




概述
在查询中会经常使用子查询,比如
Q1:
select s.name,e.course from students s,exams e
where s.id=e.sid and
e.grade=(
select min(e2.grade)
from exams e2
where s.id=e2.sid
)
从性能的角度来看,这个语句并不是很好,对于每个 student 和 exam pair,子查询都需要执行一次。
从技术的角度类看,这是一个dependent join,rhs的执行依赖于lhs。
所以需要解关联,一般会改写如下的样子:
Q1’:
select s.name,e.course
from students s,
exams e,
(select e2.sid as id, min(e2.grade) as best
from exams e2
group by e2.sid) m
where s.id=e.sid and m.id=s.id and e.grade=m.best
但是并不是所有的查询都可以通过标准的解关联技术来解关联,比如如下
Q2:
select s.name, e.course from students s, exams e
where s.id=e.sid
and (s.major = ’CS’ or s.major = ’Games Eng’)
and e.grade>=(
select avg(e2.grade)+1
from exams e2
where s.id=e2.sid or (e2.curriculum=s.major and s.year>e2.date))
标准的解关联技术都是依赖于 rhs 使用的字段可以在 lhs 获取,上面这个语句 s.year不能从 lhs 获取。
前置概念
主要是常见的关系代数
-
innter join 也可以表示为 cross join 外面添加where 条件

