





1
2
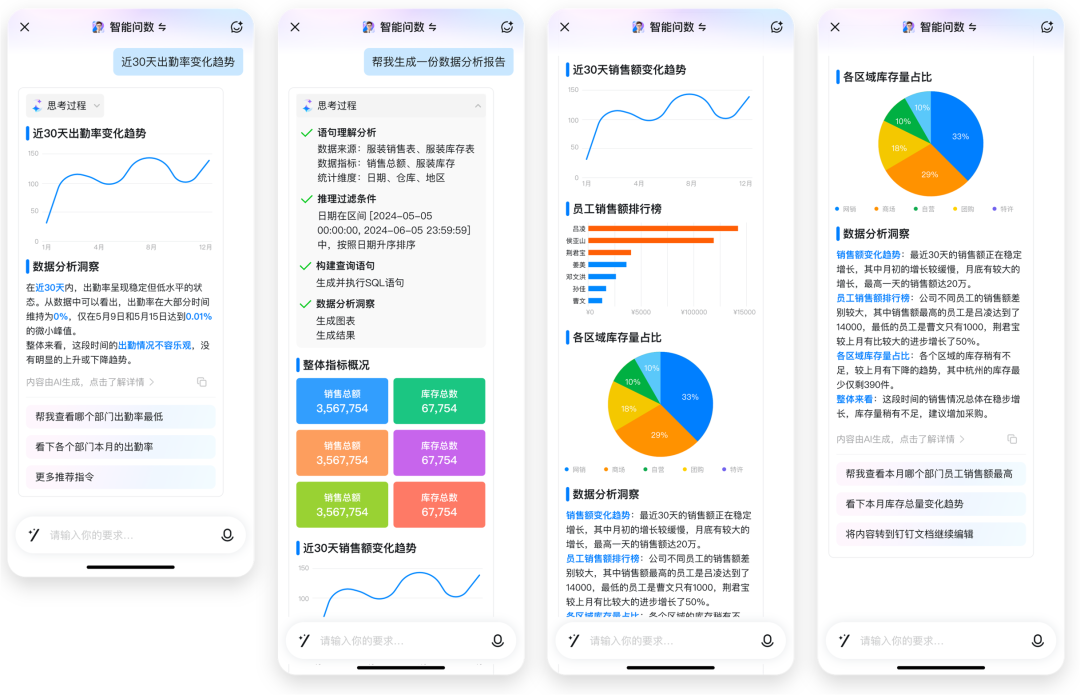
DMS+AnayticDB支持智能问数场景
向量召回提升模型输出准确率
因此,通过AnayticDB for PostgreSQL向量检索引擎对10亿+核心企业实体(企业名称、部门名称、员工名称、专有名词等)实现向量化,针对企业用户随意输入的问题通过向量检索召回最准确的企业实体,然后再结合大模型提供智能问答、智能问数等服务,大大提升了AI助理对实体的识别和大模型准确率。
构建企业专属实体知识库
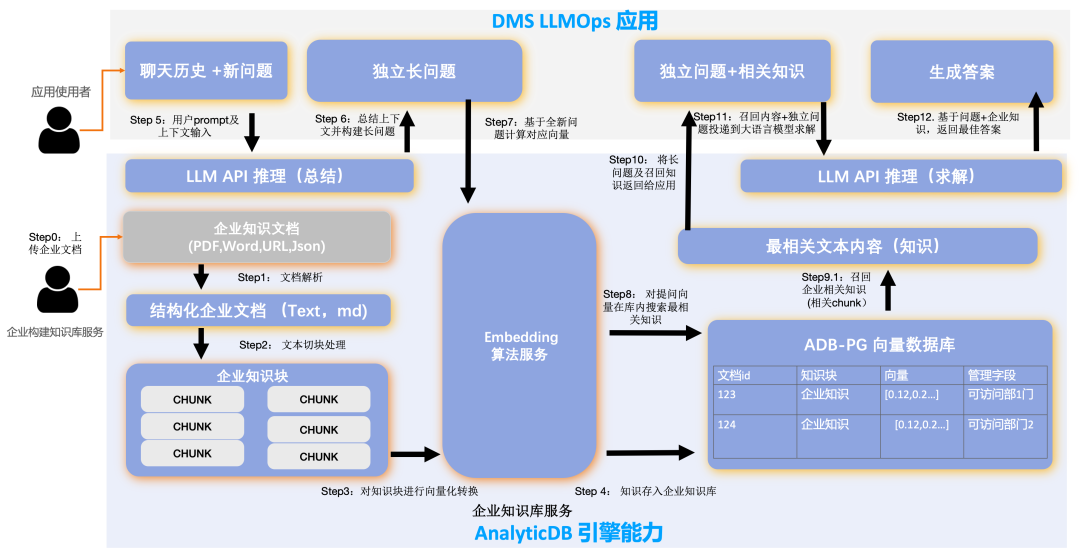
大模型虽然能解答普适性的问题,但在一些垂直领域上无法覆盖企业专属知识以及无法保障数据更新时效性,导致大模型应用在企业中落地困难。企业可采用 DMS+AnayticDB for PostgreSQL 向量检索引擎构建企业专属知识库,对结构化、半结构化和非结构化数据通过 Embedding 向量化后存储到 AnayticDB for PostgreSQL 中。结合大模型推理服务,将企业私有数据融入到智能问答、智能问数、智能创造等大模型应用中。构建企业专属大模型知识库的步骤大致如下:
1)数据预处理:在向量化之前需要对非结构化的文档、图片进行预处理,包括文档/图片解析、切块,预处理的质量会对问答召回和准确率有非常大的影响。
