




今天分享的是北京邮电大学和香港大学联合发表的一篇文章:图结构数据进行增强的RAG系统——LightRAG
论文题目:LightRAG: Simple and Fast Retrieval-Augmented Generation

论文链接:https://arxiv.org/pdf/2410.05779

01
论文概述
02
论文核心
02
论文核心
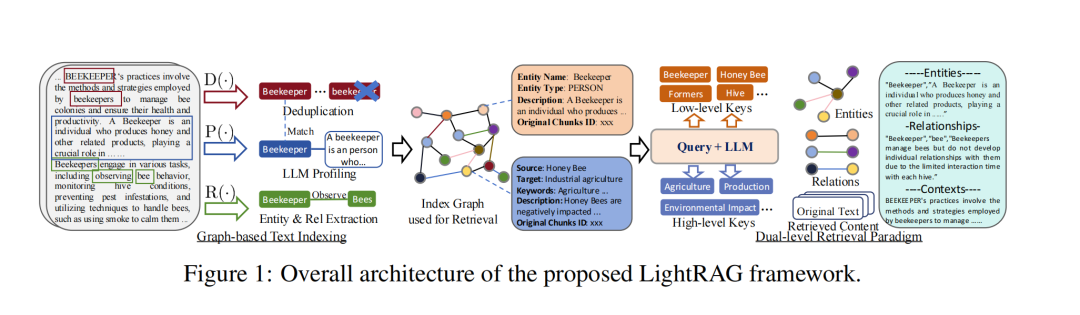
基于图的文本索引
在LightRAG中数据索引涉及以下几个步骤:
文档分割:LightRAG系统首先将文档分割为更小、更易管理的部分,从而能够快速定位和访问相关信息,而无需分析整个文档。 实体关系提取:利用大型语言模型(LLM)从片段中识别和提取各类实体以及它们之间的关系,这些信息用于构建知识图谱。例如,从“心脏病专家评估症状以识别潜在的心脏问题”这句话中提取出“心脏病专家”和“心脏病”等实体,以及“心脏病专家诊断心脏病”等关系。 知识图谱去重:识别并合并来自不同片段的相同实体和关系,最小化图减少冗余信息,实现高效的数据处理。 LLM增强分析:采用LLM驱动的分析函数为每个实体节点和关系边生成一个文本的键值对。每个索引键是一个单词或短短语,便于高效检索,对应的值是一个文本段落,总结了来自外部数据的相关片段,有助于文本生成。实体使用其名称作为唯一索引键,而关系可能有多个索引键,这些索引键源于LLM增强,包括来自连接实体的全局主题。 增量更新算法:为了有效适应不断变化的数据,LightRAG采用增量更新算法。对于新文档,该算法使用与之前相同的基于图的索引步骤进行处理,得到新文档的图结构索引。
双层检索算法
低级检索(Low-Level Retrieval):这种检索策略主要聚焦于检索特定实体以及它们相关的属性或关系。查询是细节导向的,旨在从图中提取关于特定节点或边的精确信息。比如在一个包含众多学术论文的知识图中,如果查询某一特定研究人员的某项具体研究成果,低级别检索就会针对该研究人员实体及其相关研究成果的关系进行精确查找。 高级检索(High - Level Retrieval):该检索策略旨在处理更广泛的主题和总体主题。这类查询会聚合多个相关实体和关系的信息,提供对更高级别概念和总结的洞察,而不是特定细节。例如,当查询“人工智能在医疗领域的应用趋势”时,高级别检索会综合多个与人工智能和医疗相关的实体及关系信息,给出关于应用趋势的总体概述。
