




众所周知,特别是最新版的Oracle数据库版本命名从23c(Converged)到了23ai,同时Oracle也将“以AI为中心的企业基础架构”作为核心战略目标。本期跟随总监,一起来看看如何在Oracle 23ai中实现RAG。
本次操作系统使用为OracleLinux 9.4(数据库)/8.10(LLM),数据库版本为单实例Oracle 23ai(23.5.0.24.07),LLM为通义千问2-7B(Qwen2-7B)(当然也可以使用其他的模型)。除sqlplus外,本篇文章部分展示使用最新版sqldeveloper。
1 数据库向量嵌入能力
1.1 导入向量嵌入模型
在开始基于Oracle 23ai的数据库RAG的演示之前,先演示Oracle Vector DB的库内向量嵌入能力,使用text2vec-large-chinese模型,需要将向量嵌入模型处理为标准的ONNX格式:bge-base-zh-v1.5.onnx(大小需控制在1G内),onnx文件放到oracle家目录中。
create or replace directory MODELS_DIRas'/home/oracle';BEGINDBMS_VECTOR.LOAD_ONNX_MODEL(directory=>'MODELS_DIR',file_name =>'bge-base-zh-v1.5.onnx',model_name =>'embedding_model');END;/
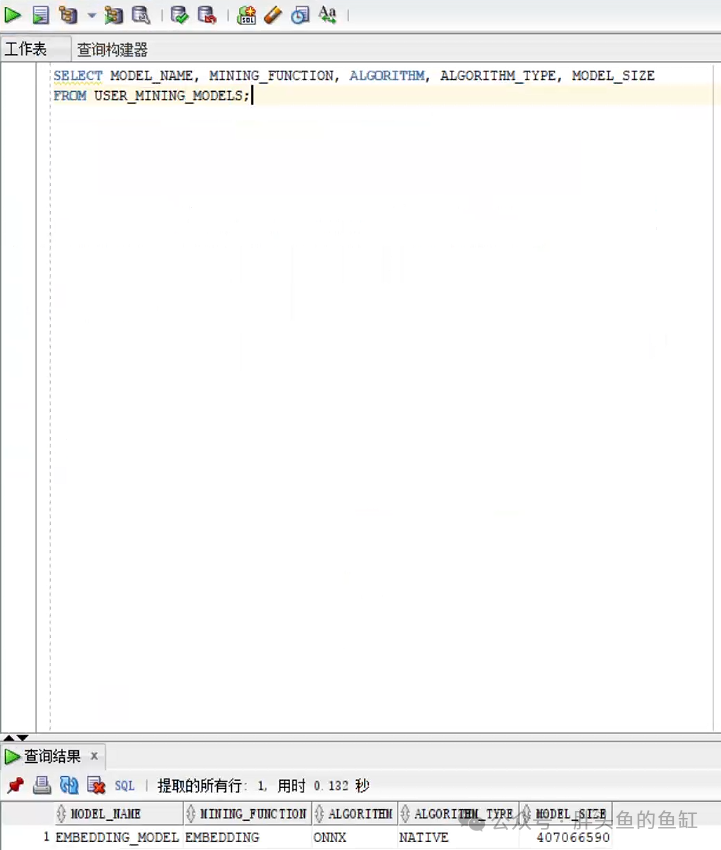
可以通过以下语句查看已导入的模型:
SELECT MODEL_NAME, MINING_FUNCTION, ALGORITHM, ALGORITHM_TYPE, MODEL_SIZE FROM USER_MINING_MODELS;