-
依赖 join
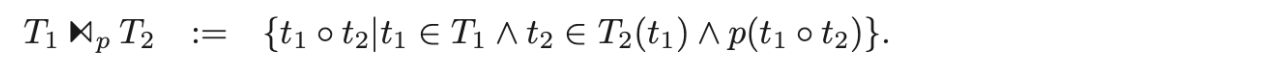
-
聚合 aggregate
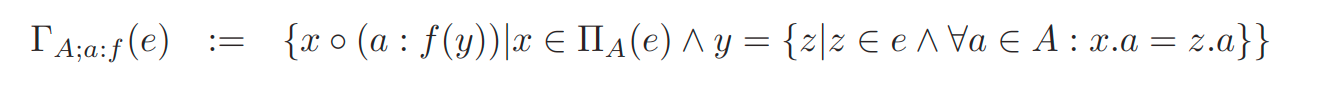
-
map 操作符

解关联
简单解关联
select ...
from lineitem l1 ...
where exists
(select *
from lineitem l2
where l2.l_orderkey = l1.l_orderkey)
关系代数如下
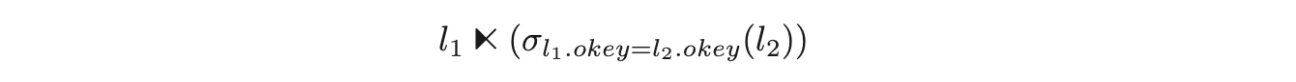
可以直接简化成 semi join
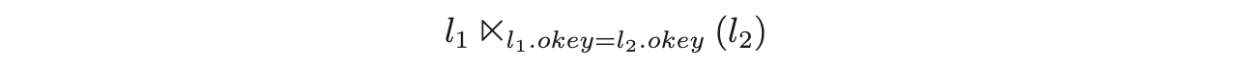
通用解关联
主要有两步
- 将 dependent join 转换成一个 nicer 的 dependent join。
