




今天分享的是北航、上海人工智能实验室发布的一篇论文:
VideoEspresso: A Large-Scale Chain-of-Thought Dataset for Fine-Grained Video Reasoning Via Core Frame Selection。
VideoEspresso: 通过核心帧选择进行细粒度视频推理的大规模思维链数据集


01
摘要
02
数据集
02
数据集
1. 视频数据收集
数据来源:从多种公开数据集中提取视频,包括新闻、电影、纪录片、动画、教育内容等,确保数据的语义丰富性。 视频类型:涵盖动态场景和静态场景,确保多样性和复杂性。
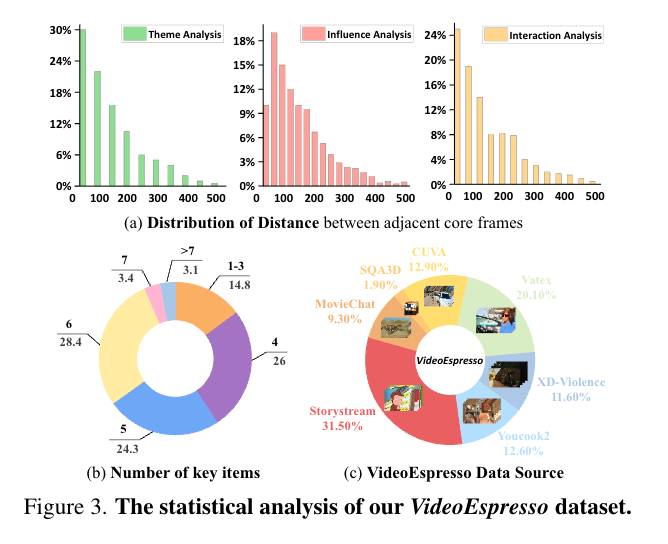
2. 冗余去除
目标:通过去除冗余帧,保留关键帧内容。 实现方法: 采样策略:动态场景采用更高帧率(FPS),静态场景采用较低帧率。 语义过滤:利用 InternVL2-8B 模型生成帧描述,并通过 BGE-M3 模型进行细粒度语义筛选,去除相似帧。 分组处理:将相邻帧的描述分组,保留帧间的时间连贯性。
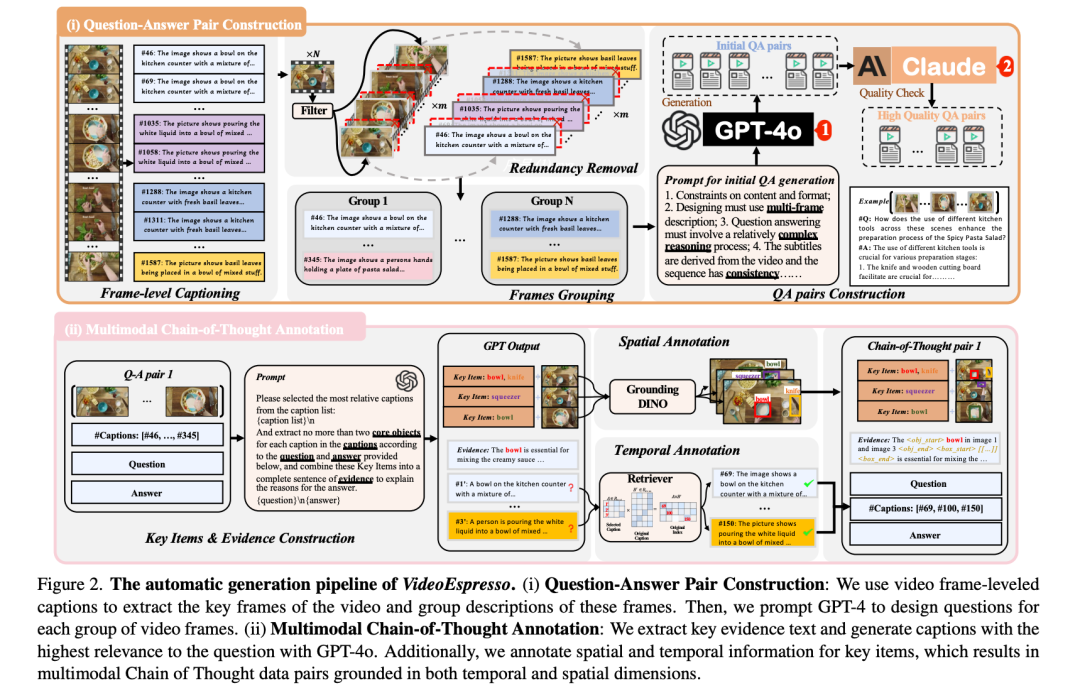
3. 高质量 QA 对构建
目标:通过 GPT-4o 生成基于多帧描述的复杂推理 QA 对。 实现方法: 提示设计:设计精确的提示,引导 GPT-4o 生成具有深度推理能力的问答对。 质量验证:利用辅助 LLM 验证 QA 对的质量,包括事实准确性、去除幻觉和开放性问题。
4. 多模态 CoT 注释