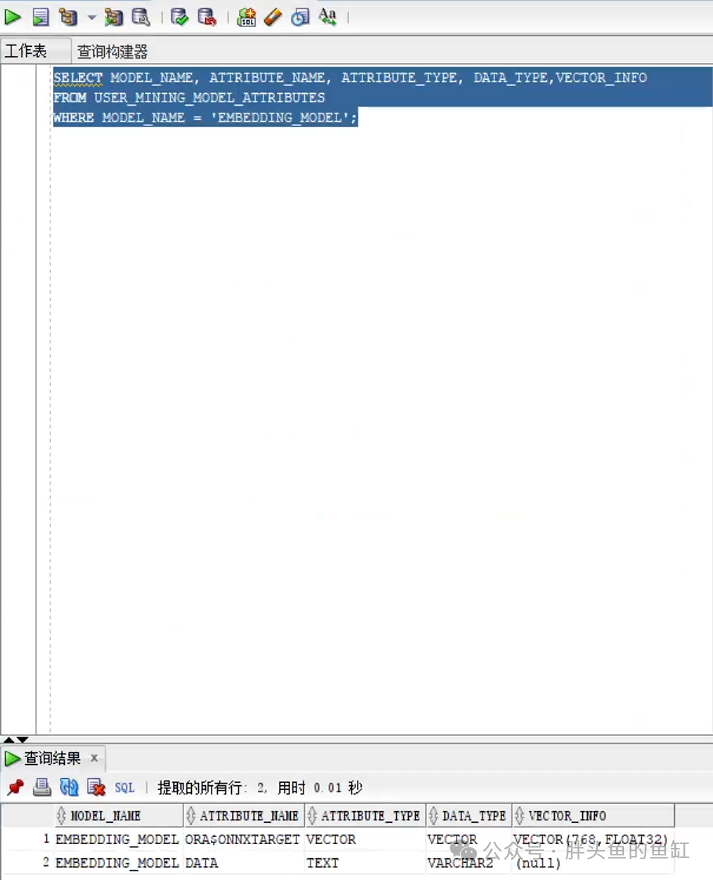
SELECT MODEL_NAME, ATTRIBUTE_NAME, ATTRIBUTE_TYPE, DATA_TYPE,VECTOR_INFO FROM USER_MINING_MODEL_ATTRIBUTES WHERE MODEL_NAME ='EMBEDDING_MODEL';
1.2 向量嵌入
SELECT VECTOR_EMBEDDING(embedding_model USING 'Hello, World' as data) AS embedding;
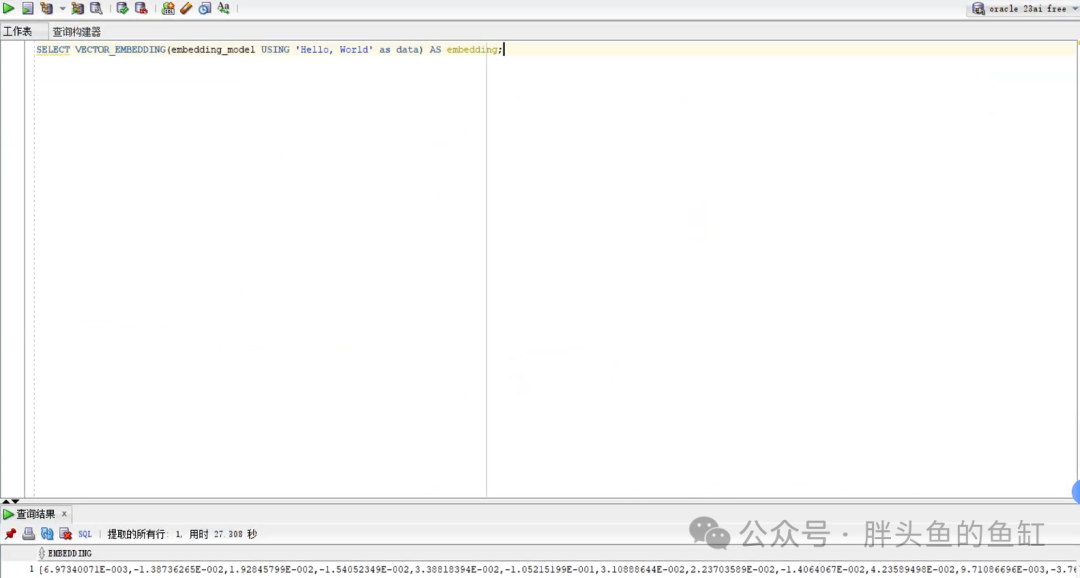
这里就可以看到在数据库内即可实现向量嵌入操作,当然数据库内没有GPU,其嵌入效率远不如外部使用GPU提供算力的模型。当然Oracle数据库也可以在库内直接调用外部大模型,这将在后面的RAG环境进行演示。
2 部署LLM
Ollama是一个大模型运行框架,可以非常快捷的使用无GPU环境运行大模型。这里使用Ollama来运行通义千问LLM(当然也可以直接使用Python或其他方式运行),机器IP地址为10.10.10.21。
1.1 安装Ollama
curl -fsSL https://ollama.com/install.sh | sh
1.2 启动Ollama
vim /etc/systemd/system/ollama.service#在[Service]中添加以下内容Environment="OLLAMA_HOST=0.0.0.0:8098"
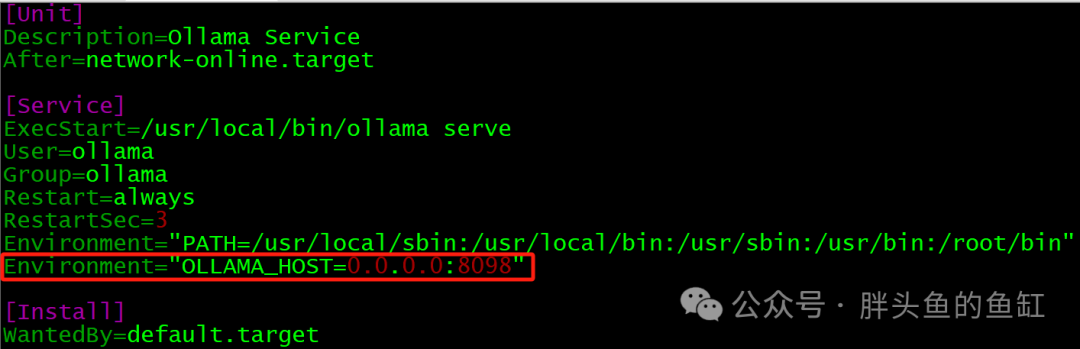
systemctl start ollama.service
