




在 MySQL 中,COUNT()
是一个聚合函数,用于计算查询结果中符合条件的行数。它的执行方式与索引的使用、数据的扫描方式、查询的优化等因素密切相关。下面我会详细解释COUNT()
的执行过程,特别是COUNT(1)
、COUNT(id)
和COUNT(非主键列)
的执行原理,并给出具体的实例。
一:count是怎么执行的
server层发出查询请求: 当执行
SELECT COUNT(*) FROM table_name WHERE ...
查询时,server 层向 InnoDB 存储引擎请求要执行查询。InnoDB 查找符合条件的记录: InnoDB 存储引擎根据查询的条件,开始扫描二级索引(例如
idx_key1
),并找到符合条件的第一条二级索引记录。无需回表,直接统计: 由于
COUNT(*)
查询只关心记录数量,而不需要返回具体的列数据,InnoDB 不需要回表(即无需访问主键记录)。这意味着,它只需通过索引记录来计数,而无需从数据表中读取完整的行。server 层更新计数器: 每当 InnoDB 返回一条符合条件的索引记录时,server 层就将计数器(
count
变量) 增加 1。此时,*
被当作常量 0 来处理,因为COUNT(*)
只是对记录数进行统计,不需要关心具体的字段内容。继续扫描下一条记录: InnoDB 利用当前索引记录的
next_record
属性,找到并返回下一条符合条件的索引记录。重复计数: server 层继续收到 InnoDB 返回的索引记录,每次都增加计数器的值。
终止条件: 当 InnoDB 没有更多符合条件的记录时,返回一个“没有记录”的消息给 server 层,表示查询结束。
最终结果返回: server 层将累计的
count
值(即符合条件的记录数)发送给客户端,完成查询。
二:COUNT(1),COUNT(id),COUNT(非主键列)哪个更快?
1.COUNT(*)
的执行过程
首先,让我们看看COUNT(*)
的执行过程,这是最常用的一种方式。
- 作用
:计算满足查询条件的所有行数(包括 NULL 值和所有字段)。 - 执行方式
:MySQL 会扫描符合查询条件的所有行,并为每一行增加 1,最后返回总数。无论字段值是否为 NULL
,每一行都会被计数。
示例:
查询所有行数:

执行时,MySQL 会扫描表中的所有记录,并返回总数 3(即使age
为NULL
)。
2.COUNT(1)
的执行过程
- 作用
: COUNT(1)
计算查询结果中的行数,其中的1
只是一个常量。它不关心列的值,也不会受 NULL 值的影响。它的实际效果与COUNT(*)
是一样的,都是计算符合条件的行数。 - 执行方式
:MySQL 会通过索引或全表扫描扫描符合条件的行,计算所有行的数量。在执行过程中,MySQL 只关心是否存在行,而不是检查列的具体内容,因此效率与 COUNT(*)
基本相同。
示例:
这个查询与COUNT(*)
完全相同,MySQL 会扫描表中的所有记录并返回 3。
3.COUNT(id)
的执行过程
- 作用
: COUNT(id)
会计算列id
的非 NULL 值的行数。如果列id
包含 NULL 值,NULL 值的行将不被计数。 - 执行方式
:MySQL 会检查每一行的 id
列是否为 NULL。如果是 NULL,这一行不会被计数。如果不是 NULL,则这一行会被计数。由于id
是主键,通常不会有 NULL 值,因此COUNT(id)
和COUNT(*)
产生的结果是一样的。
示例: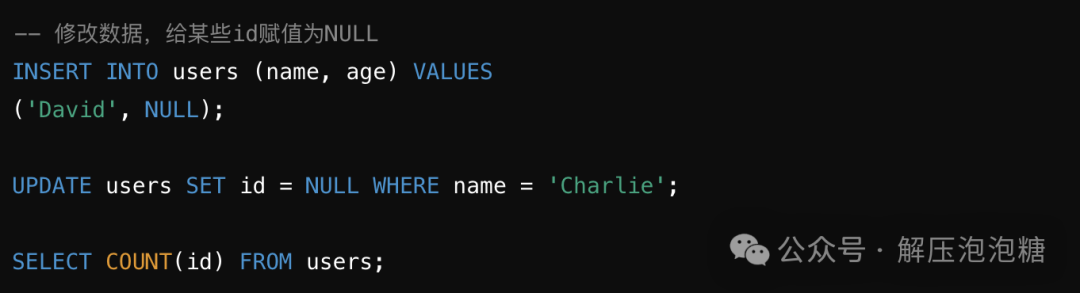
执行结果:

这里COUNT(id)
返回 2,因为只有 Alice 和 Bob 的id
列是非 NULL 的。Charlie 的id
被设置为 NULL,因此它没有被计数。
4.COUNT(非主键列)
的执行过程
- 作用
: COUNT(非主键列)
会计算指定列中非 NULL 值的行数。与COUNT(id)
类似,如果指定的列包含 NULL 值,那么这些行会被排除在计数之外。 - 执行方式
:MySQL 会扫描查询结果中的该列,统计非 NULL 的值。由于该列可能包含 NULL 值,因此它的计数结果通常小于等于总行数。
示例:
查询price
列中非 NULL 的数量:

执行结果:

只有 Product1 和 Product3 的price
列是非 NULL 的,而 Product2 的price
是 NULL,因此COUNT(price)
返回 2。
5. 为什么COUNT(1)
和COUNT(*)
的执行效果相同?
COUNT(1)
和COUNT(*)
都是为了统计符合查询条件的行数,并且它们的执行方式实际上是一样的。MySQL 优化器在执行这两个查询时,会忽略列的具体内容,直接计算行的数量。主要区别在于:
COUNT(*)会统计所有列的行数,包括值为 NULL 的列。 COUNT(1)计算的只是行数,使用常量 1 作为占位符。
在 MySQL 中,
COUNT(*)
和COUNT(1)
的查询计划和执行步骤是几乎相同的,都是通过扫描表中的所有行来进行计数,因此两者的性能差异几乎可以忽略不计。
6. 总结
COUNT(*):计算所有行数,效率较高,因为它不关心列的内容,直接统计行数。 COUNT(1):与 COUNT(*)
相同,统计符合条件的行数,但 MySQL 会忽略列的内容,只关心行是否存在。执行过程与COUNT(*)
基本一致。COUNT(id):统计 id
列非 NULL 的行数。由于主键列通常不会为 NULL,因此COUNT(id)
和COUNT(*)
的结果在主键列非 NULL 时相同,但如果主键列允许 NULL,结果可能会有所不同。COUNT(非主键列):统计指定列中非 NULL 值的行数。适用于需要统计某一列有效数据的情况。
理解COUNT()
的执行原理和差异,能够帮助我们在设计查询时做出更加高效的选择,特别是在使用索引时,了解不同列的 NULL 值情况对于优化查询性能至关重要。
