




一、问题现象
2024年11月27日下午18:10分左右客户一套生产数据库的中出现insert批量插入2000的语句执行慢问题,该问题在11月26日09:40分同样出现过一次。
二、问题分析
2.1 环境信息
MariaDB 10.3.27 + 双主单写
2.2 查看11月27日awr日志中processlit及其他时间段processlist及系统负载和数据库负载
该insert执行较慢但未发现锁等待;查看其他时间段awr该sql 也有执行,但未发现执行时间长的问题;查看系统负载和数据库负载,系统负载和数据库负载都不高。

2.3 查看insert插入慢时间点的redo刷盘及缓冲池
insert插入慢时间点的redo刷盘及缓冲池状态都正常
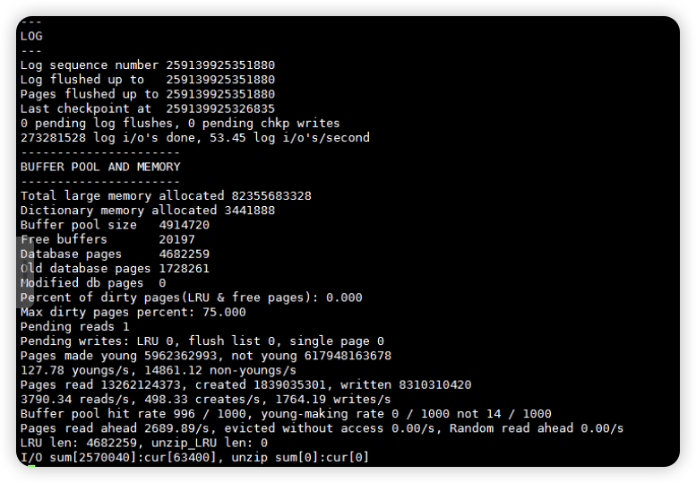

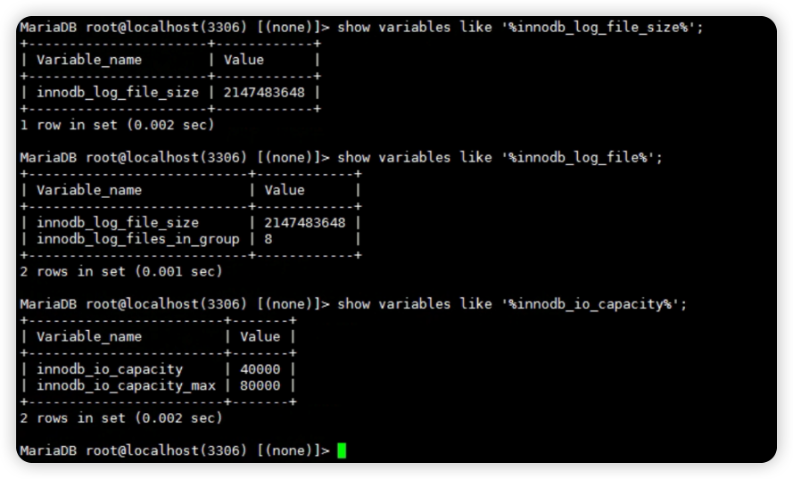
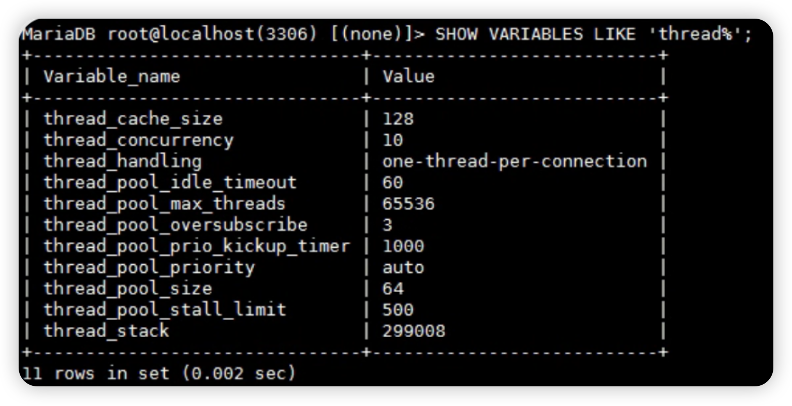
2.4 检查数据库参数配置,未发现异常

2.5 检查出现慢sql时间点的事务记录,未发现锁等待