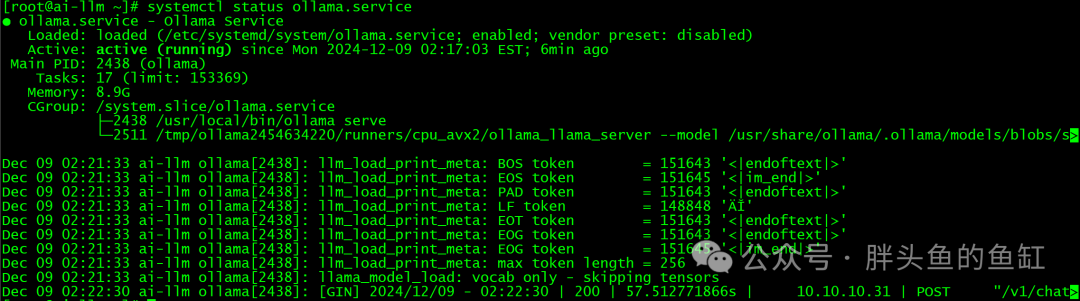
1.3 启动Qwen2-7B
OLLAMA_HOST=0.0.0.0:8098 ollama run qwen2:7b-instruct

1.4 测试部署
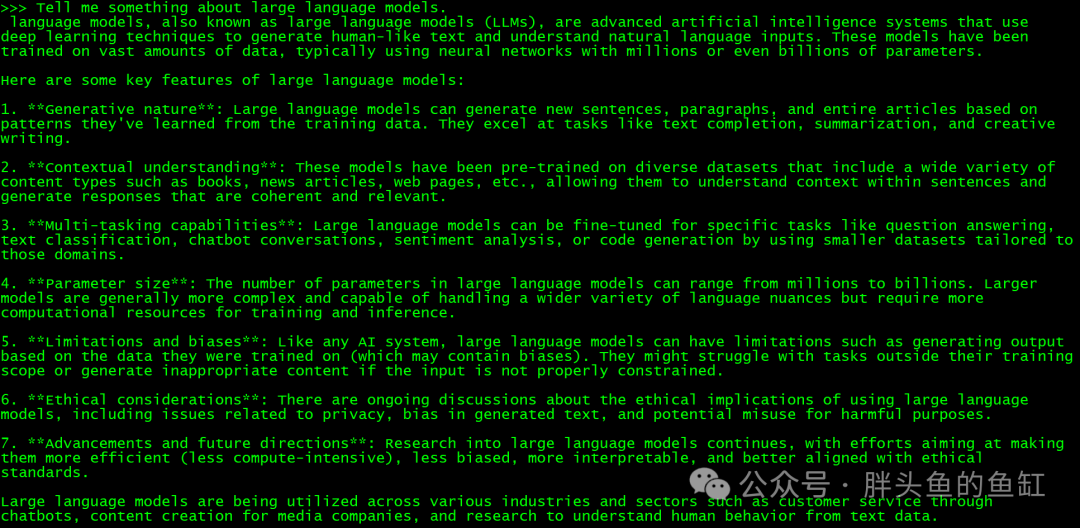
curl http://10.10.10.21:8098/v1/chat/completions \-H "Content-Type: application/json" \-d '{"model": "qwen2:7b-instruct","messages": [{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": "Tell me something about large language models."}]}'
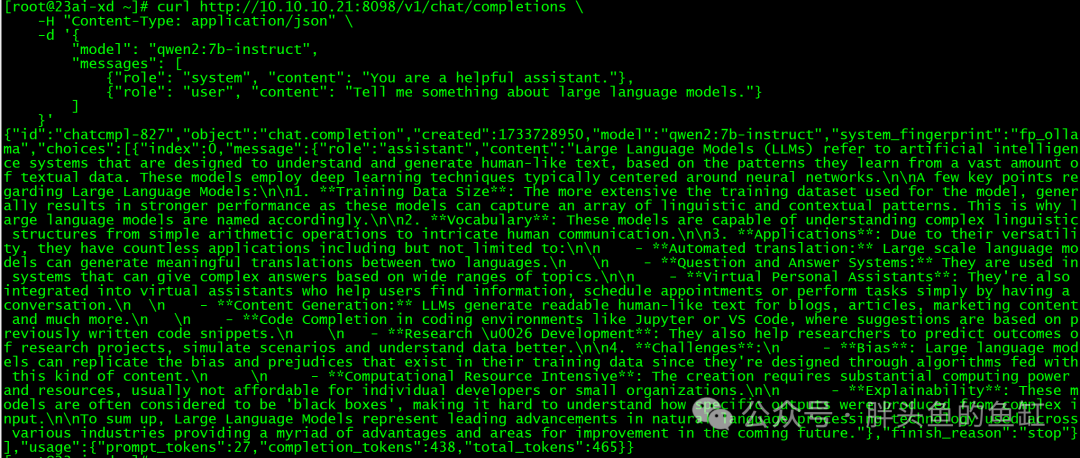
由于没有GPU,响应略慢。
3 数据库配置
数据库基本连接信息为:10.10.10.31:1521/pdbprod1(PDB)。
使用最新版的sqldeveloper做演示。
2.1 安装APEX
APEX下载地址:https://www.oracle.com/tools/downloads/apex-downloads/
unzip apex_24.1.zipcd apex/sqlplus / as sysdba
@apexins.sql SYSAUX SYSAUX TEMP /i/@?/rdbms/admin/utlrp.sql
2.2 创建用户并赋权
