




DBA的日常苦恼
日常工作中,你是否遇到过这样的超级苦恼:MGR主备集群中,主集群执行一个事务时正常,但通过主从方式回放该事务到备集群,竟然回放失败了,超过了MGR的事务大小限制。此时你是不是很纳闷:为什么同一事务还能被区别对待呢,电视剧也演不出这样的剧情呀,无法跳过该事务,手动执行也无法判断是否还有其他事务,我们又该如何解决呢?话不多说,直接上案例~
展昭来报

展昭
报!报!报!大师兄,大事不好了,二师兄也被抓走了~
何事惊慌,速速报来!

包拯
展昭
禀大人,情况如下:主备两套MGR集群,备集群通过主从同步方式连接主集群从库,进行增量数据的同步回放。目前备集群同步状态因为一个事务导致中断,报错信息如下:
Worker 1 failed executing transaction '00000000-0000-04a0-0ecd-534e003b9e34:199723359'at master log binlog.004955, end_log_pos 2478533049; Error 'Execute backend SQL on nodedatanode198_3316 failed with 3100: Error on observer while running replication hook 'before_commit'..' on query. Default database: ''. Query:'COMMIT'
包拯初问
包拯
昭,遇到此问题,你都做了哪些分析,速速说来。
禀大人,我做了如下分析,但依然没有头绪,还望大人解惑。
展昭
1)查看错误日志,确定回放事务超过MGR的事务大小限制
2024-07-12T05:21:13.728865+08:00 2424 [ERROR] [MY-011735] [Repl] Plugin group_replication reported: '[GCS] Gcs_packet's payload is too big. Only packets smaller than 2113929216 bytes can be compressed. Payload size is 2197817290.'2024-07-12T05:21:13.728984+08:00 2424 [ERROR] [MY-011735] [Repl] Plugin group_replication reported: '[GCS] Error preparing the message for sending.'2024-07-12T05:21:13.735759+08:00 2424 [ERROR] [MY-011614] [Repl] Plugin group_replication reported: 'Error while broadcasting the transaction to the group on session 2424'2024-07-12T05:21:13.735833+08:00 2424 [ERROR] [MY-010207] [Repl] Run function 'before_commit' in plugin 'group_replication' failed
2)调整事务大小限制,依然报错
将group_replication_transaction_size_limit改为2G和0,回放该事务,依然报错超过事务大小限制。
此时的展昭有点崩溃,告警短信一直在催促,领导的死亡追问也在一遍一遍敲打着他的小心脏。
包拯深思
包拯
昭啊,还是有点嫩,听我给你分析:
1)首先,判断一下这个事务id对应的sql语句是啥,事务大小是多少;
2)其次,判断为什么group_replication_transaction_size_limit会失效;
3)然后,判断该事务在最原始的节点写入的binlog事务大小是多少;
4)最后,对比一下最原始节点写入的事务大小和最后回放的事务大小,是否存在事务放大情况。
展昭出招
招式1:解析binlog,判断报错事务id对应的sql语句是啥,事务大小是多少
1)根据报错的gtid信息,寻找对应的binlog范围
show binlog events in 'binlog文件' limit 10;
2)查看gtid对应的事务大小(解析从库binlog)

展昭
sql语句是insert select行为,原来这个事务对应的大小是2.3G,所以回放报错了,那为啥改了group_replication_transaction_size_limit不生效呢?
招式2:分析为什么group_replication_transaction_size_limit会失效
由于默认开启了MGR压缩,且压缩采用了LZ4算法。该算法最大只能压缩2113929216,如果事务超过该值,会导致事务提交失败。因此,事务最多限制为2G,group_replication_transaction_size_limit设置为0也没有生效。
参考文档:
1:group_replication_compression_threshold系统变量指定了组成员之间发送的消息在超过该阈值(字节)时才会被压缩。
2:group_replication_compression_threshold的值应该在所有组成员上保持一致。
3:组复制使用LZ4压缩算法来压缩组中发送的消息,LZ4 压缩算法的最大支持输入大小为 2113929216 字节。
4:启用压缩下,超过此大小的事务无法提交(2113929216 字节)。
5:如果将此变量设置为零,则压缩功能将被禁用。
招式3:分析该事务最原始的写入记录

展昭
内心OS:果然如包大人所料,可为啥事务本身大小是1G,到回放的时候是2G呢?这是妥妥的聚宝盆呀,一元变两元。事情有点大,得速速汇报。
展昭反馈
展昭
报!报!报!大~大事不~不~不好啦!
昭,莫慌,你家驴被偷啦?还是你脑袋被驴踢啦!
包拯
展昭
大人果真神机妙算,聪明过人,小的佩服的五体投地。
彩虹屁少拍,啥事?速速报来!
包拯
展昭
大人,果然存在事务放大的情况,同一个事务在主节点和从节点事务中,大小由1G变2G了,这可咋办呀?
莫慌,容我想想。
包拯
包拯再思
1.先分析一下binlog event组成部分,通过相关event的长度大小,直观查看问题出在哪里?
2.接着剖析该事务的binlog event长度,看看是否有参数影响了binlog event。
展昭速去
1)Binglog event由以下组成
BEGINTABLE_MAP_EVENTROWS_QUERY_EVENT (the SQL statement that started the transaction)WRITE_ROWS_EVENT/UPDATE_ROWS_EVENT/DELETE_ROWS_EVENTCOMMIT
2)剖析一下该事务在写入端的binlog event长度
展昭
该gtid对应的事务是insert select语句(由3.3图可得),一个table_map,四个write_rows,每个阶段的event大小如下:
table_map_event:150rows_query_event:2623write_rows_event:1024288552
展昭
1024291507-1024288552-2623-150 = 332,源端的事务是正常的,写入的binlog 也是正常的。
昭啊,你是不是傻,那不还有332个字节没对上呢?

