




单讲概念会有些枯燥,我们还是从实际场景出发,进行逐层分析深挖。
有个这样的业务场景,京东家电需要根据各品牌的当日累计销售额,来实时构建“销售额排行榜”。
如下图所示:
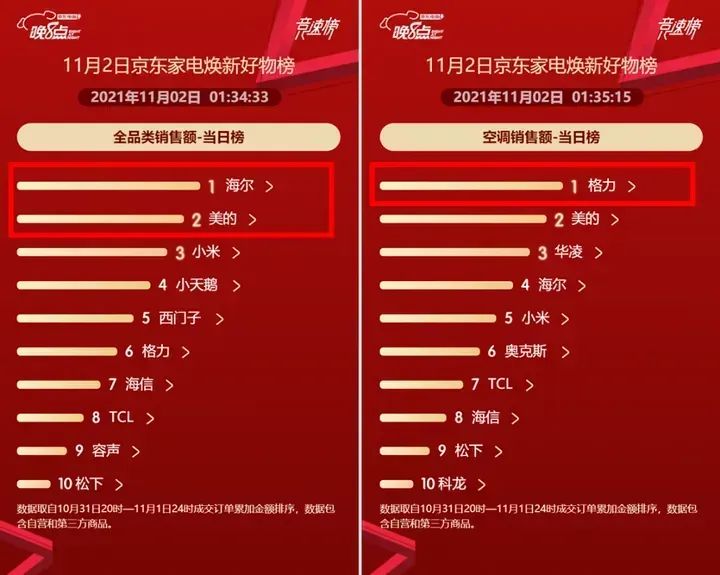
从技术实现的角度,最简单、且实时性高的方式,当然是一条SQL搞定一切,根据品牌进行分组,然后按照销售额进行降序排序就好了。
SQL如下:
SELECTbrand_id ,sum(amount) AS total_amountFROMea_orderWHERE`status` = 1AND create_time > '2023-12-06' 当天GROUP BYbrand_idORDER BYtotal_amount DESC;
但有一点,这种大电商平台一旦搞促销的话,家电品类的单日订单量达到几百万是很轻松的。这种情况下,不但SQL执行时间很长,并且对数据库资源的消耗也很大。
另外就是,如果产品经理加了新需求,还要要统计当月订单量的排行榜,那就直接GG了。
因此,我们需要寻求新的解决方案,该方案需要同时满足高实时性、高性能、海量数据三个要求,缺一不可。这时候,就混到Redis ZSet粉墨登场了。
何为Set?
Set是一个无序的天然去重的集合,即:Key-Set。此外还提供了交集、并集等一系列直接操作集合的方法,对于求共同好友(粉丝)、共同爱好之类的业务场景,实现特别方便。
如下图所示:
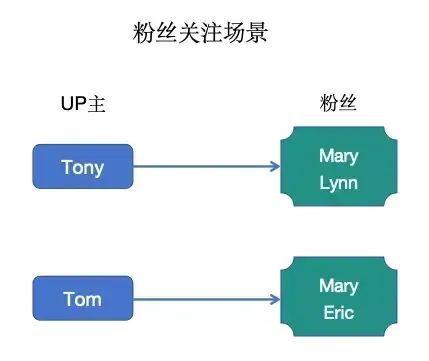
对应操作如下:
//好友关注场景redis> SADD Tony Mary //Mary关注了Tony(integer) 1redis> SADD Tony Lynn //Lynn关注了Tony(integer) 1redis> SMEMBERS Tony //Tony的粉丝列表1) "Mary"2) "Lynn"redis> SADD Tom Mary //Mary关注了Tom(integer) 1redis> SADD Tom Eric //Eric关注了Tom(integer) 1redis> SMEMBERS Tom //Tom的粉丝列表1) "Mary"2) "Eric"redis> SINTER Tony Tom //Tony和Tom的共同粉丝1) "Mary"redis> SUNION Tony Tom //Tony和Tom两个人的所有粉丝1) "Mary"2) "Lynn"3) "Eric"redis> SDIFF Tony Tom //关注了Tony,但没有关注Tom的人1) "Lynn"redis> SDIFF Tom Tony //关注了Tom,但没有关注Tony的人1) "Eric"
说下Set和List数据结构的区别:
List中可以存储重复元素,而Set中只能存储非重复元素。
List中存储的元素是有先后顺序的,而Set中存储的元素则是无序的。
何为ZSet?