create tablespace users datafile size 500m autoextend on next 500m maxsize unlimited;create user llm identified by llm;grant DB_DEVELOPER_ROLE to llm;alter user llm default tablespace users quota unlimited on users;
2.3 导入测试数据
CREATE TABLE lab_vecstore (id VARCHAR2(50) DEFAULT SYS_GUID() PRIMARY KEY,dataset_name VARCHAR2(50) NOT NULL,document CLOB,cmetadata JSON,embedding VECTOR(*, FLOAT32));
这里使用Oracle提供的一套数据以及基于Python的API WEB工具实现数据向量化与导入(不做操作展示)。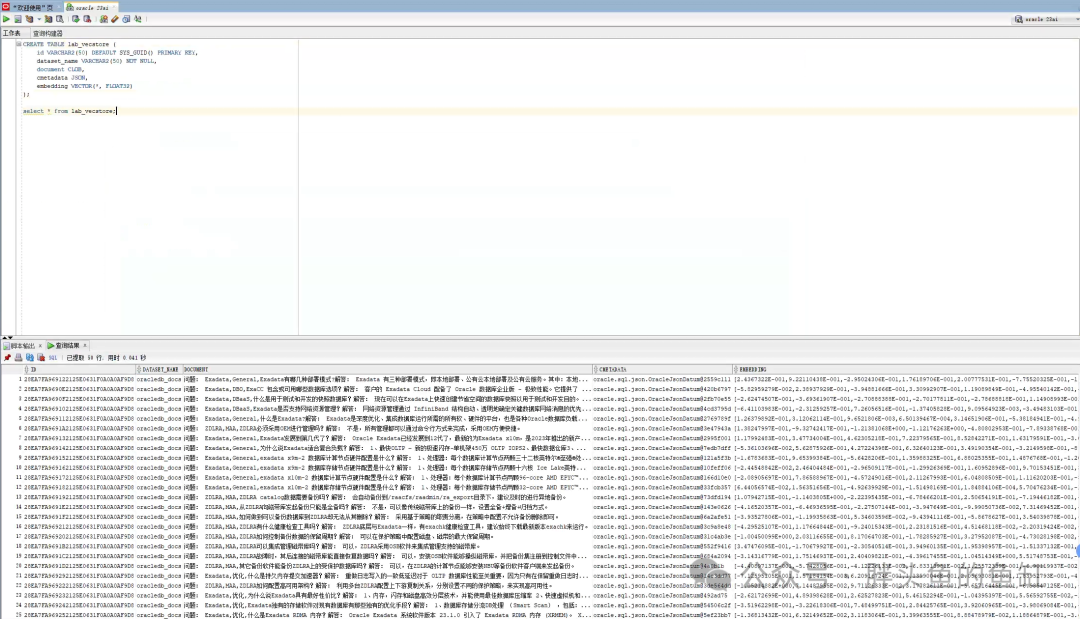
2.4 直接LLM对话
SET SERVEROUTPUTON;
declarel_questionvarchar2(500) :='Oracle 23ai 新特性';l_input CLOB; l_clob CLOB;j apex_json.t_values;l_embedding CLOB;l_context CLOB;l_rag_result CLOB;beginapex_web_service.g_request_headers(1).name := 'Content-Type';apex_web_service.g_request_headers(1).value := 'application/json';l_input := '{"text": "' || l_question || '"}';-- 第一步:提示工程:给大语言模型明确的指示l_input := '{"model": "qwen2:7b-instruct","messages": [{"role": "system", "content": "你是一个诚实且专业的数据库知识问答助手,请回答用户提出的问题。"},{"role": "user", "content": "' || l_question || '"} ] }';-- 第二步:调用大语言模型,生成结果l_clob := apex_web_service.make_rest_request(p_url => 'http://10.10.10.21:8098/v1/chat/completions',p_http_method => 'POST',p_body => l_input);apex_json.parse(j, l_clob);l_rag_result := apex_json.get_varchar2(p_path => 'choices[%d].message.content', p0 => 1, p_values => j);dbms_output.put_line('*** Result: ' || chr(10) || l_rag_result);end;/
这里可能会出现以下报错: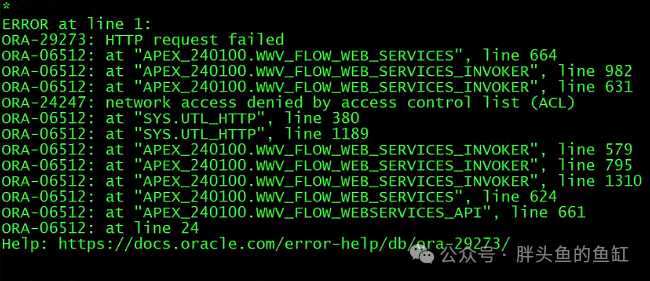
需要在CDB执行以下命令:
BEGINDBMS_NETWORK_ACL_ADMIN.APPEND_HOST_ACE(host =>'*',ace => xs$ace_type(privilege_list => xs$name_list('connect','resolve'),principal_name =>'APEX_240100',principal_type => xs_acl.ptype_db));END;/