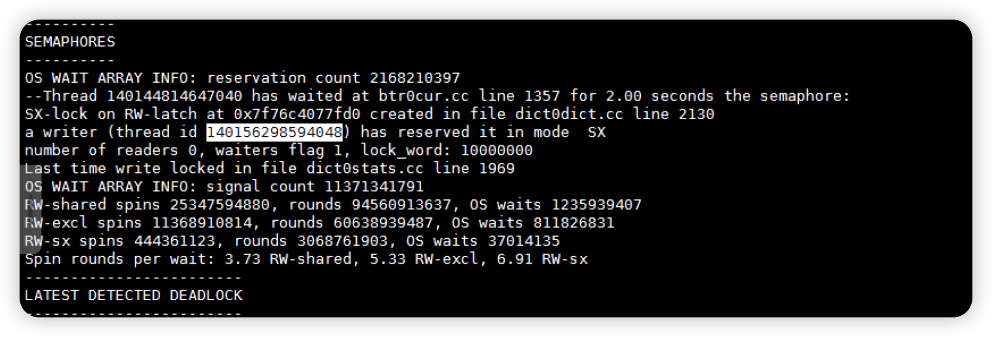
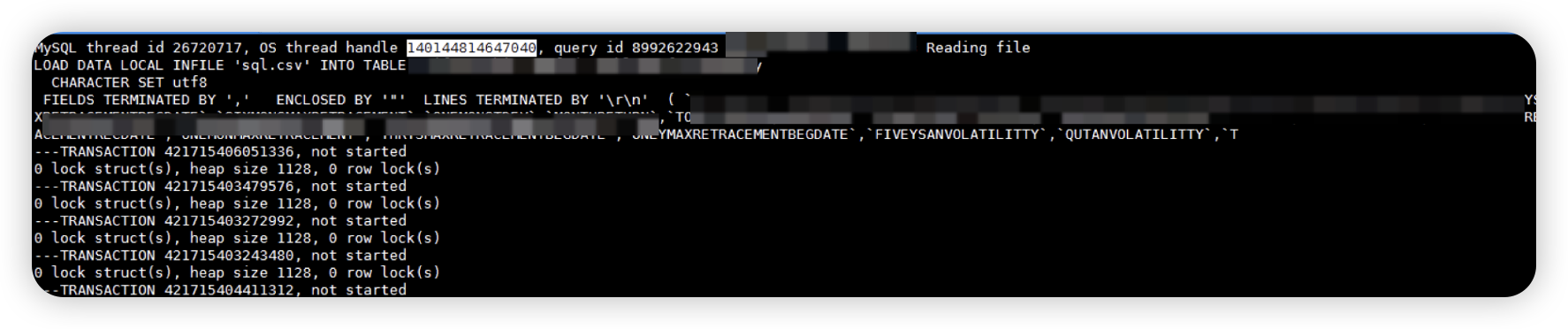
2.6 检查出现慢sql时间点SEMAPHORE信息即等待信号量(semaphore)
在出现慢sql时间点的SEMAPHORE信息即等待信号量(semaphore)的信息,发现有事务都在等待140156298594048 这个线程线程以SX(共享 - 独占)模式持有该信号量导致insert线程在cc line 1357的调用位置产生了等待,导致了insert语句插入很慢。
注意:该等待不是常规意义上的事务之间的锁等待,而是数据页或者内存结构上的的latch等待,所以在会话和事务上看不到锁等待。
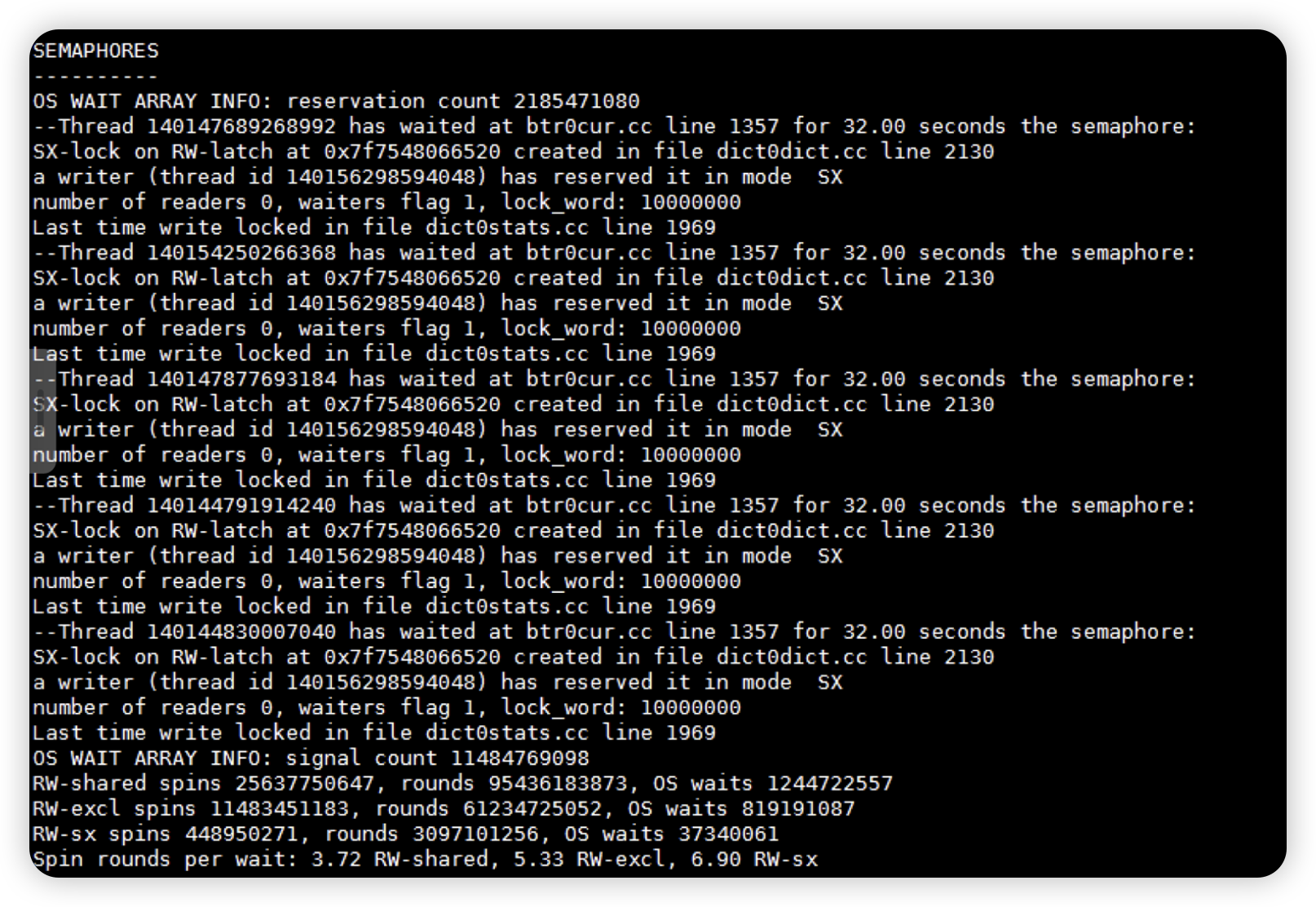
2.7 查找信号量堵塞信息其中一个事务信息
通过被阻塞的tread 140147689268992 查找到对应的thread id 为27039902,在会话中即为客户发现的insert慢语句,确认insert 执行较慢的语句是因为等待140156298594048持有的latch锁导致阻塞
