




1、简介
在Kubernetes中,探针(Probe)用于检查容器的健康状态。Kubernetes提供了三种类型的探针:存活探针(Liveness Probe)、就绪探针(Readiness Probe)和启动探针(Startup Probe)。这些探针可以用来监测容器的健康状况,并根据需要对容器进行重启、停止访问或将其加入负载均衡。
2、存活探针、就绪探针、启动探针的区别
存活探针(Liveness Probe):
目的:用于确定容器是否仍然存活和运行。如果存活探针失败,Kubernetes会自动重启容器。
触发条件:存活探针在容器启动后定期执行,通常用于检查应用程序内部的健康状态。
使用场景:适用于监视容器内部应用程序的运行状况,以确保容器在发生问题时能够重新启动。
就绪探针(Readiness Probe):
目的:用于确定容器是否准备好接收流量。如果就绪探针失败,Kubernetes会停止将流量路由到容器。
触发条件:就绪探针在容器启动后定期执行,通常用于检查应用程序是否已完成初始化。
使用场景:适用于确保容器在接收流量之前已经准备好,以避免流量被路由到尚未初始化的应用程序。
启动探针(Startup Probe):
目的:用于确定容器在首次启动时是否已准备好接收流量。它在容器的初始启动过程中执行,不会导致容器重启。
触发条件:启动探针在容器首次启动时定期执行,用于检查容器是否已完成初始化。
使用场景:适用于需要一些初始化时间的应用程序,以确保它们在接收流量之前已经准备好。
注意:存活探针用于监视容器的运行状态,就绪探针用于监视容器的准备状态,而启动探针用于首次启动时的检查。这三种探针类型可以根据应用程序的不同需求来组合使用,以确保容器的稳定性和可用性。
3、三种检查方式
HTTP GET 探测:这是通过发送HTTP GET请求到容器的指定路径和端口,检查容器内应用程序的健康状态的方式。如果返回的HTTP状态码为200系列(通常是200 OK),则探针被认为是成功。这是一种常用的探测方式,特别适用于检查Web应用程序。
codelivenessProbe:
httpGet:
path: healthz
port: 8080
TCP Socket 探测:这是通过尝试建立到容器指定端口的TCP连接,检查容器是否处于健康状态的方式。如果连接成功,探针被认为是成功。这对于检查服务是否能够建立连接非常有用。
codelivenessProbe:
tcpSocket:
port: 5432
命令执行探测:这是通过在容器内部执行自定义命令或脚本,检查容器的健康状态的方式。如果命令的退出状态码为0,探针被认为是成功。这使您能够执行更复杂的自定义检查逻辑。
codelivenessProbe:
exec:
command:
- custom-check.sh
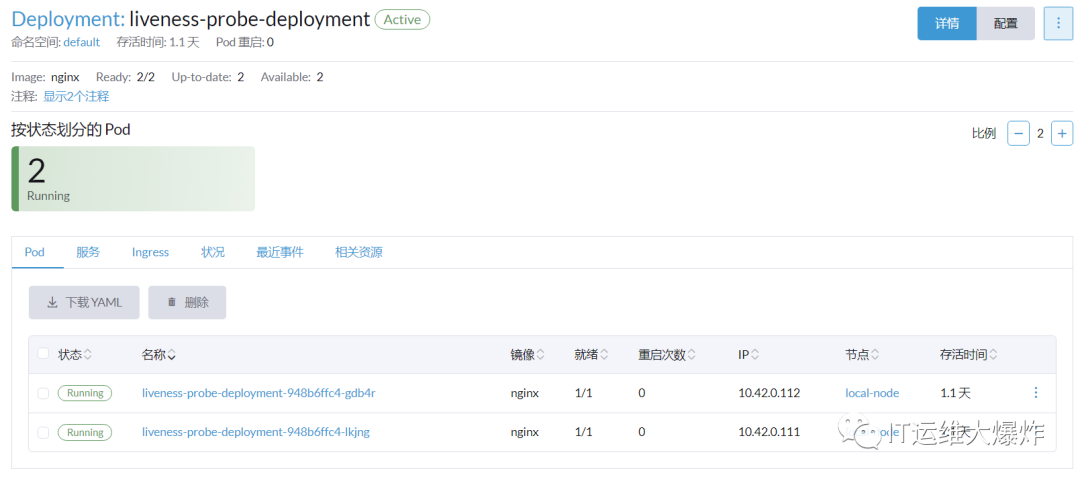
存活探针用于检测容器是否正在运行。如果存活探针失败,Kubernetes将自动重启容器,以确保应用程序的连续性。这里用一个 nginx 项目,设置 LivenessProbe 探测 nginx 项目的 80 端口下的 usr/share/nginx/html/index.html 接口,如果探测成功不重启pod,否则一直重启pod,直到存活探针探测成功。
[root@i-cd6217fb Liveness]# cat livenessProbe.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: liveness-probe-deployment
spec:
replicas: 2
selector:
matchLabels:
app: liveness-probe-app
template:
metadata:
labels:
app: liveness-probe-app