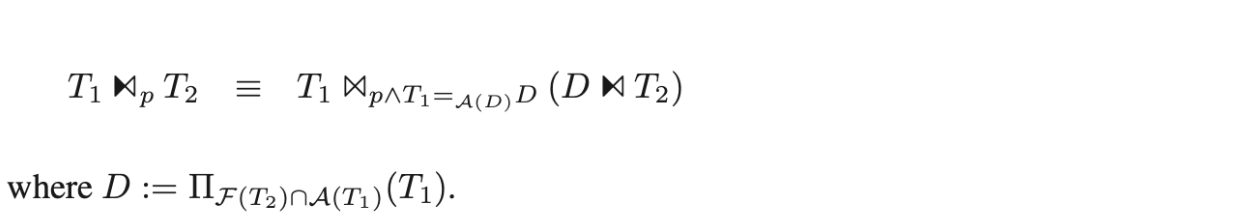
其中 D 包含了 T1 的属性以及 T2 依赖 T1 的属性,是 duplicate free,是去重的,不包含重复值,如果重复值很多,解关联后收益就很大。 - 将这个新的 dependent join 尽可能下推,直到将它变成一个 regular join。
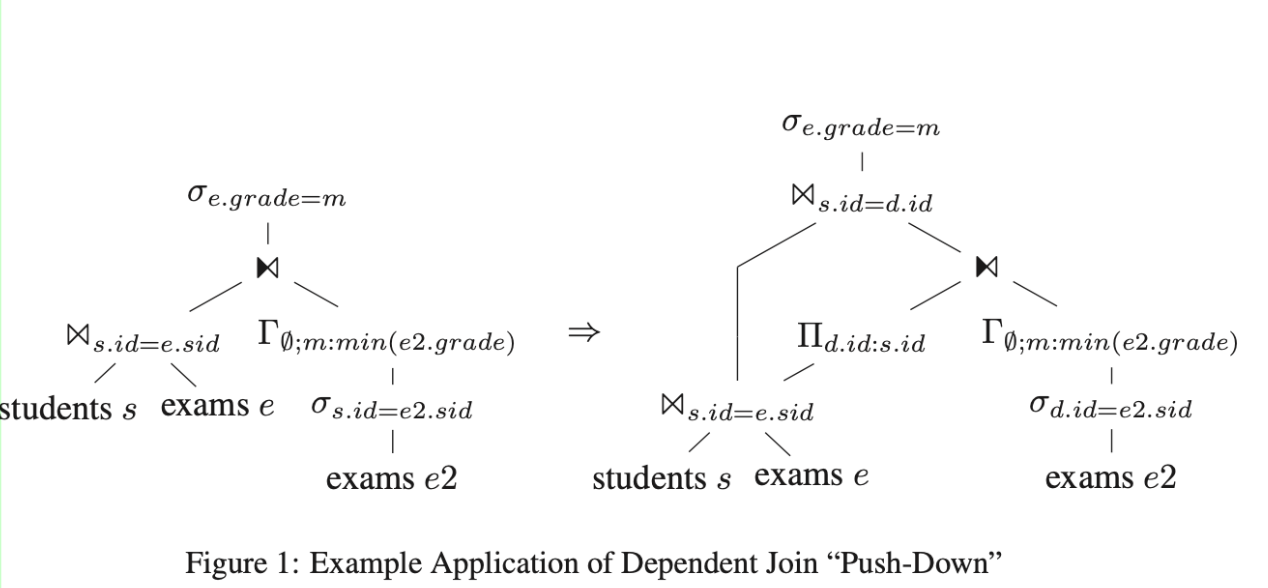
将 generic dependent join 转换成一个依赖于 set 的 dependent join。
目标就是将 dependent join 下推,指导如下所示,直到 rhs 使用的属性不再依赖 D。
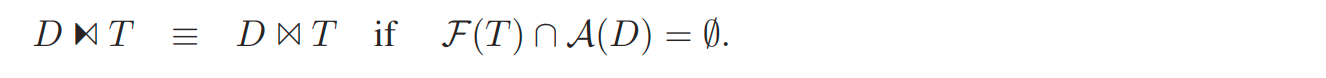
针对不同算子,dependent join 下推的等价关系代数如下
where