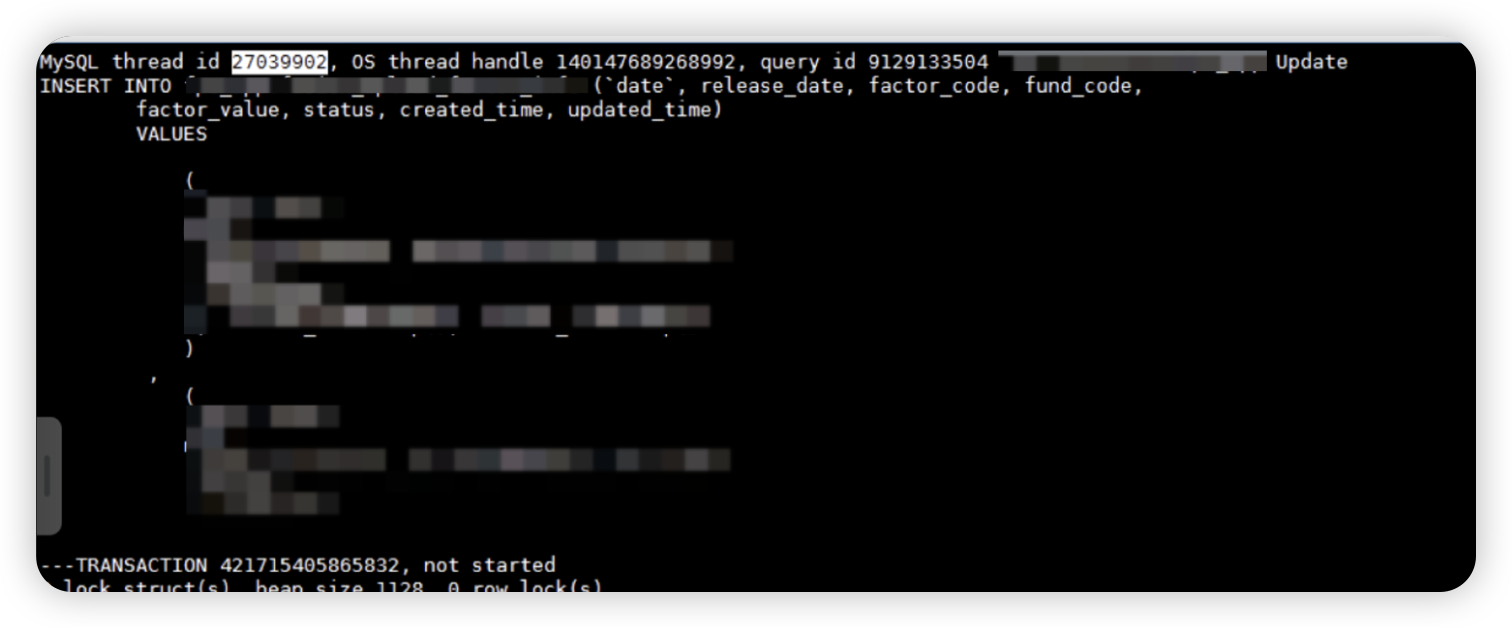

2.8 查找信号量堵塞信息堵塞源140156298594048对应的信息
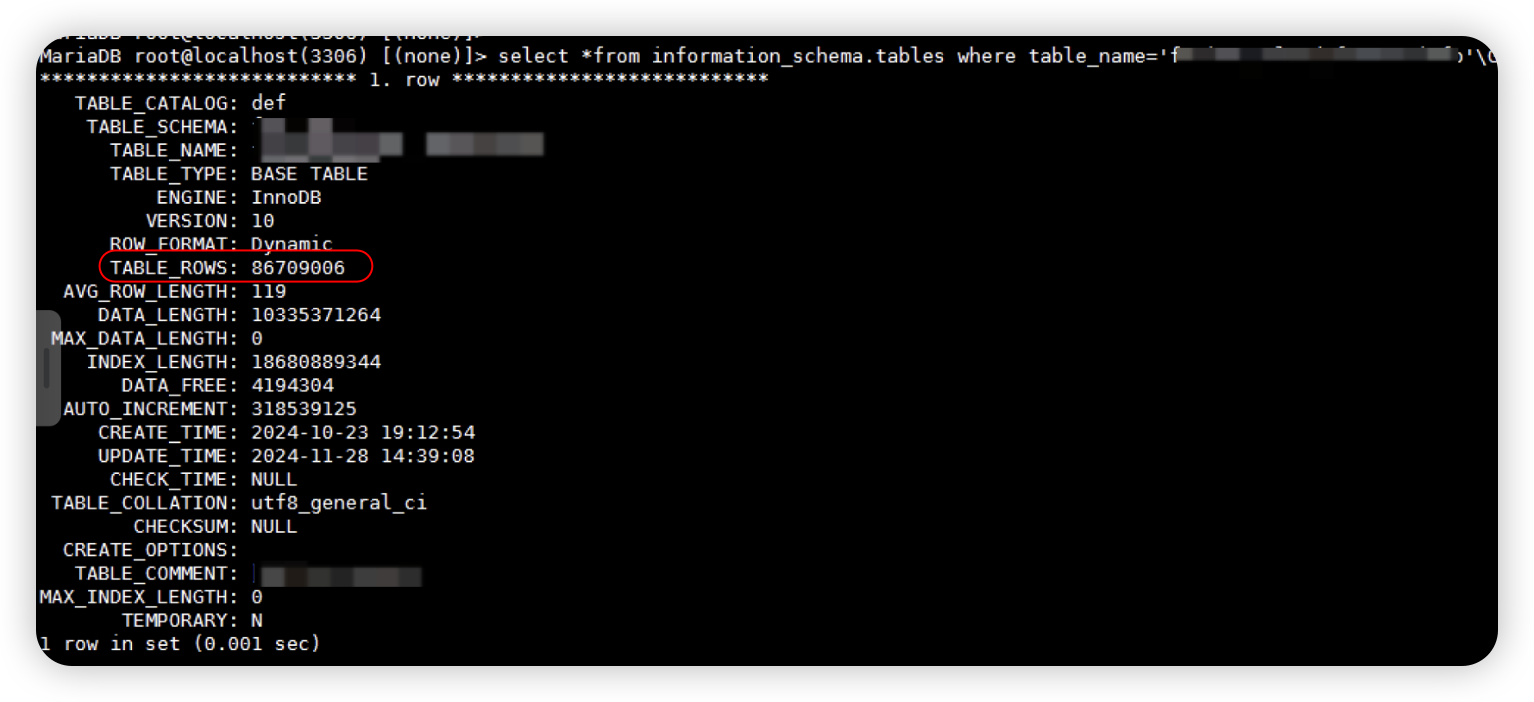
查看140156298594048 ,但在awr和数据库中皆未查找到该tread对应的事务信息,猜测是数据库内部线程(通过对应的bug说明该进程为数据库后台收集表统计信息进程),inset堵塞较久是因为该表数据量较大超过8000W,所有后台线程收集统计信息持有的latch锁较长。
统计当前保留的awr中140156298594048出现的所有次数共300多次

2.9 验证其他时间点140156298594048出现时现象和本次insert堵塞是否一致
通过11月26日awr确认140156298594048该线程同样堵塞了其他的会话,和本次insert产生的堵塞现象完全一致;但因为堵塞的时间较短业务未产生明显感知;

2.10 通过jira查看MariaDB数据库bug列表