2)Embedding: 通过大模型的Embedding算法对预处理后的数据块进行向量化,并将结果存储到向量数据库中。
3)向量检索: 大模型将用户的问题进行向量化后在向量数据库中进行向量检索和近似度计算,同时结合结构化的条件过滤进行权限和范围的限定
构建企业专属知识库
3
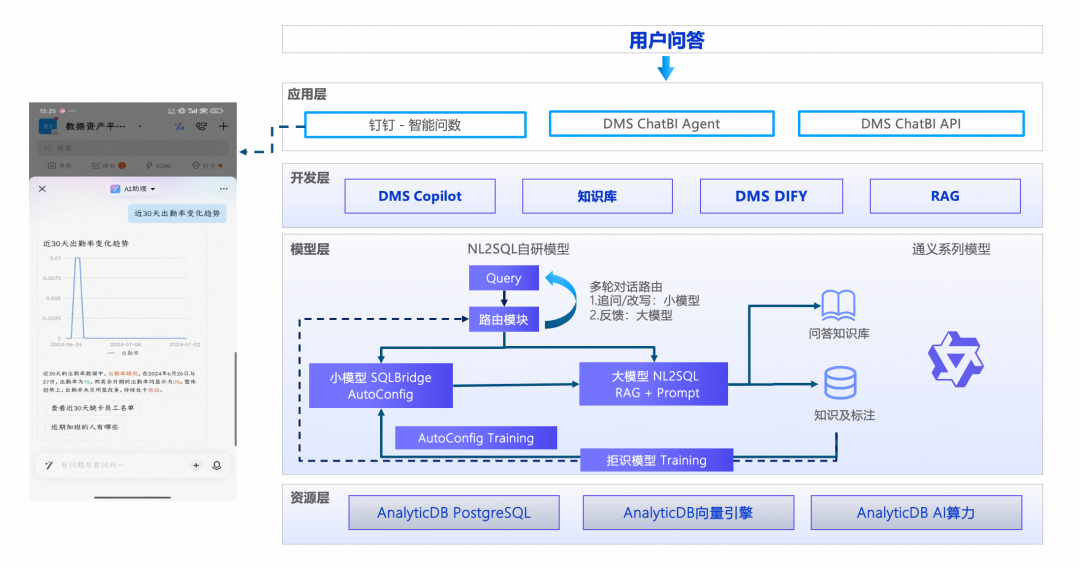
高度数据安全的ChatBI能力
4
DMS+AnalyticDB优势特点
优势1:一站式融合分析
优势2:社区合作紧密
优势3:功能完善,性能极致
支持向量数据流式导入,索引压缩,事务,和各类相似度算法。
较比同类产品有更高的写入吞吐和查询性能。
优势4:解决方案丰富
DMS+X 提供从文档解析、Chunk、Embedding、向量近似度计算、检索全套OpenAPI服务,让用户快速落地。
提供DMS之上的Data+AI能力的开箱即用和Dify的一键部署方式,在10分钟内一键构建企业专属大模型和向量数据库,快速搭建企业级Gen-AI应用。
支持构建图搜图、文搜图等产品化解决方案。
优势5:精品NL2SQL模型
开箱即用:自识别用户数据库元数据,实现开箱自助分析。
大小模型融合:创新性地使用大模型分析用户意图,小模型准确SQL生成的融合形态,实现更精准的服务。
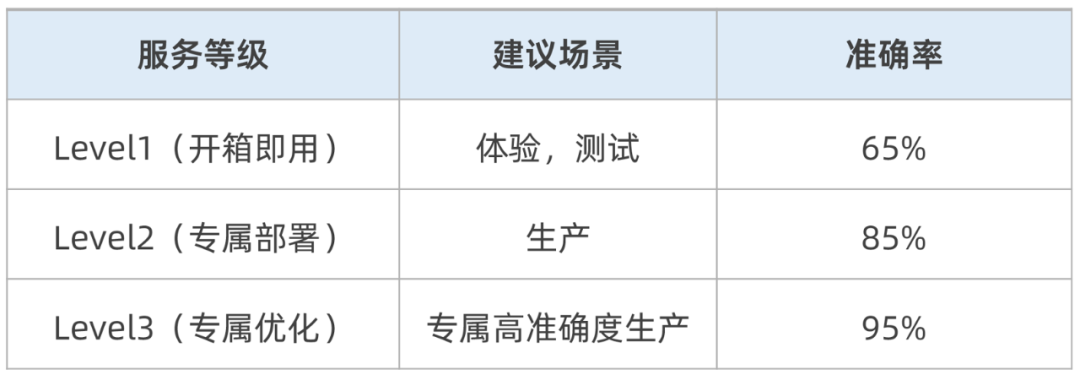
数据私域安全保障:全数据链路及推理服务私域部署,实现数据不出域,保障企业数据安全,DMS自研NL2SQL模型提供了3个等级的准确率。