spec:
containers:
- name: liveness-probe-container
image: docker.io/library/nginx:latest
ports:
- containerPort: 80
# 存活探针配置
livenessProbe:
httpGet:
path: index.html
port: 80
initialDelaySeconds: 5
periodSeconds: 10
5、就绪探针(Readiness Probe)
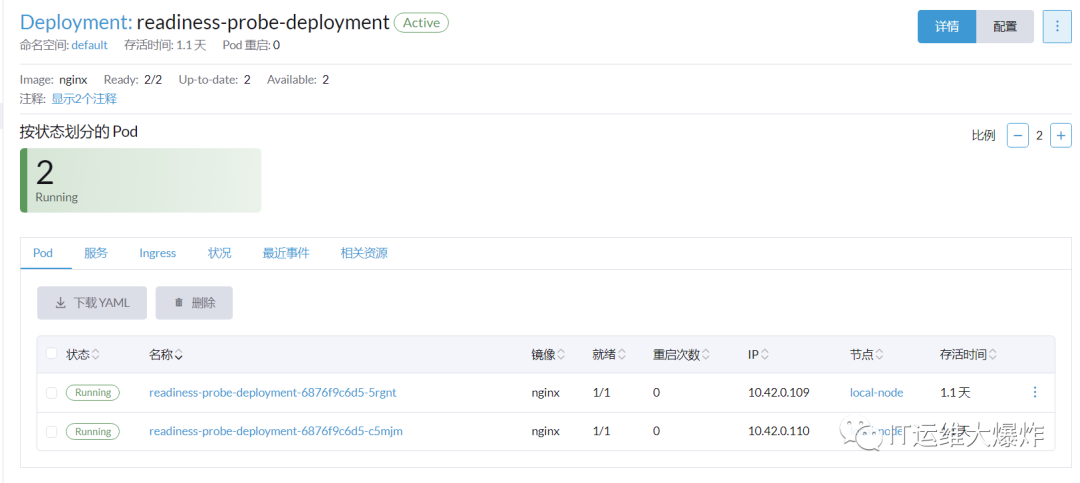
Pod 的ReadinessProbe 探针使用方式和 LivenessProbe 探针探测方法一样,也是支持三种,只是一个是用于探测应用的存活,一个是判断是否对外提供流量的条件。这里用一个 nginx 项目,设置 ReadinessProbe 探测 nginx 项目的 80 端口下的 usr/share/nginx/html/index.html 接口,如果探测成功则代表内部程序已经启动,就开放对外提供接口访问,否则内部应用没有成功启动,暂不对外提供访问,直到就绪探针探测成功。
[root@i-cd6217fb Liveness]# cat readinessProbe.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: readiness-probe-deployment
spec:
replicas: 2
selector:
matchLabels:
app: readiness-probe-app
template:
metadata:
labels:
app: readiness-probe-app
spec:
containers:
- name: readiness-probe-container
image: docker.io/library/nginx:latest
ports:
- containerPort: 80
# 就绪探针配置
readinessProbe:
httpGet:
path: index.html # 就绪探针检查的路径
port: 80 # 容器内部应用程序的端口
initialDelaySeconds: 8 # 容器启动后多久开始检查
periodSeconds: 10 # 检查频率
startupProbe探针简介
k8s 在1.16版本后增加startupProbe探针,主要解决在复杂的程序中readinessProbe、livenessProbe探针无法更好得判断程序是否启动、是否存活。进而引入startupProbe探针为readinessProbe、livenessProbe探针服务。
startupProbe探针与另两种区别
如果三个探针同时存在,先执行startupProbe探针,其他两个探针将会被暂时禁用,直到pod满足startupProbe探针配置的条件,其他2个探针启动,如果不满足按照规则重启容器。
另外两种探针在容器启动后,会按照配置,直到容器消亡才停止探测,而startupProbe探针只是在容器启动后按照配置满足一次后,不再进行后续的探测。
为什么要使用startupProbe、使用场景
startupProbe官方的解释(可以定义一个启动探针,该探针将推迟所有其他探针,直到 Pod 完成启动为止),startupProbe 启动探针存在的意义是不是:如果服务A启动需要1分钟 ,我们存活探针探测的时候设置的是initialDelaySeconds 10s后开始探测,如果探测的时候发现服务不正常,然后就开始重启Pod陷入死循环,但是如果意义在这个地方,那我们可以把探测时间调整大一点,failureThreshold 把这个也多设置几次就行了啊。为什么还要单独得设置一个satrtupProbe呢???