然后会继续出现以下报错: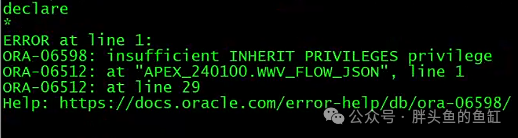
需要在CDB执行以下命令:
grant inherit privileges on user sys to APEX_240100;
然后可以正常出结果了: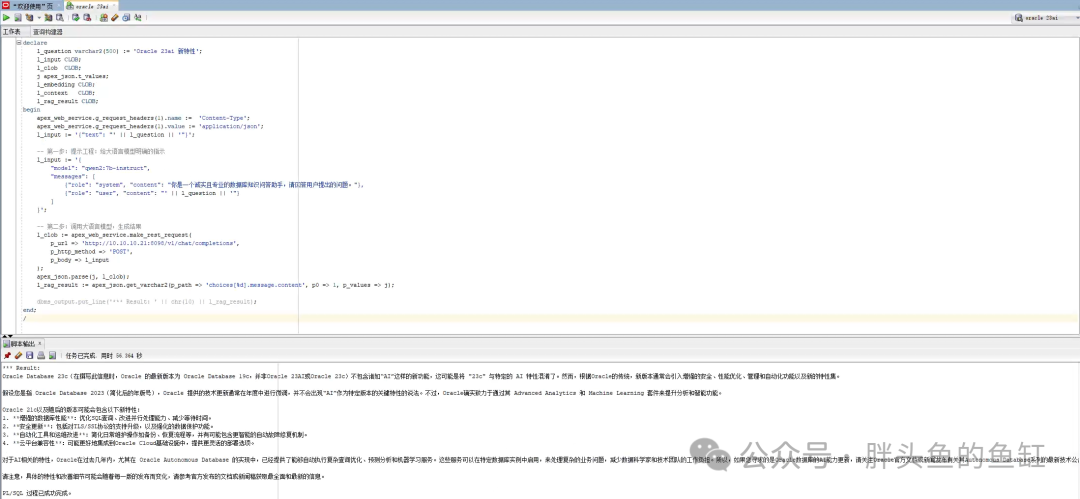
但是这里我们可以看到未使用RAG方式,大模型给出的结果非常离谱。当然也可以多次执行,结果会有所不同,但总体来说结果都比较离谱。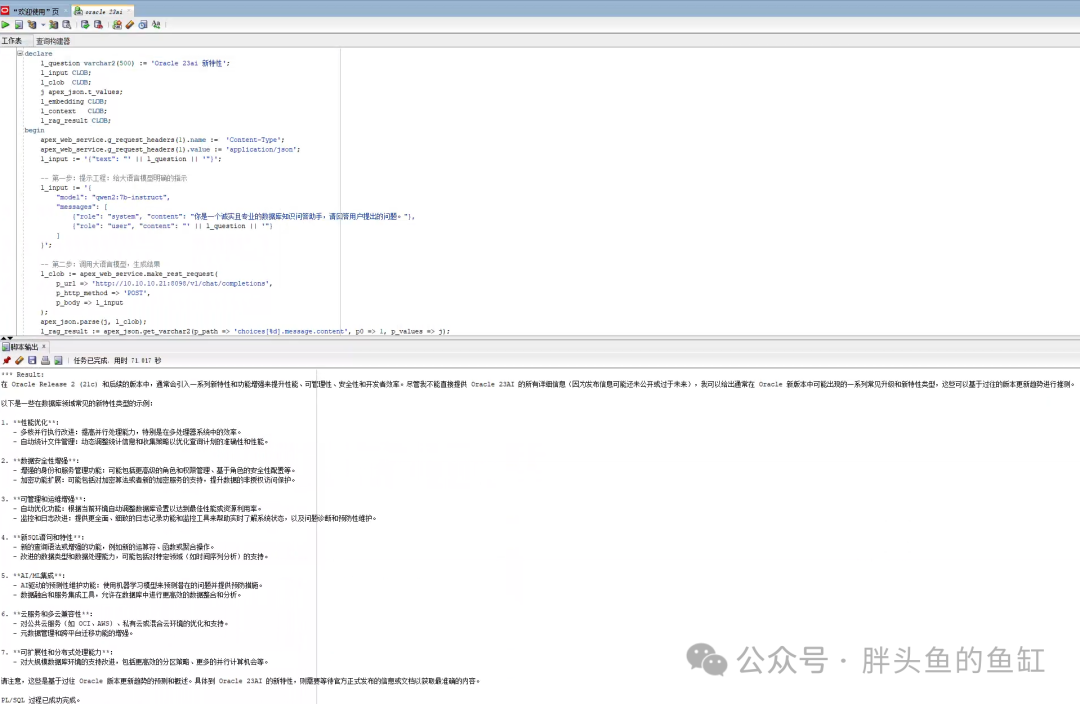
2.5 RAG方式与LLM对话
这里先说明一下,在10.10.10.21服务器8099端口运行了另一套基于text2vec-large-chinese的向量嵌入程序,也就是前面导入数据使用的,在使用RAG方式与LLM对话过程中会先将提问向量化后与知识库进行关联匹配。
declarel_questionvarchar2(500) :='Oracle 23ai 新特性';l_input CLOB;l_clob CLOB;j apex_json.t_values;l_embedding CLOB;l_context CLOB;l_rag_result CLOB;beginapex_web_service.g_request_headers(1).name := 'Content-Type';apex_web_service.g_request_headers(1).value := 'application/json';l_input := '{"text": "' || l_question || '"}';-- 第一步:向量化用户问题l_clob := apex_web_service.make_rest_request(p_url => 'http://10.10.10.21:8099/workshop/embedding',p_http_method => 'POST',p_body => l_input);apex_json.parse(j, l_clob);l_embedding := apex_json.get_varchar2(p_path => 'data.embedding', p_values => j);-- dbms_output.put_line('*** embedding: ' || l_embedding);-- 第二步:从向量数据库中检索出与问题相似的内容for rec in (selectdocument, json_value(cmetadata,'$.source') as src_filefrom lab_vecstorewhere dataset_name='oracledb_docs'order by VECTOR_DISTANCE(embedding, to_vector(l_embedding))FETCH FIRST 3 ROWS ONLY) loopl_context := l_context || rec.document ||chr(10);end loop;-- 第三步:提示工程:将相似内容和用户问题一起,组成大语言模型的输入l_context :=replace(replace(replace(l_context,'''',''),'"','\"'),chr(10),'\n');l_input := '{"model": "qwen2:7b-instruct","messages": [{"role": "system", "content": "你是一个诚实且专业的数据库知识问答助手,请根据提供的上下文内容,回答用户的问题。\n 以下是上下文内容:' || l_context || '"},{"role": "user", "content": "' || l_question || '(请仅根据提供的上下文内容回答,不要试图编造答案)"}]}';-- 第四步:调用大语言模型,生成RAG结果l_clob := apex_web_service.make_rest_request(p_url => 'http://10.10.10.21:8098/v1/chat/completions',p_http_method => 'POST',p_body => l_input);apex_json.parse(j, l_clob);l_rag_result := apex_json.get_varchar2(p_path => 'choices[%d].message.content', p0 => 1, p_values => j);dbms_output.put_line('*** RAG Result: ' || chr(10) || l_rag_result);end;/
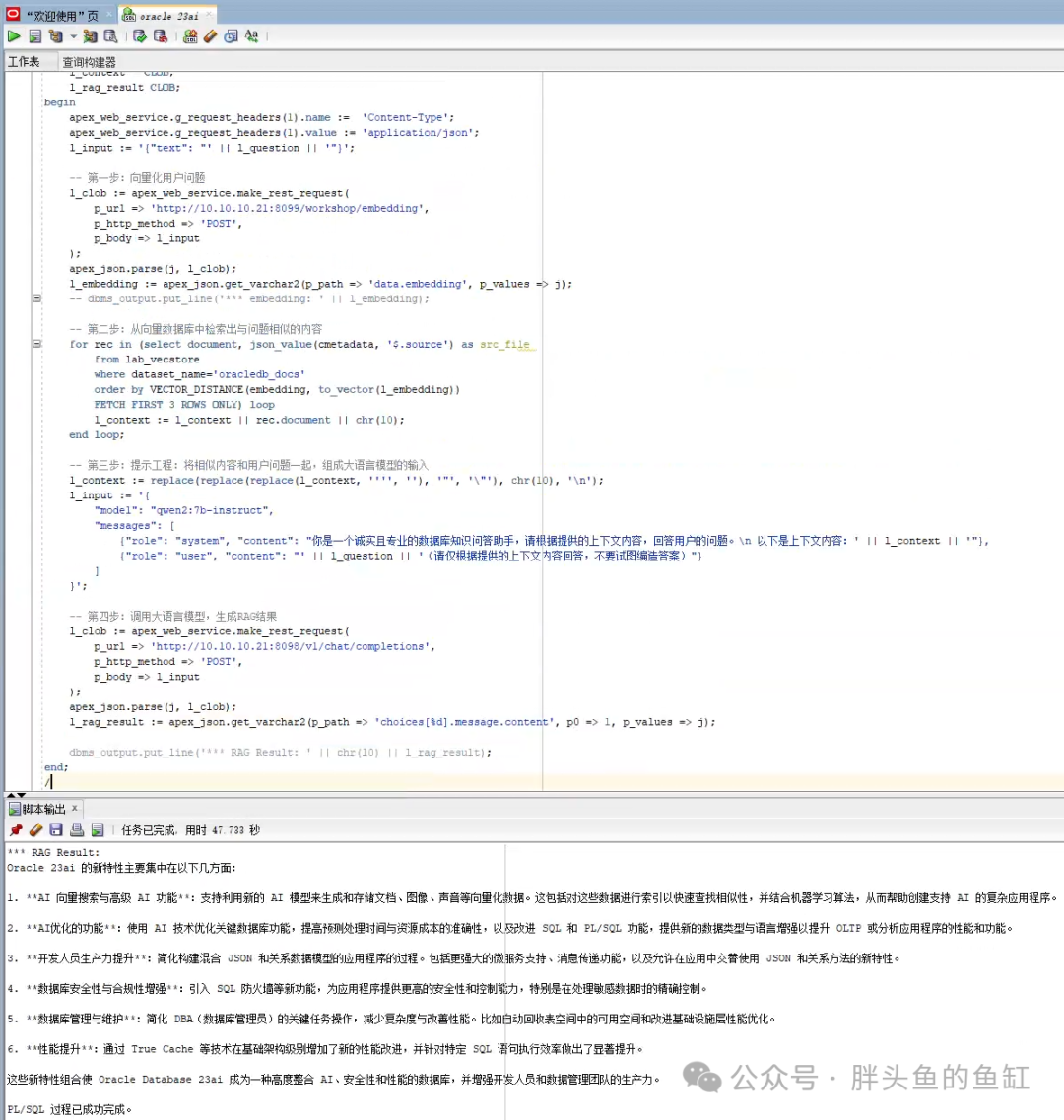
这时候我们可以看到使用RAG方式与LLM对话的结果就会准确很多。这里我们可以再执行一次: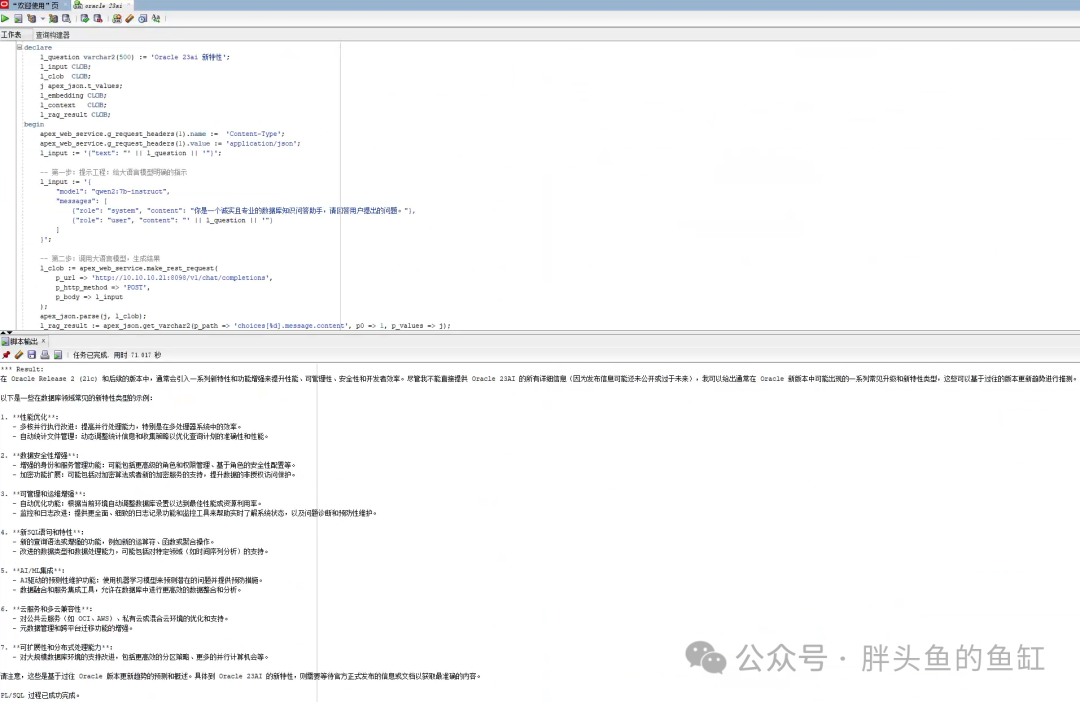
总结
本期主要展示了Oracle 23ai的库内与库外向量嵌入能力,以及配合使用APEX可以在数据库中调用外部模型实现RAG。
编辑:殷海英