效果可持续优化:结合持续学习、历史记录标注、RAG干预等方式,实现准确率可调优;目前提供了3个等级的NL2SQL的模型能力。
5
总结与展望
钉钉AI助理通过采用AnayticDB向量检索引擎构建企业专属知识库,结合大模型推理服务,将企业私有数据融入到智能问答、智能问数、智能创造等应用中,并通过DMS构建数据流程编排服务,实现业务逻辑的ChatBI编排和私域精品NL2SQL模型部署,满足不同企业对数据不出域的最高安全的要求。钉钉AI助理目前已累计服务了上千客户,涉及零售、互联网、物流、交通等多个行业。
Data+AI为企业提供了新的增长途径,企业必须认识到Data+AI的重要性,并将其作为战略实施重点。通过将Data+AI融入核心业务,企业能够更好地挖掘数据价值,优化运营流程和决策机制,从而促进智能化转型,显著提升市场竞争力。
未来,借助阿里云Data+AI解决方案的可自定义编排的LLM工作流以及不断提供的解决方案,不仅能够实现智能问数的拓展应用,还能够通过大模型方案解决企业经营的各项问题,从而提升经营效率,加速企业智能化转型,为企业发展带来新的动力。

互动有礼


欢迎咨询
🎁 若您对钉钉智能问数场景感兴趣,欢迎点击文末「阅读原文」留下您的信息,前20名填写表单的用户将获得精美礼品一份,先到先得!

*图片仅供参考,最终以实际发放礼品为准
点击咨询 智能问数场景