Zset(SortedSet),是Set的可排序版,是通过增加一个排序属性score来实现的,适用于排行榜和时间线之类的业务场景。
如下图所示,这里的score属性对应的是销售额:
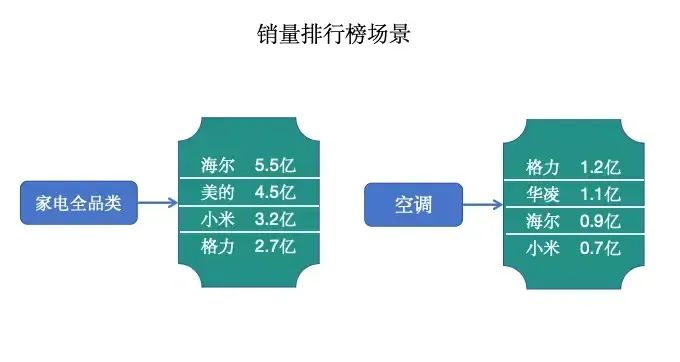
对应操作如下:
//销量排行榜场景redis> ZADD 家电全品类 5.5 海尔 //添加了海尔电器和5.5亿销售额(integer) 1redis> ZADD 家电全品类 4.5 美的 //添加了美的电器和4.5亿销售额(integer) 1redis> ZADD 家电全品类 3.2 小米 //添加了小米电器和3.2亿销售额(integer) 1redis> ZADD 家电全品类 2.7 格力 //添加了格力电器和2.7亿销售额(integer) 1redis> ZCARD 家电全品类 //家电全品类的数量(integer) 4redis> ZSCORE 家电全品类 格力 //获取格力的销售额"2.7"redis> ZREVRANGE 家电全品类 0 -1 WITHSCORES //家电全品类的倒序输出1) "海尔"2) "5.5"3) "美的"4) "4.5"5) "小米"6) "3.2"7) "格力"8) "2.7"redis> ZRANGE 家电全品类 0 -1 WITHSCORES //家电全品类的正序输出1) "格力"2) "2.7"3) "小米"4) "3.2"5) "美的"6) "4.5"7) "海尔"8) "5.5"redis> ZINCRBY 家电全品类 2.2 格力 //为格力增加2.2亿销售额"4.9"redis> ZREVRANGE 家电全品类 0 -1 WITHSCORES //增加销售额后的排行榜变化1) "海尔"2) "5.5"3) "格力"4) "4.9"5) "美的"6) "4.5"7) "小米"8) "3.2"
ZSet具备非常好的性能和并发度,以下为Redis性能白皮书上的指标:
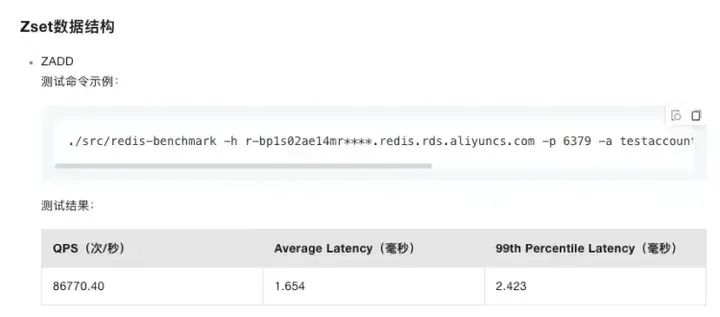
虽然上面只有ZADD的测试数据,但ZINCRBY和ZREVRANGE(限制读取范围)也不会差,肯定都是同一个数据量级的。
注意点:在Redis Cluster模式下,需要对ZREVRANGE的读取范围进行限制,避免大热Key的出现。
Redis ZSet在排行榜场景中,具备高性能的原因有二:
用空间换时间的思想。
优秀的底层实现。
ZSet底层实现
我们以Redis 7 为例,ZSet的底层实现还是比较复杂的,用了三种数据结构来进行实现,分别是skiplist(跳表)、dict(哈希表)和listpack实现的。
其具体判断规则如下:
当ZSet元素个数小于128(zset_max_listpack_entries的默认值),并且元素值小于64字节(zset_max_listpack_value的默认值)的时候,使用listpack作为底层结构,以节省空间,否则使用skiplist + dict作为底层结构,以提升效率。
下面我们就来分别介绍一下。
listpack
listpack可以看做是ziplist的优化版本,ziplist的整体结构如下:
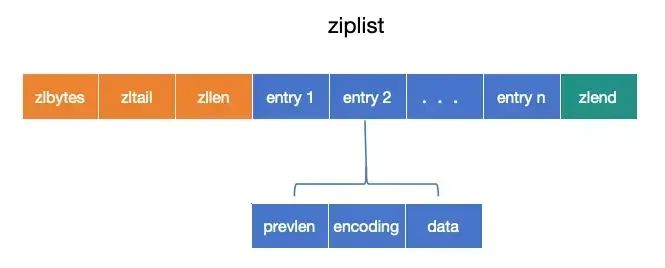
ziplist包含如下字段:
zlbytes,4个字节,记录ziplist所占的空间。
zltail,4个字节,记录ziplist尾部的偏移量。
zllen,2个字节,记录ziplist中存储的entry数量。
entry,ziplist中的具体数据项,不定长。
zlend,1个字节,用来标记ziplist的结束点,固定值为255。
其中,entry又包括三个字段:prevlen,记录前一个entry的长度,便于从后往前遍历。如果prelen的值小于254,用1个字节来保存,大于等于254,则用5个字节。
encoding,1、2或5个字节,记录当前节点的类型(字符串或整数)和长度。
data,实际存储的数据,不定长。
优点:
数据结构紧凑,内存空间连续,节省内存开销且可以利用CPU缓存。
缺点:
若保存元素过多,会导致查询效率降低,适用于少量元素,且元素占用空间不大的场景。
可能会引发级联更新问题。
级联更新问题:
如上文所说,entry中的prelen值,如果小于254,用1个字节来保存,大于等于254,则用5个字节。
如果ziplist更新entry1,恰好entry1从小于254字节,变成了大于等于254字节,那么entry2节点的prelen属性,就会从1个字节变成5个字节。
恰好entry2由于上述原因,也从小于254字节,变成了大于等于254字节,那么entry3节点的prelen属性,就会从1个字节变成5个字节,以此类推。
而listpack的出现,正是为了解决级联更新的问题,listpack的整体结构如下:
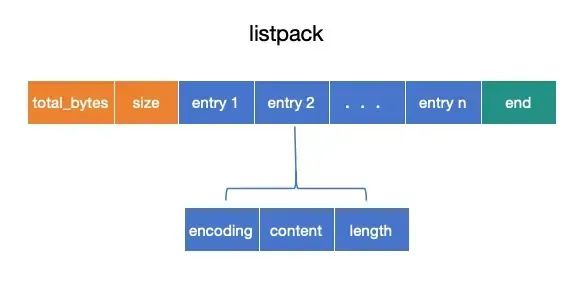
我们可以看下,listpack和ziplist的整体结构大同小异,也是通过total_bytes字段记录listpack所占的空间,size字段记录entry数量,最后也有个结束点标记,只是少了ztail_offset字段。
而entry中,多了length字段,来记录encoding + content的总长度,重点是少了prevlen字段,从而避免了ziplist中的级联更新问题。
skiplist + dict
ZSet数据量比较少的场景,它的增删改和多维度查询操作,无论怎么处理都不会慢。一旦数据量庞大起来,那就完全不一样了,ZSet是通过skiplist + dict的方式来实现的。
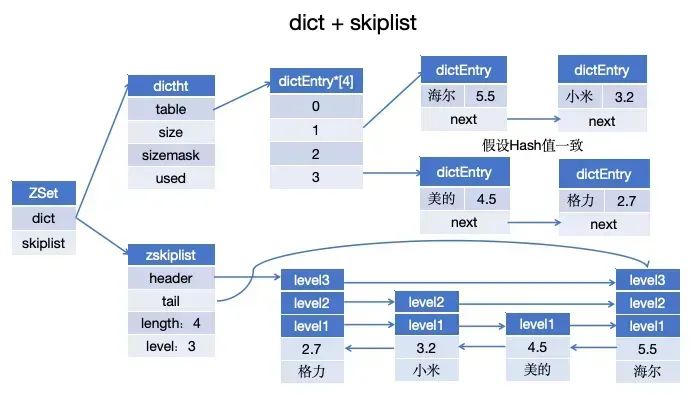
为什么同时选择skiplist + dict?
这是基于提升性能考虑的,这也是Redis设计的精妙之处。
只使用skiplist:根据成员查找分值操作(ZSCORE)的复杂度从 O(1) 上升为 O(logN)。
只使用dict:在执行范围查询操作(ZREVRANGE、ZRANGE)的时候,字典需要进行排序,至少需要O(NlogN) 的时间复杂度和 O(N) 的内存空间。
skiplist + dict各存一份完整数据?
不是这样的,skiplist Node中的 *obj 和 dict 中的 *key 会指向同一个具体 member(元素)的地址,这样可以节省内存。
结语
这期先讲这么多吧,很多更加深入的细节,我们留到以后再讲。
