




fastdfs集群可以有很多个节点,每个节点都会存储一份数据文件,如果因为某个服务器问题需要关机,那么其上运行的fastdfs也会变得不可以用,此时如果不将其从集群中移除,会导致集群的其他节点出现问题,无法实现正常的文件上传与访问,下面演示如何从集群中删除一个节点以及会碰到的问题,本例子演示的三台fastdfs都是使用docker容器部署,并且trackerd和storaged都在一台机器上
环境准备:
| 名称 | IP | 系统 |
| fastdfs1 | 192.168.49.224 | centos7 |
| fastdfs2 | 192.168.49.83 | centos7 |
| fastdfs3 | 192.168.49.186 | centos7 |
首先查看集群状态是否都是ACTIVE,如图:
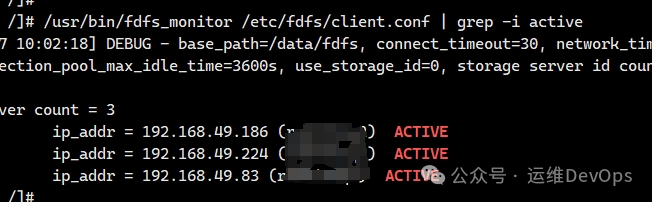
接下来演示将49.186节点从集群中剔除(包括storaged和trackerd)
1、首先查看49.186上fastdfs状态,如图:
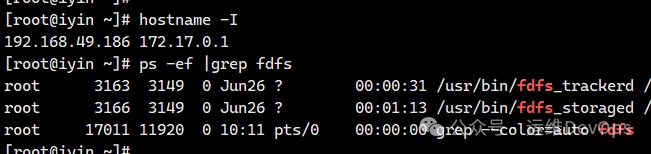
2、停止fdfs_storaged,可直接执行kill命令,如图:
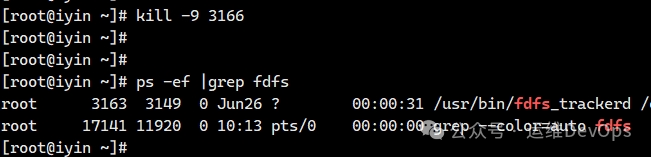
标准的停止命令是:/usr/bin/fdfs_storaged etc/fdfs/storage.conf stop
3、从集群中删除这个节点,命令如下,如图:
fdfs_monitor etc/fdfs/client.conf delete group1 192.168.49.186
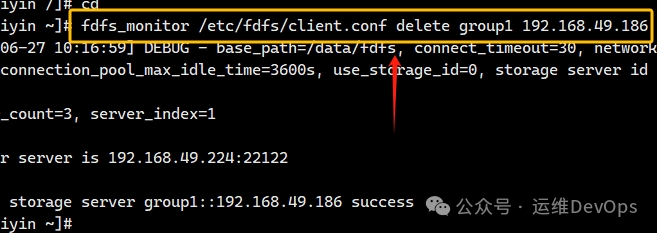
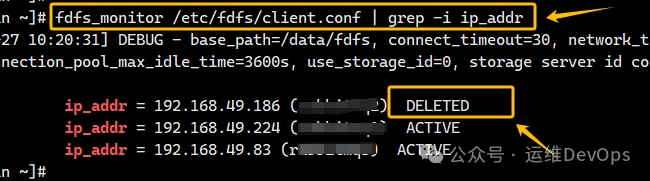
再次查看集群节点状态,已显示DELETE,如图:
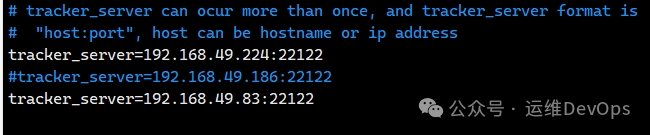
4、修改其余两个节点中关于49.186的tracker_server配置信息,主要涉及三个文件,client.conf、mod_fastdfs.conf、storage.conf,将其注释,如图:
停止49.186机器上的trackerd进程,然后重启其余两个节点的fastdfs,启动后发现trackerd都没有起来,报错:
ERROR - file: tracker_mem.c, line: 1535, the format of the file "/data/fdfs/tracker/data/storage_sync_timestamp.dat" is invalid, group_name: group1, colums: 5 > 4
查看/data/fdfs/tracker/storage_sync_timestamp.dat文件,如图:

因为49.186已经不用了,因此可将其删除,但是删除后还是起不来,此时将每个IP后一个,0删除,保留2个即可,如图:

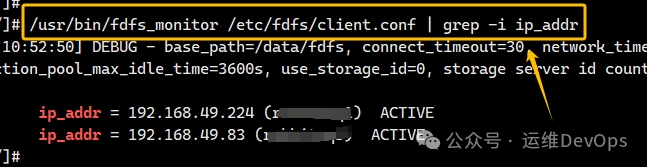
最后重启即可,查看此时集群状态,如图:
最后测试上传与下载都正常,之前数据也可以正常访问
为什么将storage_sync_timestamp.dat中49.186行删除掉,并将其他两行的最后一个,0删除,就可以启动了?
个人理解:第一个0表示同步偏移量,第二个0表示同步时间戳,因为有三个节点,每个节点都需要与其余两个节点同步,因此每个节点就会存在两个同步时间戳,如果只有两个节点,那么每个节点只需要与另一个节点同步即可,此时就需要一个同步时间戳
添加新节点
只要将刚才停止的storaged和trackerd重新启动,然后修改其余两个机器的配置文件,将tracker_server注释取消,就重新添加到集群中了