inner join
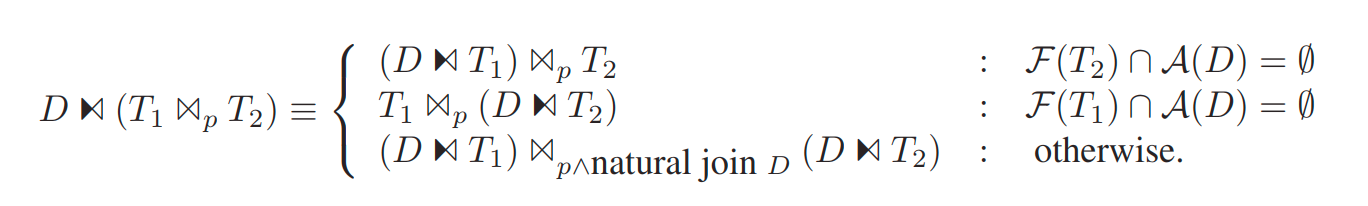
outer join
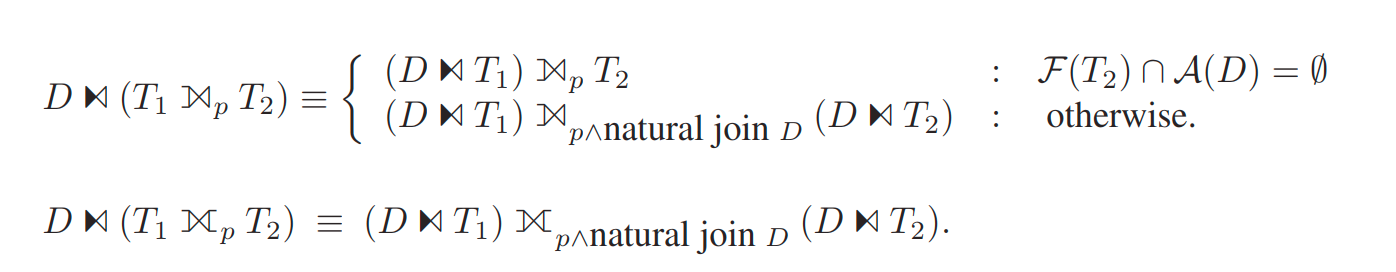
semi join
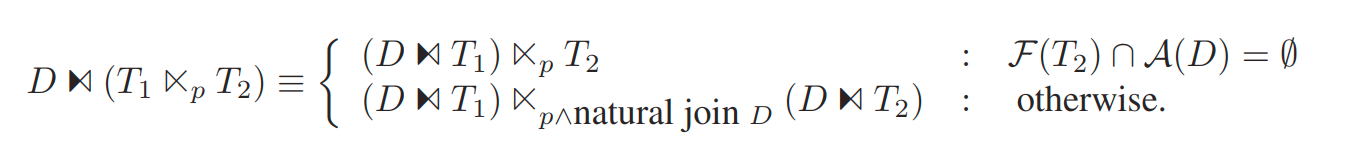
anti join
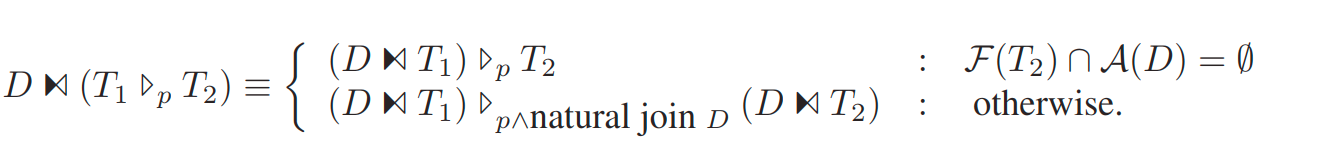
group by
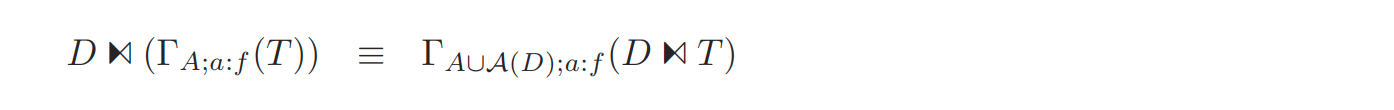
可以看到 D 中的属性变成了 group by 后的字段。
project

set
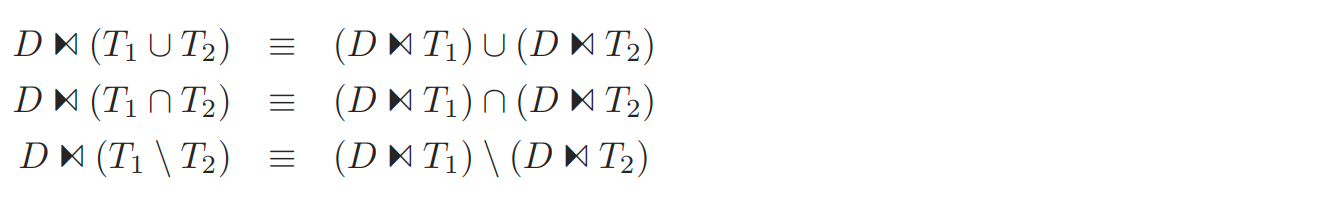
经过上面关系代数的等价变化,dependent join 会下推到 relation上 或者被消除。
优化举例
Q1
初始查询的关系代数