提取关键词:使用大模型从用户查询中提取出全局关键词和局部关键词。 检索查询:基于向量数据库,将局部查询关键词与候选实体匹配,将全局关键词与连接到全局关键点的关系进行匹配,这一过程类似于传统RAG,但是专注于检索实体和关系。 查找高阶信息:利用图的高阶连接信息,LightRAG 进一步收集检索到的图元素对应的局部子图中的邻居节点。
03
论文实验
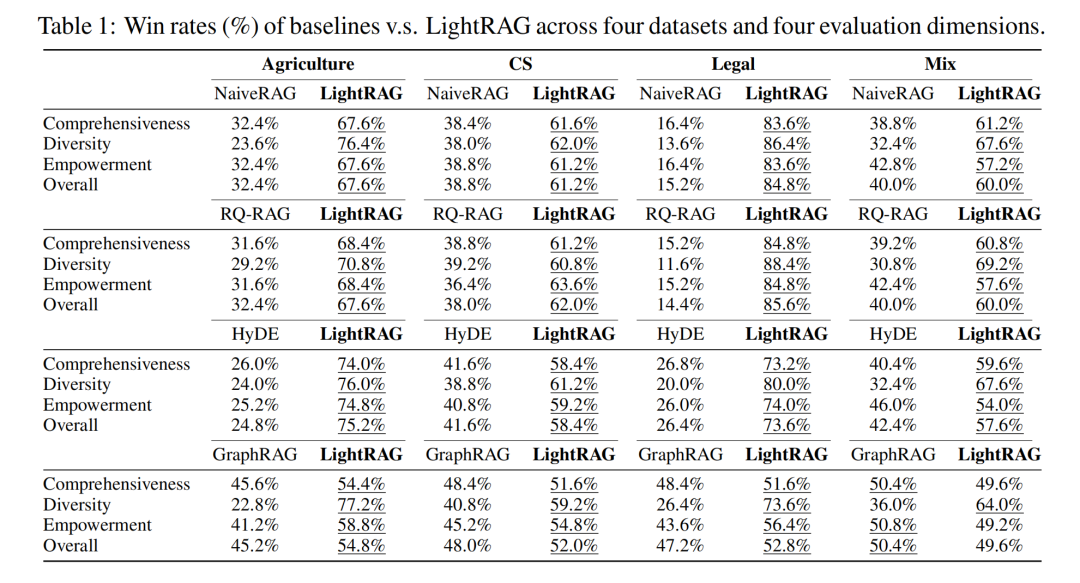
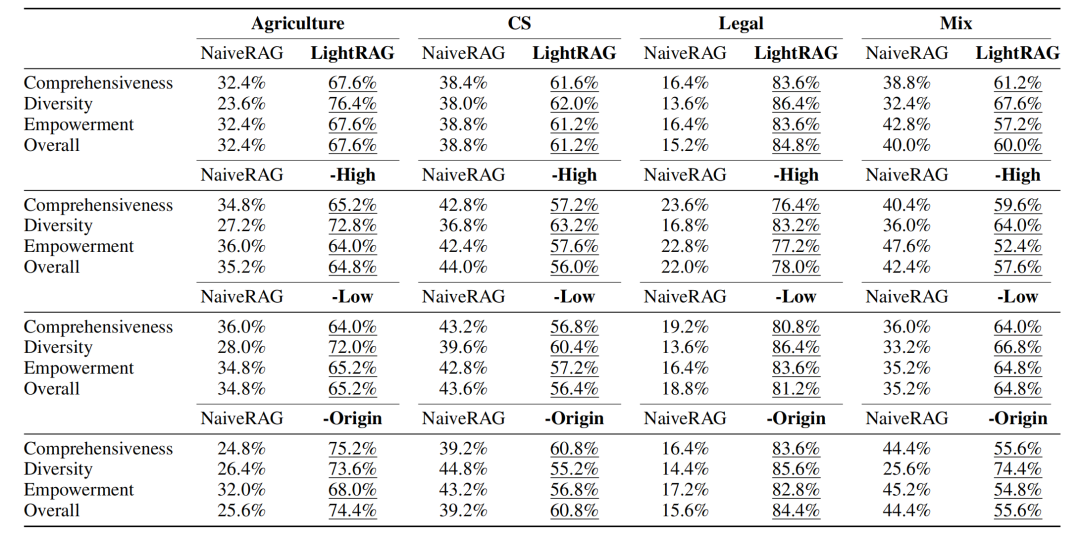
仅使用低级别检索时,模型性能显著下降。由于过分关注特定实体及其直接关联,模型无法获取更广泛的主题信息,在多个数据集和评估指标上表现不佳。 仅使用高级别检索时,模型在获取广泛信息方面有所提升,但在细节处理上有所不足。虽然能够捕获更广泛的主题知识,但缺乏对具体实体细节的深入理解,导致在考察特定细节的指标上表现欠佳。 移除原始文本内容后,模型性能未出现显著下降,某些数据集上甚至有所提升。这表明语义图在检索过程中能够有效提取和表示关键信息,即使没有原始文本的支持,模型仍然能够提供准确的检索结果。
模型开销
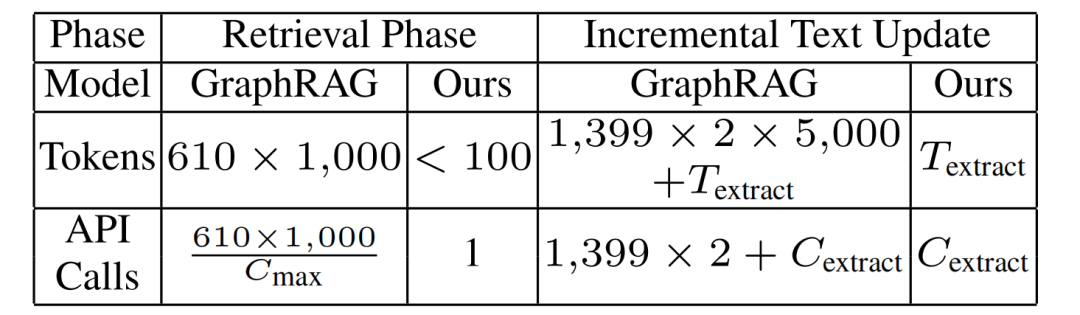
在检索阶段,GraphRAG 需要生成大量社区,并逐一遍历进行检索,导致了高昂的 token 消耗和频繁的API调用,效率较低。相比之下,LightRAG 采用了高效的检索机制,通过整合图结构和向量表示,只需少量 token 即可完成关键词生成和检索,且整个过程仅需一次 API 调用,显著降低了资源消耗和调用频率。
在增量数据更新方面,GraphRAG 由于其社区结构的限制,在引入新数据时不得不拆除并重新生成整个社区结构,耗费大量 token 和时间,成本极高。而 LightRAG 凭借其增量更新算法,能够将新数据无缝整合到现有的图结构中,避免了重复构建的开销,大大提高了更新效率。
04
论文结论