石敢当
展昭
吃啥啥不剩,动脑子的事你是一点都不干,时间戳用啥存,其他的标识符用啥存,不都得从332里出吗?
有道理!!!
石敢当
3)那为什么会有四个write_rows,且事务大小是否一致呢?
石敢当
昭啊,你再给我解释解释这个问题~
InnoDB/GreatDB 为了优化大事务,会将一个大事务拆成多个小事务进行并发处理,因此binlog 中也会产生多个write_rows。至于为什么是4个write_rows,而不是6个、8个write_rows,昭在这里暂不深究,有兴趣的可以线下研究。
展昭
4)再解析一下回放端(从节点)该事务对应的binlog event

展昭
该gtid同步到从节点之后,变成了四个table_map、rows_query、write_rows,原因是源端做了事务拆分。因此经过binlog同步后变成4个,但在一个事务里面。
然后呢?赶紧分析,我还等结果呢。
石敢当
展昭
……(展昭无语)
5)通过单个write_rows,分析哪个event阶段存在了放大
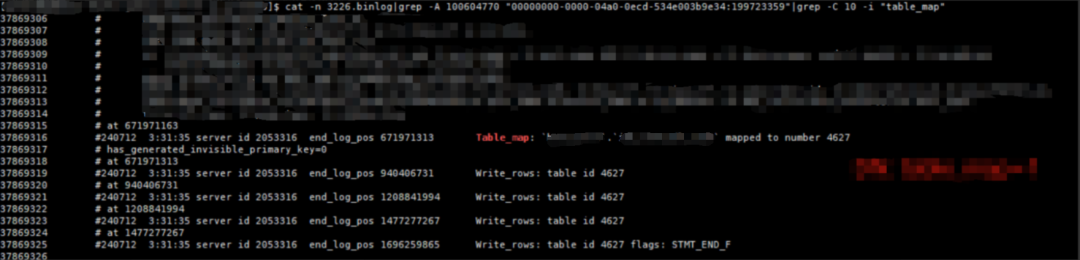
9379074 #240712 3:31:35 server id 33100 end_log_pos 124144942 Query thread_id=3727 exec_time=348 error_code=09379075 SET TIMESTAMP=1720726295/*!*/;9379076 SET @@session.sql_mode=99090478/*!*/;9379077 BEGIN9379078 /*!*/;9379079 # at 1241449429379080 #240712 3:31:35 server id 33100 end_log_pos 478732811 Rows_query9379081 # BINLOG '9379082 # FzOQZhPEVB8AjAAAAIIOGyYAAGsFAAAAAAEACWJvc3NfYWNjdAAQaWRjX3JhdGVfZGxfdF8wNQAa...
table_map_event
# at 47873281113984122 #240712 3:31:35 server id 33100 end_log_pos 478732960 Table_map: `boss_acct`.`idc_rate_dl_t_05` mapped to number 910713984123 # has_generated_invisible_primary_key=0
展昭
其他阶段的event和源端都基本一致,但rows_query event相差很大,这段产生事务大小为338M,四个加起来>1G,因此,当前binlog server 的事务比源端的事务大1G的根源就在于此。
等会,等会,你这338M怎么算出来的,我咋云里雾里呢?
石敢当
展昭
下次聚餐记得坐小孩桌,我不想让你拉低我的智商,用at 值去减,就是字节数。478732811-124144942。
你小子这么损我,以后别落我手里。
石敢当
6)rows_query_event为什么这么大?这些乱码又是什么,由什么产生的?
binlog_rows_query_log_events = on
展昭
原来如此, 该乱码是根据写入端table_map_event和rows_log_event格式生成的的base 64串,用于记录可视化的sql语句。在binlog语句中,base 64串相对是一个二进制串,更长且占用字节更多。因此,开启该参数后,在从库binlog中写入的rows_query才会存在放大,从2623达到了338M。
昭,你真厉害,我是你的小迷弟。
石敢当
展昭

展昭顿悟
展昭
禀大人,此事的来龙去脉我已全盘搞清楚了。
嗯?给我讲讲。
包拯
展昭
该问题主要是主备集群中的节点开启了binlog_rows_query_log_events导致的。在主集群中,执行insert select语句,rows_query较小(2623),由于执行时对事物进行了拆分,由一条拆分成多条写入到binlog中,通过binlog同步到备集群中,rows_query因为开启了binlog_rows_query_log_events,将sql语句转成base 64串,导致rows_query出现了膨胀,出现了事务的放大,又因为mgr的事务压缩限制,导致调整事务大小限制失效。
何人配置的该参数?速速缉拿归案,二营长,我的狗头铡呢?拉上来!
包拯
石敢当
禀大人,是DBA通过运维平台模板设置的,念其初犯,且有初衷(辅助看sql语句),饶他一次吧~
好吧,狗头铡又用不上了~
包拯
展昭
不用的好,不用的好。
故障寄语
出现故障并不可怕,可怕的是我们没有任何解决思路。如果这篇文章没有帮到你,请关注《包拯断案》专栏,期待下篇文章给你带来更多精彩干货。