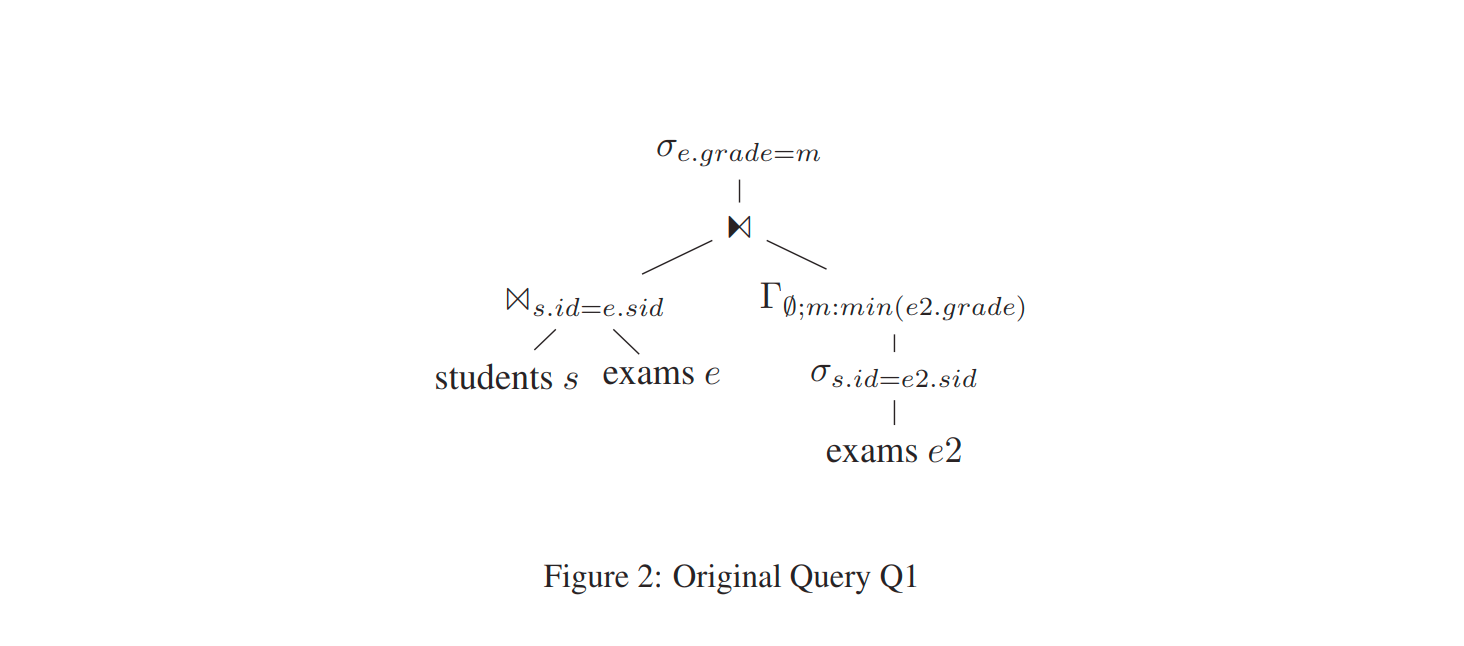
dependent join 下推到join下面
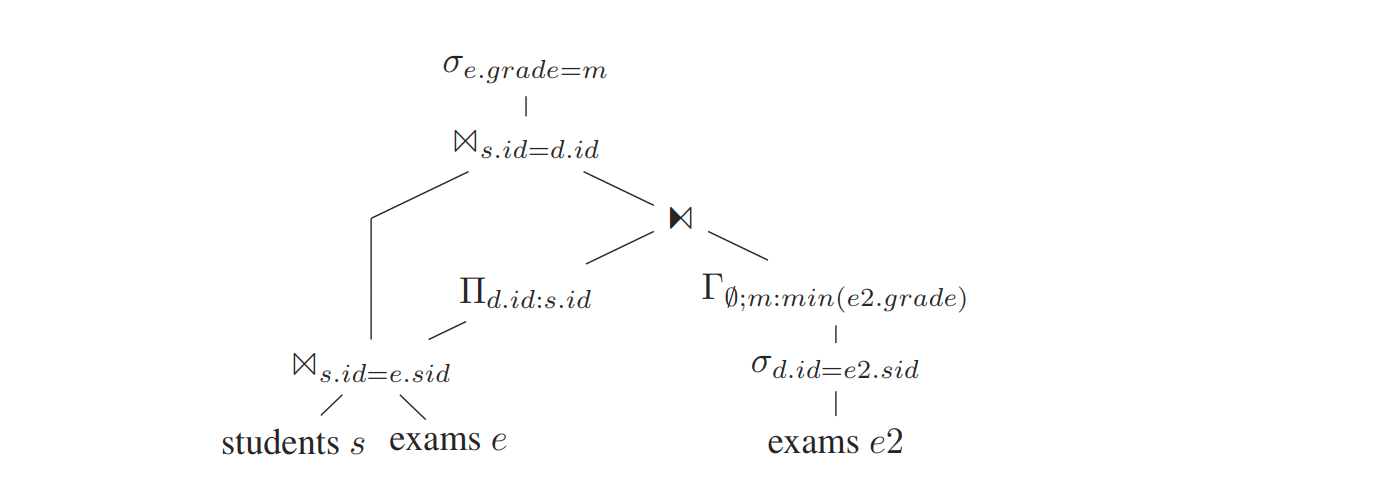
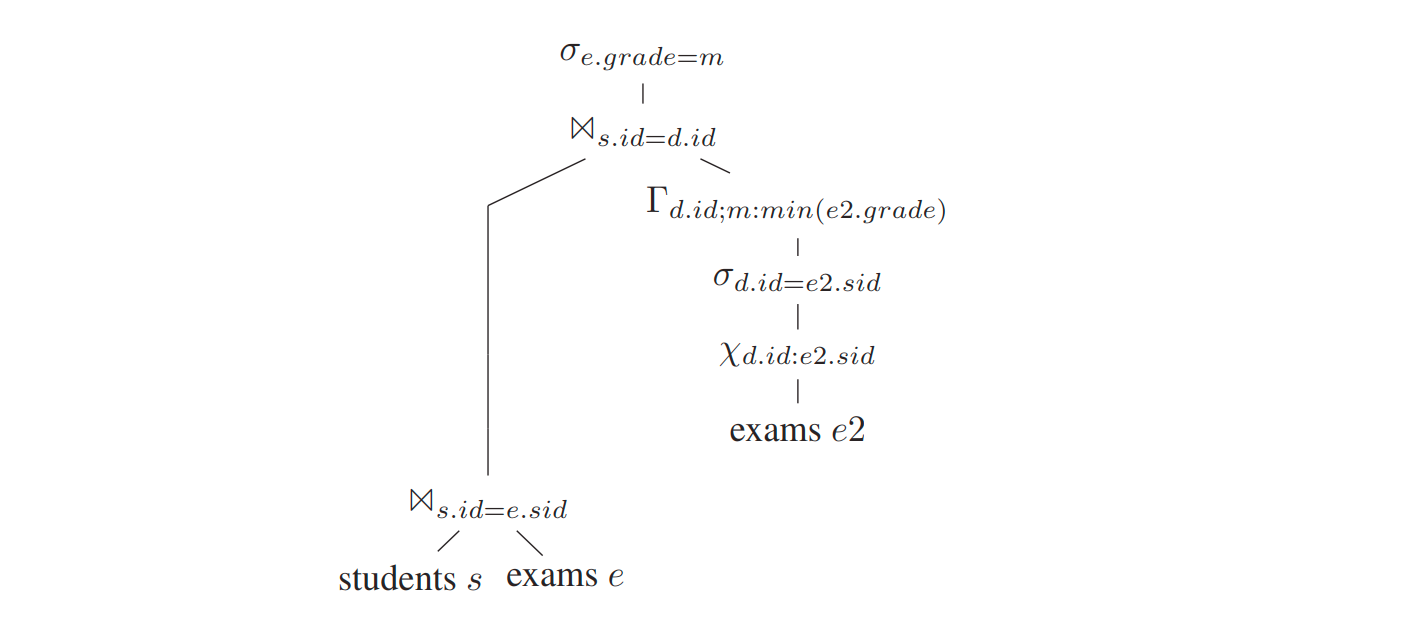
dependent join 下推到 aggregate 下面
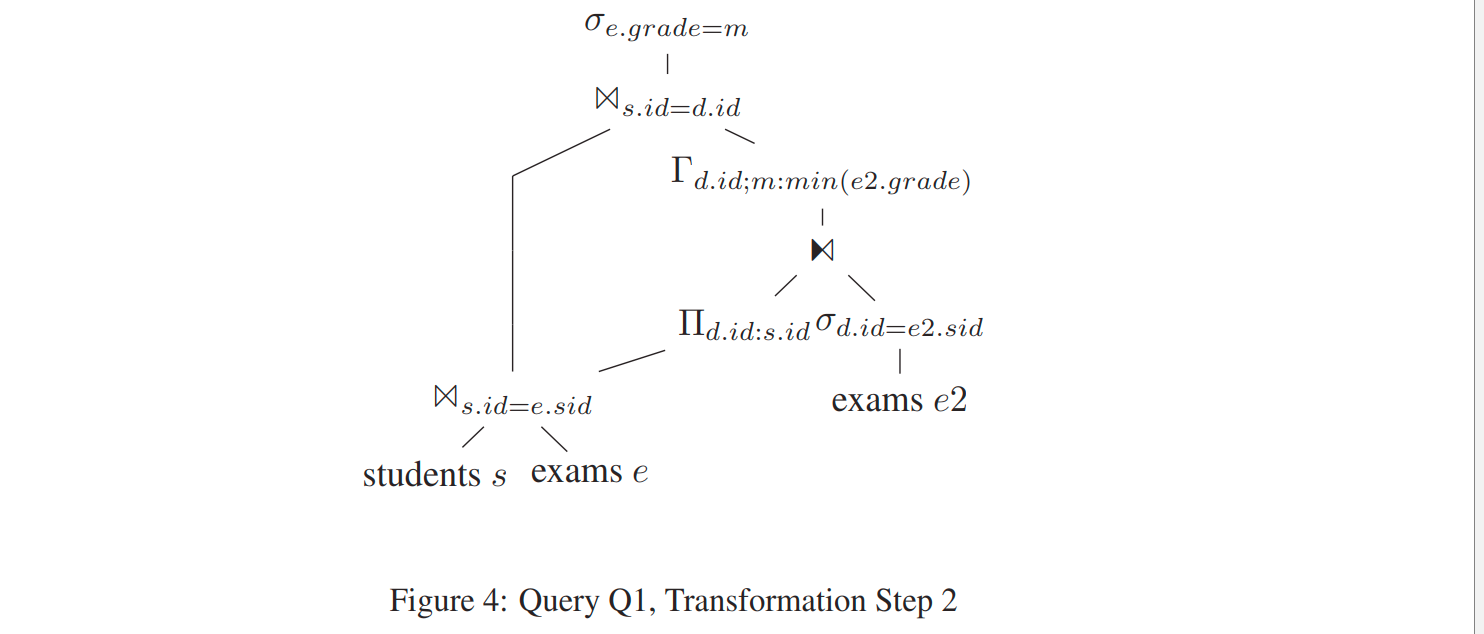
dependent join 下推到 where 下面
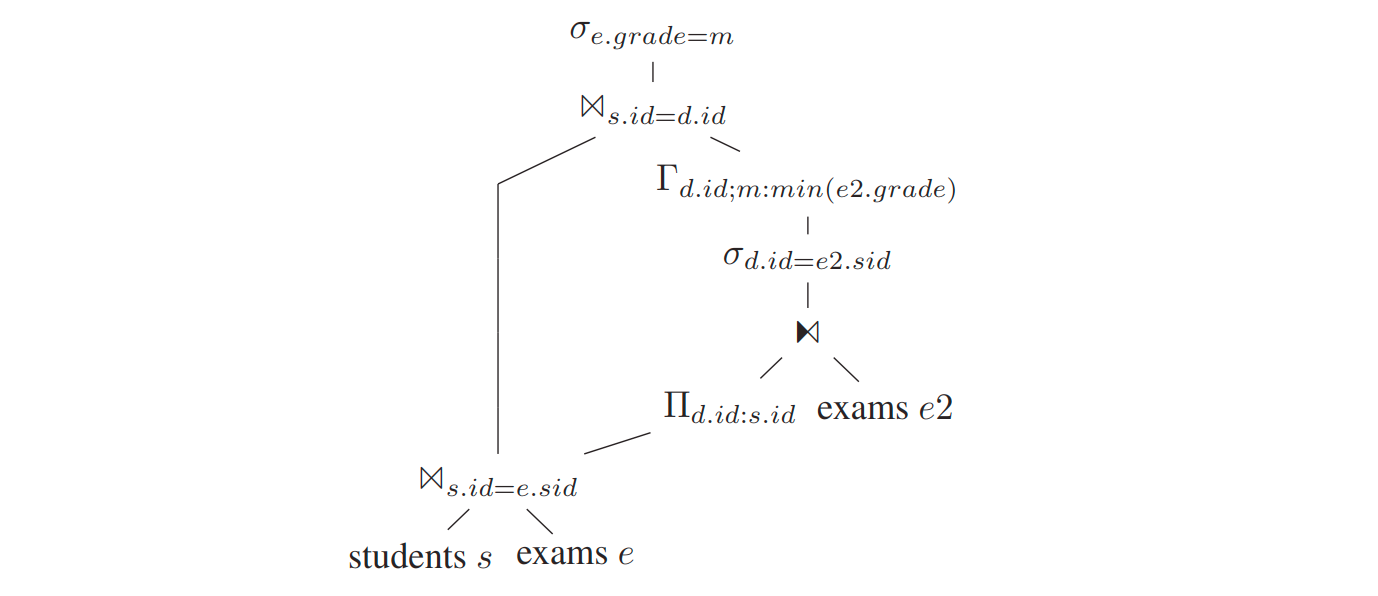
依赖的s.id 可以从 D 中获取,解关联成功
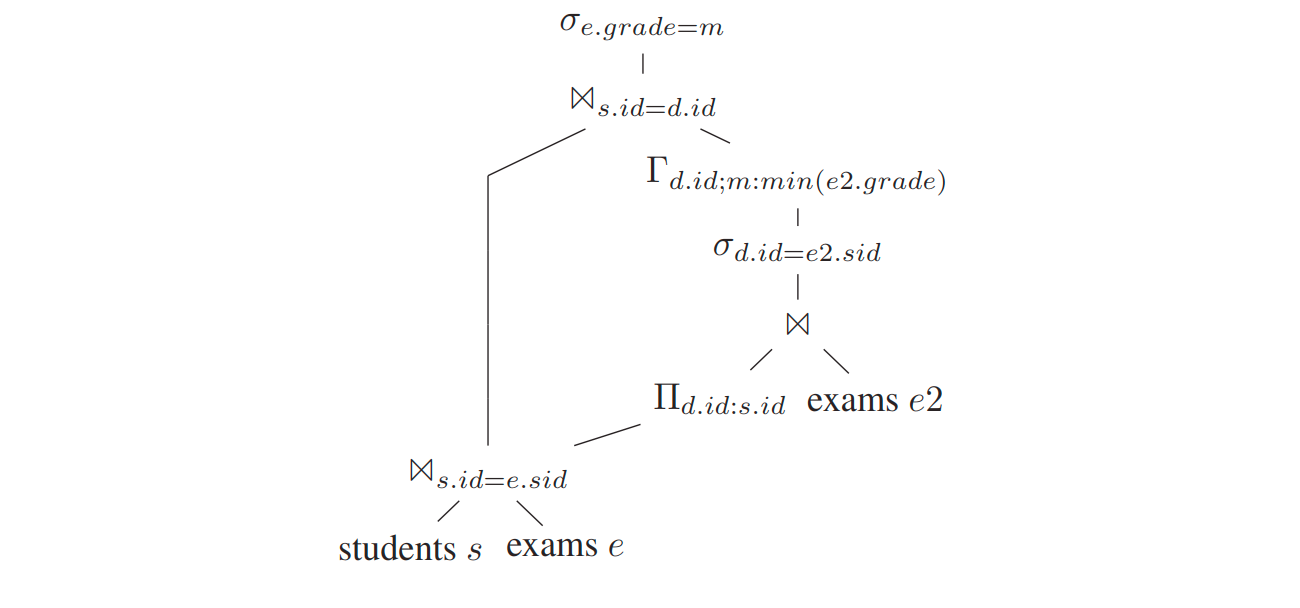
将上提的 where 下推
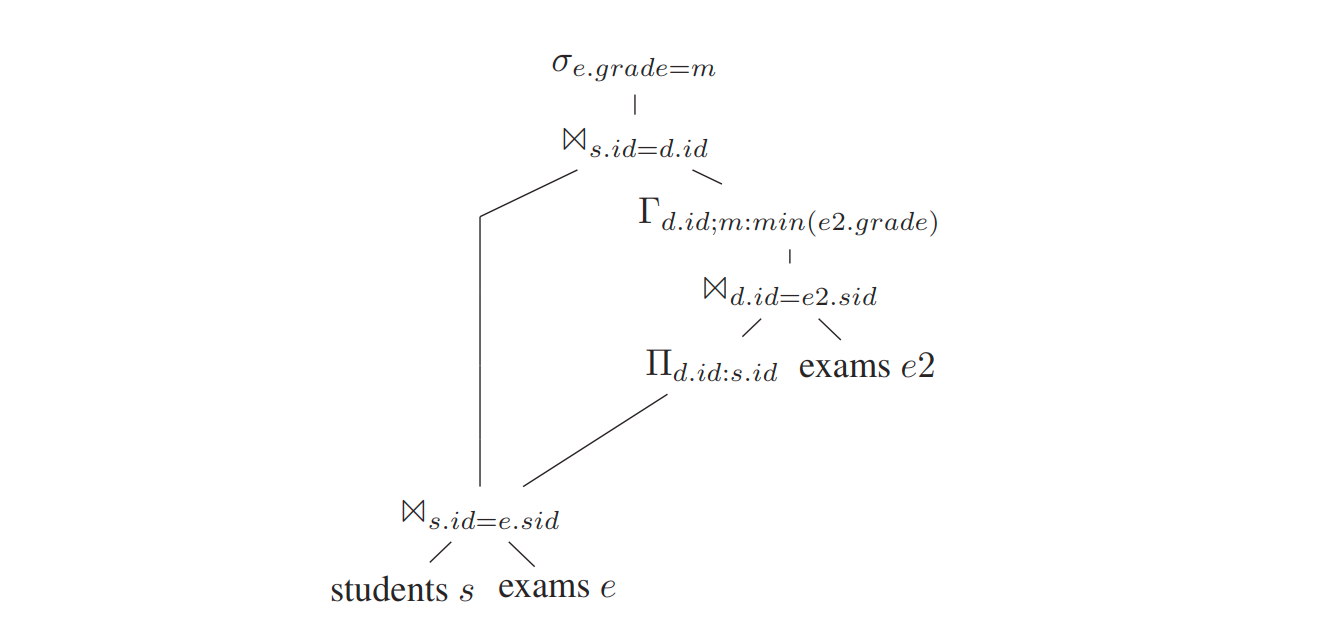
