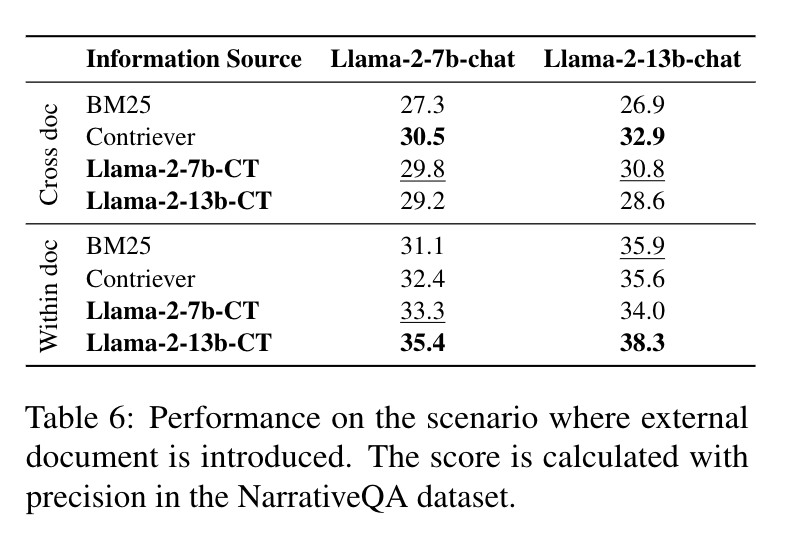
基于A+B框架的实验结果也验证了base模型 作为生成器和chat模型 作为阅读器的能力。 RAG的主要应用场景在于特定领域的语料不在预训练数据集中时通过检索的内容来补充知识。为了验证这种场景,本文在 NarrativeQA数据集 (基于小说、剧本的QA数据集)中将大量的小说、剧本作为预训练的语料继续训练Llama2-7B 和Llama2-13B 。实验结果如下表。 实验划分了两类问题,分别是在单文档内可以回答的问题和跨文档回答的问题。作者认为,虽然训练没有精心标注数据集,但两个场景的精确度均和RAG结果相近,甚至高于RAG。 本文通过A+B框架 达到了和RAG类似的结果,规避了检索效果和性能瓶颈的问题。但文章只对比了Llama7B 和Llama13B 的效果,期待看到更多类似的方案在更大参数量模型上和RAG的效果对比。 李剑楠: 华东师范大学硕士研究生,研究方向为向量检索。曾作为核心研发工程师参与向量数据库、RAG 等产品研发,代表公司参加 DTCC、WAIM 等会议进行主题分享。