




序言
为了解决用户在使用 StarRocks 时的更新需求,StarRocks 社区引入了主键表,通过快速的索引和 delete vector 技术来实现保证查询效率的同时也满足实时更新能力。
StarRocks 存算分离架构从 3.1 版本开始,支持存算分离架构的部署模式,一开始我们只支持将主键索引存储在内存以及 local disk 上,在主键索引的存储上并未实现真正的云原生化。
PK 揭秘
StarRocks 存算分离架构中,每次数据摄入在 StarRocks 内部都会产生一个新的数据版本(Rowset),而 Rowset 内则会包含一定数量的数据文件(segment),具体文件数取决于单次摄入的数据量以及系统资源等因素。
对于 PK 表,由于本次的摄入中部分记录可能会修改历史版本的数据记录,因此,我们便需要一种机制能快速找到该记录的历史版本所在的位置,找到位置信息后,再将该历史上的记录标记为删除(也即生成所谓的 delete vector)。因此,对于 PK 表来说,随着导入的数据外还生成了另外两种文件,第一是 pk index,保存了当前所有历史记录的最新位置信息,第二是 delete vector 文件, 记录了本次导入版本针对历史上哪些记录进行了更新。
让我们以一个简单的例子来说明其中原理。假设我们创建了一个简单 PK 表,表结构如下:
MySQL [test]> show create table tx\G*************************** 1. row ***************************Table: txCreate Table: CREATE TABLE `tx` (`id` int(11) NOT NULL COMMENT "",`age` int(11) NULL COMMENT "") ENGINE=OLAPPRIMARY KEY(`id`)COMMENT "OLAP"DISTRIBUTED BY HASH(`id`) BUCKETS 1
表的针对该表存在两次数据导入。 第一次插入一批新数据:
insert into tx values (1, 18);insert into tx values (2, 28);insert into tx values (3, 38);insert into tx values (4, 48);insert into tx values (5, 58);
此时系统只会生成一个 segment 数据文件(segment 1),其中包含上述5条记录,除此以外还产生了一个 PK index 文件,其中记录了这 5 条记录的位置,如下图所示:

另外,由于本次是首次插入新数据,并不涉及修改历史上的数据,因此,生成的 delete vector 为全 0,表示没有删除任何历史记录。
第二次则是针对上面的两个数据记录进行更新:
update tx set age = 19 where id = 1;update tx set age = 29 where id = 2;
此时首先生成了本次的新数据文件 segment2,只包含本次的新记录 (1, 19) 和 (2, 29),然后根据主键 1 和 2 查找上面的 pk index,获取到两条记录的位置信息,分别为<seg: 1, row: 1> 和 <seg: 1, row: 2> 并标记老的记录被删除,生成 delete vector。最后,由于产生了新的记录,需要生成新的 pk index 文件,此时的文件组织如下:

云原生索引
书接上回,我们知道主键索引在 PK 表中扮演了极其重要的角色且在之前的版本中,存算分离架构只支持内存和 local disk 索引,目前主要在用的是 local disk 索引,但其存在如下一些问题会导致使用起来没那么爽:
1. 磁盘空间的使用与 local data cache 管理不统一,可能导致磁盘空间抢占问题,尤其主键列较多的情况下,主键索引会占据较大存储空间,可能需要手动介入来处理磁盘空间打满的问题。下面是在某个用户那就观察到了本地磁盘空间占用情况:

2. 扩缩容问题,扩缩容时会引起 Tablet 迁移,迁移后的 Tablet 的 pk index 在目的 CN 节点上需要重建 PK index,这个过程比较耗时,影响实时数据导入性能
为了解决上述问题,从 StarRocks 3.3.3 版本开始,StarRocks 正式推出了云原生索引,支持将云原生索引写入到对象存储,这样就带来了以下几大关键优势:
1. 索引文件和 data cache 存储空间统一管理,不再有烦人的磁盘空间打架问题 2. 弹性扩缩容后不需要再重建索引,对于导入性能不再有任何影响
性能 PK
可能很多用户会关心采用 云原生索引后性能是否存在衰退,我们也做了较为详细的测试,由于 PK Index 主要在导入流程中使用,因此,我们这里主要从几个常见场景进行性能对比评估:1). 批量离线导入 2). 实时微批导入 3). 节点弹性场景。
出于篇幅考虑,我们不在这里罗列具体的测试步骤,只简单展示下各个场景的效果对比。
批量离线导入
采用 tpch 100G 数据进行单批次导入,两种索引方式耗时分别为
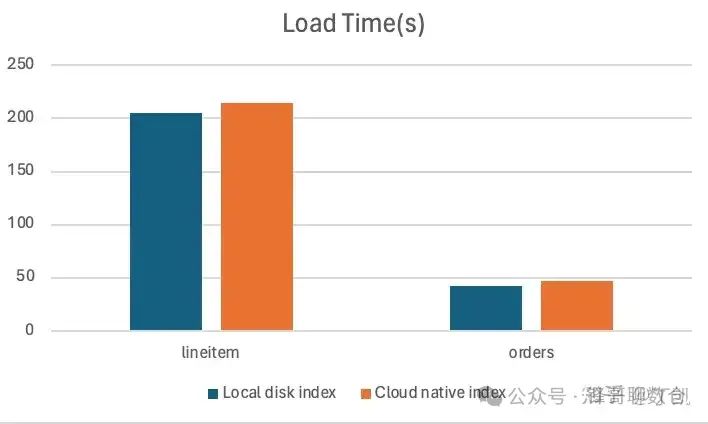
微批实时导入
导入大小 8G 随机生成的订单数据,切分为100个文件,使用 stream load 分 100 次导入。

弹性场景
该场景模拟节点变更后的数据导入性能,首先导入批量数据,接下来停止 CN 节点,最后发起新的导入事务,该事务的耗时中会包含重建索引的时间。通过对比该事务的延迟,验证云原生索引的弹性。

简单总结下上面的测试:
1. 无论是大批导入或是小批实时导入,云原生索引性能与本地磁盘索引性能基本持平,且我们还在不断优化 2. 在弹性场景中,云原生持久化索引的延迟性能提升达到了本地磁盘持久化索引的 10 倍
写在最后
从 StarRocks 3.3.2 版本开始,我们支持了云原生持久化索引。在建表语句中指定 persistent_index_type 为 CLOUD_NATIVE 即可开启该功能
CREATE TABLE `orders` (`o_orderkey` int(11) NOT NULL COMMENT "",`o_orderdate` date NOT NULL COMMENT "",...) ENGINE=OLAPPRIMARY KEY(`o_orderkey`, `o_orderdate`)PROPERTIES ("enable_persistent_index" = "true","persistent_index_type" = "CLOUD_NATIVE");
从 3.3.6 版本开始,云原生索引已经成为存算分离架构下 PK 表的默认选择,从 3.3.7 版本开始,你还可以手动将原有的基于 local disk 创建的 pk 表调整为云原生模式,执行下面的命令即可:
alter table xx set("persistent_index_type" = "CLOUD_NATIVE");
如果您当前正在使用存算分离的主键模型表,强烈建议你使用云原生主键索引,让你的幸福感再提升一个档次。