因为e2.sid等价于s.id, 所以消除rhs 使用的 d.id
Q2
对于文章最开始提到的 Q2 优化后的关系代数如下
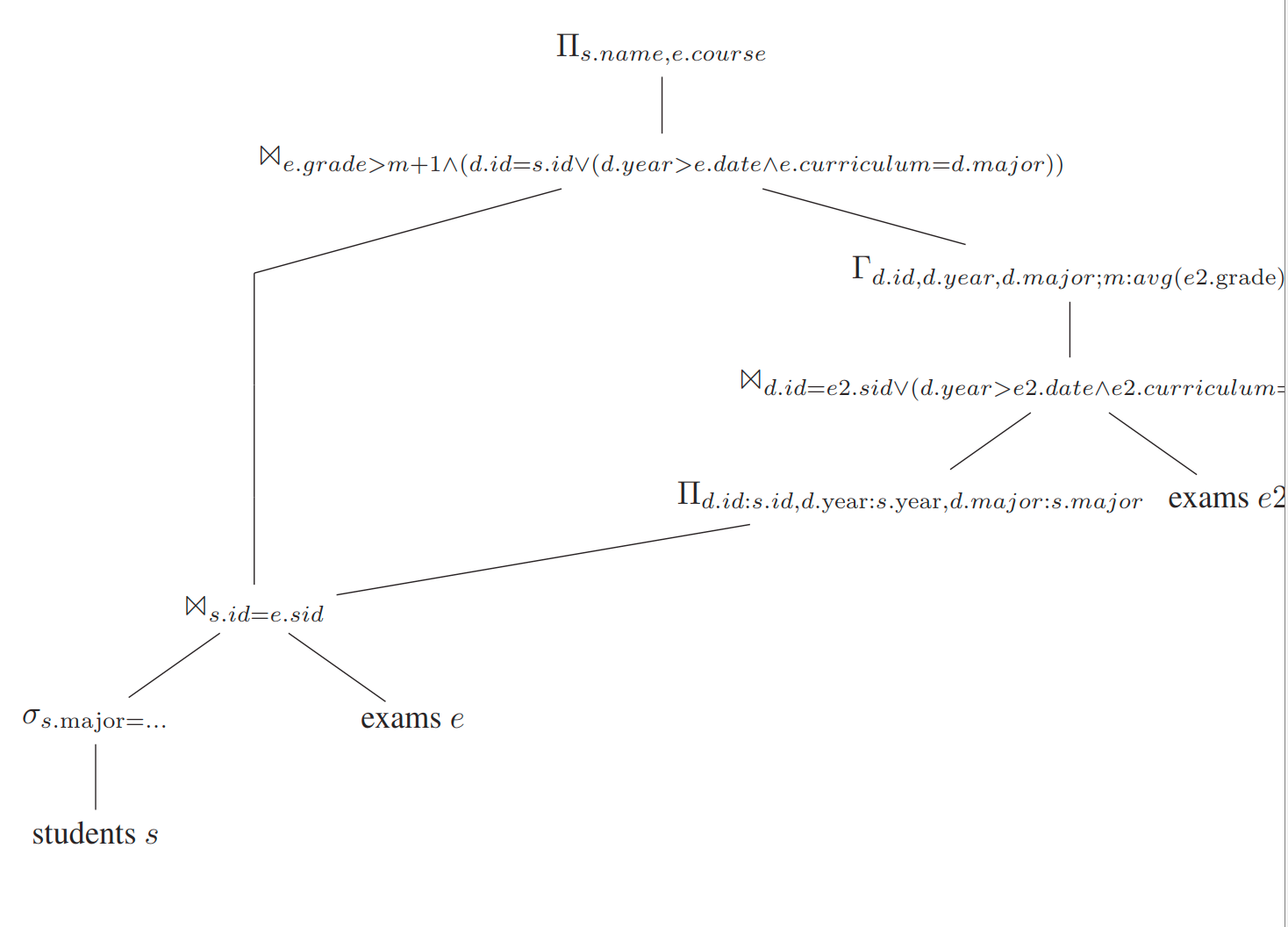
Q3
Q3:
select R.*
from R
where R.X = all (select S.Y
from S
where S.B = R.A)
对于 Q3 这个查询,可以用 dependet anti join 来表示, 尝试将 depedent join 下推
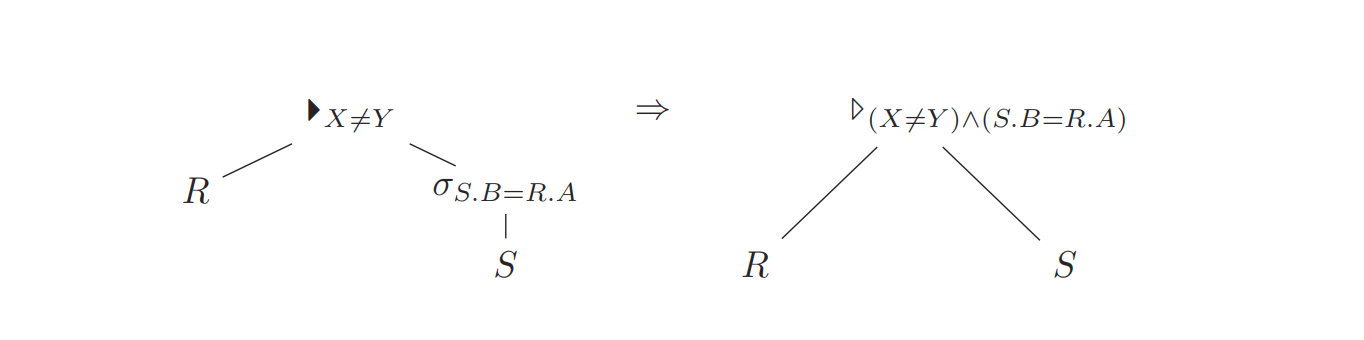
DuckDB实现和代码位置
核心代码
DuckDB 的解关联的代码在 bind 阶段,核心类如下
duckdb-main/src/planner/binder/query_node/plan_subquery.cpp
优化举例
用 TPC-H 的数据集来举例,查询如下
select