startupProbe的存在意义
startupProbe 和 livenessProbe 最大的区别就是startupProbe在探测成功之后就不会继续探测了,而livenessProbe在pod的生命周期中一直在探测。
如果没有startupProbe探针的话我们只设置livenessProbe探针话会存在如下问题:一个服务如果前期启动需要很长时间,那么它后面死亡未被发现的时间就越长,为什么会这么说呢?假设我们一个服务A启动完成需要2分钟,那么我们如下开始定义livenessProbe。
livenessProbe:
httpGet:
path: test
prot: 80
failureThreshold: 1
initialDelay:5
periodSeconds: 5
如果我们这样定义的话,那pod 5s就会根据重启策略进行一次重启,这个时候你会发现pod一直会陷入死循环,那我们可以按照上面的猜想把配置改成这样。
livenessProbe:
httpGet:
path: test
prot: 80
failureThreshold: 6
initialDelay:40
periodSeconds: 5
你肯定会说你看这样不就行了吗?这样的话pod就不会陷入死循环能启动起来了,确实这样pod能够启动起来了,但是你有没有考虑过这样一个问题,当我们启动完成之后,在后期的探测中,你需要6*5=30s才能发现这个pod不可用,这个时候你的服务已经停止运行了30s你才发现,这在生产中有可能是不会被原谅的。还有就是这边只是我们假设一个服务A需要1分钟才能起来,但是在实际生产中你如何定义这些值呢???针对上面这两个问题引入startupProbe之后都解决了。
[root@i-cd6217fb Liveness]# cat Startup.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: startup-probe-deployment
spec:
replicas: 2
selector:
matchLabels:
app: startup-probe-app
template:
metadata:
labels:
app: startup-probe-app
spec:
containers:
- name: startup-probe-container
image: docker.io/library/nginx:latest
ports:
- containerPort: 80
# 存活探针配置
livenessProbe:
httpGet:
path: index.html
port: 80
failureThreshold: 1
initialDelay: 5
periodSeconds: 5
# 启动探针配置
startupProbe:
httpGet:
path: /index.html
port: 80
failureThreshold: 60
initialDelay: 5
periodSeconds: 5
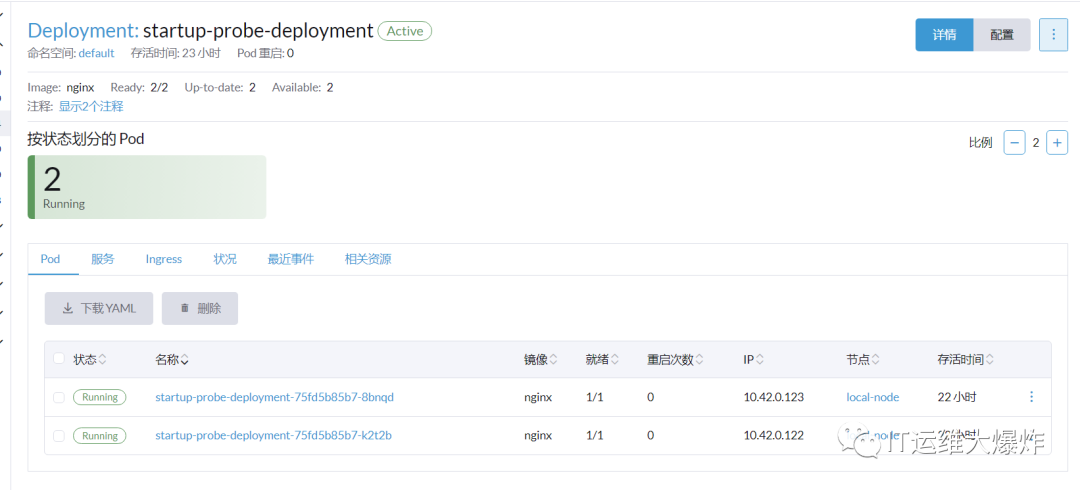
我们这样设置之后,由于startupProbe探针的存在,程序有60乘以5s=300s的启动时间,一旦startupProbe探针探测成功之后,就会被livenessProbe接管,这样在运行中出问题livenessProbe就能在1乘以5=5s内发现。如果启动探测是3分钟内还没有探测成功,则接受Pod的重启策略进行重启。
欢迎大家扫码关注:

本公众号只写原创,不接广告、不接广告、不接广告。下期小伙伴想学习什么技术,可以私信发我吆。

