




看到薛老师写的这篇文章《数据库中少数民族名字的存储》,还是很感触的,对于数据库乱码的场景曾经碰到很多,原因多种多样的,有时候很棘手,可以平时多积累些这种问题的处理方式,了解了原理,碰到不会慌。
薛老师文章中提到的乱码指的是维族名字中间的"•"。

输出结果如下,可以看出3条都是不一样的,而第二条直接是乱码,

这三条都是怎么来的?

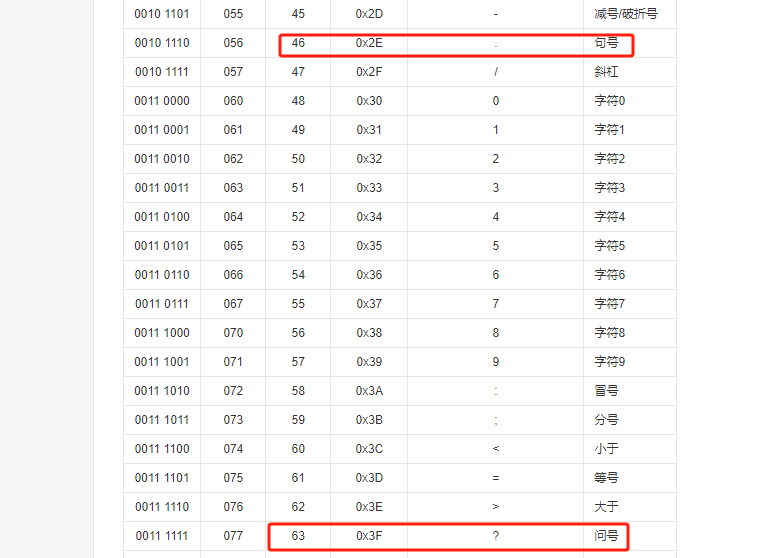
对照编码表可以看到46是句号,而63就是问号(因为无法识别,存储进来就有问题了),
怎么解决?
转换读
对于已知的乱码符号进行转换,

例如输入企业名称中带括号的,有的是 XX(中国),有的是XX(中国),为了在数据库中找得到,就需要将全角半角的都查,给整个字段套上函数,无论等号左边还是右边。但是,这可能就会导致用不到索引,全表扫描。
转换写
录入时候可以自由输入,但是写入时候要通过程序转换为统一的格式。例如点击保存,全部转换成统一的全角格式。例如,

而以上的问题在UTF8字符集中没出现,MySQL的数据库实验,
因此,一方面,需要考虑到数据库字符集,另一方面,控制好数据读写,前端校验好,就可以规避一些乱码的问题。

文章转载自bisal的个人杂货铺,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