目标:引入视频CoT注释,细化推理步骤。 实现方法: 使用 GPT-4o 提取文本证据,识别关键对象。 利用 GroundingDINO 标注关键帧中的目标位置,并通过 CLIP-ViT-B/32 验证标注一致性。 使用 BGE-M3 模型检索原始注释的时间信息,确保时空标注精准。
03
关键技术
03
关键技术
多模态 CoT 注释通过整合文本、空间和时间信息,形成细粒度的推理链条。包含:
文本证据:从视频注释中提取关键信息,如“角色A在厨房里操作咖啡机”。 空间标注:标记“角色A”和“咖啡机”在图像中的位置。 时间定位:通过计算语义相似度,确定事件发生的具体时间点。
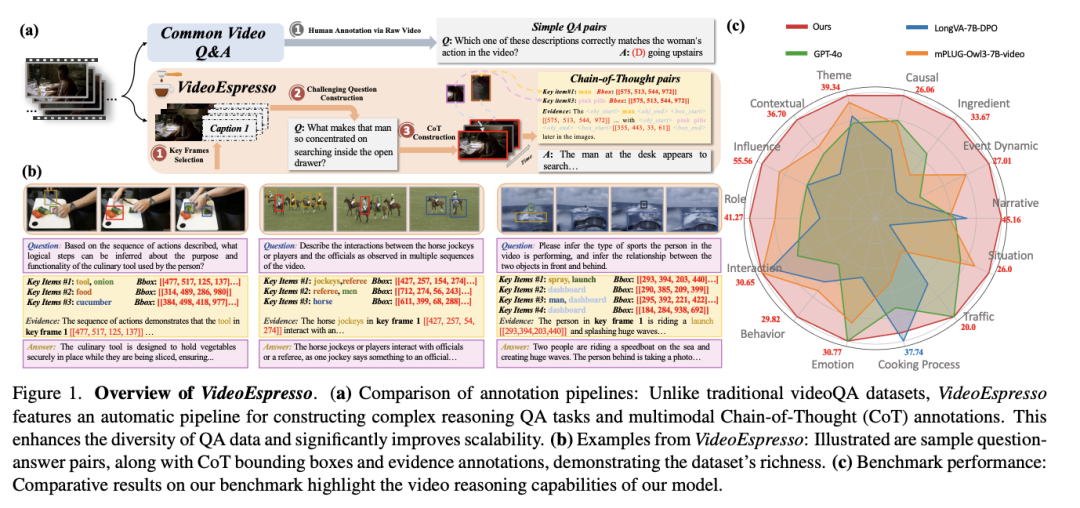
最终,这些多模态证据被用作推理的中间步骤,帮助模型更高效地回答问题。
04
推理框架
1. 轻量级选择器
功能:从输入视频中提取与问题相关的关键帧,减少计算量。 工作流程: 使用轻量级 LVLM 转换帧描述为语言描述。 通过 LLM 选择最相关的帧描述及其对应帧。
2. 细粒度推理模型
功能:利用核心帧及多模态证据进行推理,生成最终答案。 训练方法: 证据生成阶段:引导模型生成与问题相关的多模态证据。 答案生成阶段:根据证据生成准确答案。 优势: 提高推理效率:通过核心帧选择减少无关信息输入。 增强答案准确性:结合多模态证据优化推理质量。 提供强解释性:两阶段结构使推理过程透明易理解。
05
总结
06
编者简介
李剑楠:华东师范大学硕士研究生,研究方向为向量检索。曾作为核心研发工程师参与向量数据库、RAG 等产品研发,代表公司参加 DTCC、WAIM 等会议进行主题分享。
文章转载自AI 搜索引擎,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