l_linestatus,
ps_suppkey
from
lineitem,
partsupp
where
ps_partkey = l_partkey
and l_shipdate = '1992-01-07'
and ps_supplycost = (
select
min(ps_supplycost)
from
partsupp
where
ps_partkey = l_partkey
);
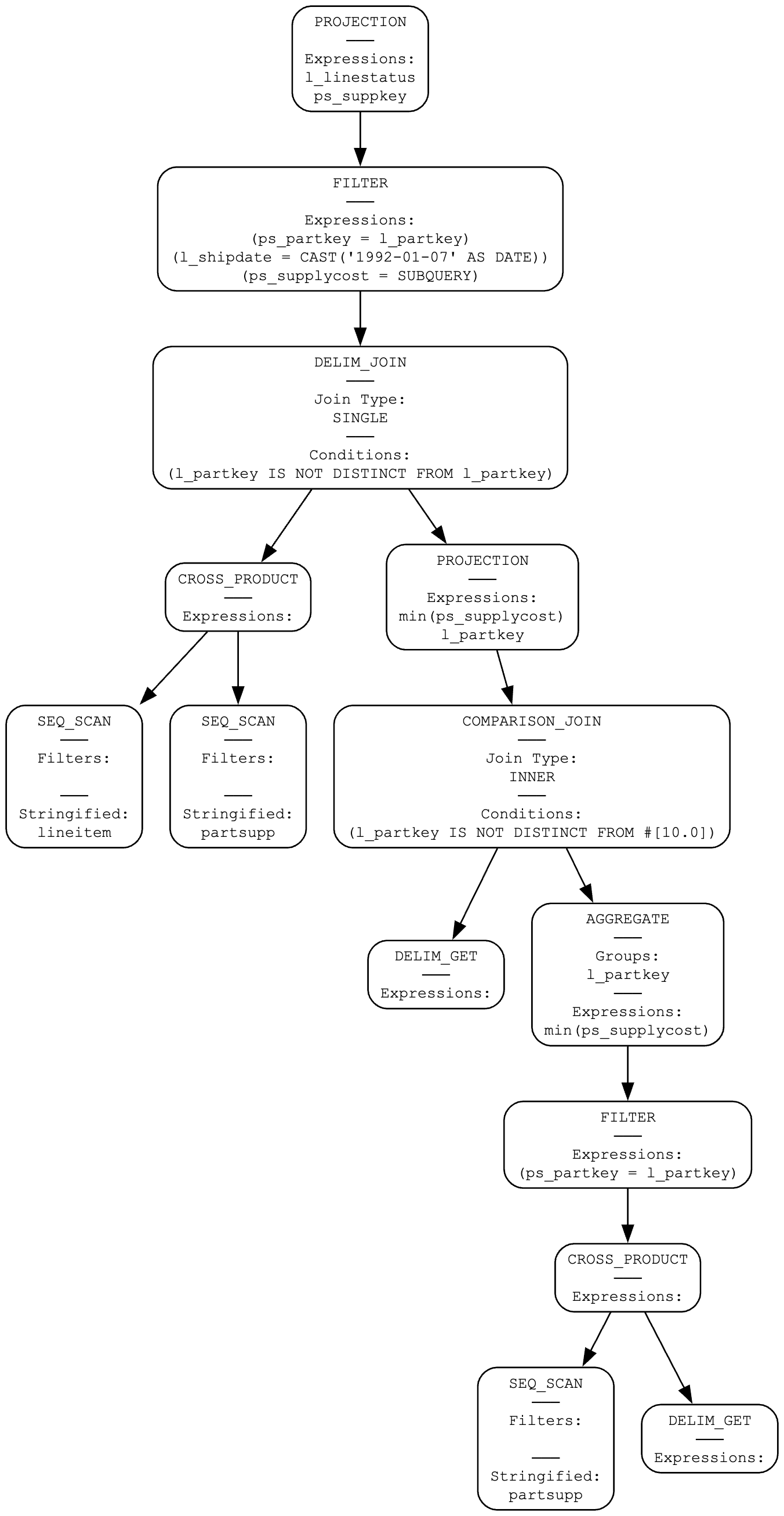
解关联后的 plan 如下
可以看到已经没有 dependent join了, DELIM_GET 就是对应着论文里的 D,这个 plan 还要经过后续的基于规则做进一步优化
将 cross product 转化成对应的 join 实现。
结论
通过关系代数变化,理论上可以支持所有类型的关联子查询。将算法时间复杂度从 O(n2) 降到 O(n)。