通过比对bug列表中编号MDEV-24275,该问题为后台线程收集统计信息时锁定了索引页导致了insert在更新索引时等待数据页latch锁释放导致了偶尔会出现执行时间较长的问题;如果信号量等待600s超时可能会引起mysql服务crash。
该问题普遍存在于mariadb多个版本10.2.35, 10.2.36, 10.3.26, 10.3.27, 10.4.16, 10.4.17, 10.5.7, 10.5.8
该问题修复版本为:10.2.37, 10.3.28, 10.4.18, 10.5.9
三、问题原因
该问题为后台线程在收集统计信息时锁定了索引页导致了insert在更新索引时等待数据页latch锁释放导致了偶尔会出现执行时间较长的问题;如果信号量等待600s超时可能会引起mysql服务crash。
3.1 通过信号量信息中latch等待给出的提示,分析MariaDB 10.3.27 源码文件`btr0cur.cc 1357行、ict0dict.cc 2130行、dict0stats.cc 1969行`如下:
case BTR_MODIFY_TREE:/* Most of delete-intended operations are purging.Free blocks and read IO bandwidth should be priorfor them, when the history list is glowing huge. */if (lock_intention == BTR_INTENTION_DELETE&& trx_sys.history_size() > BTR_CUR_FINE_HISTORY_LENGTH&&buf_get_n_pending_read_ios()) {x_latch_index:mtr_x_lock_index(index, mtr);} else if (index->is_spatial()&& lock_intention <= BTR_INTENTION_BOTH) {/* X lock the if there is possibility ofpessimistic delete on spatial index. As we couldlock upward for the tree */goto x_latch_index;} else {mtr_sx_lock_index(index, mtr);}upper_rw_latch = RW_X_LATCH;break;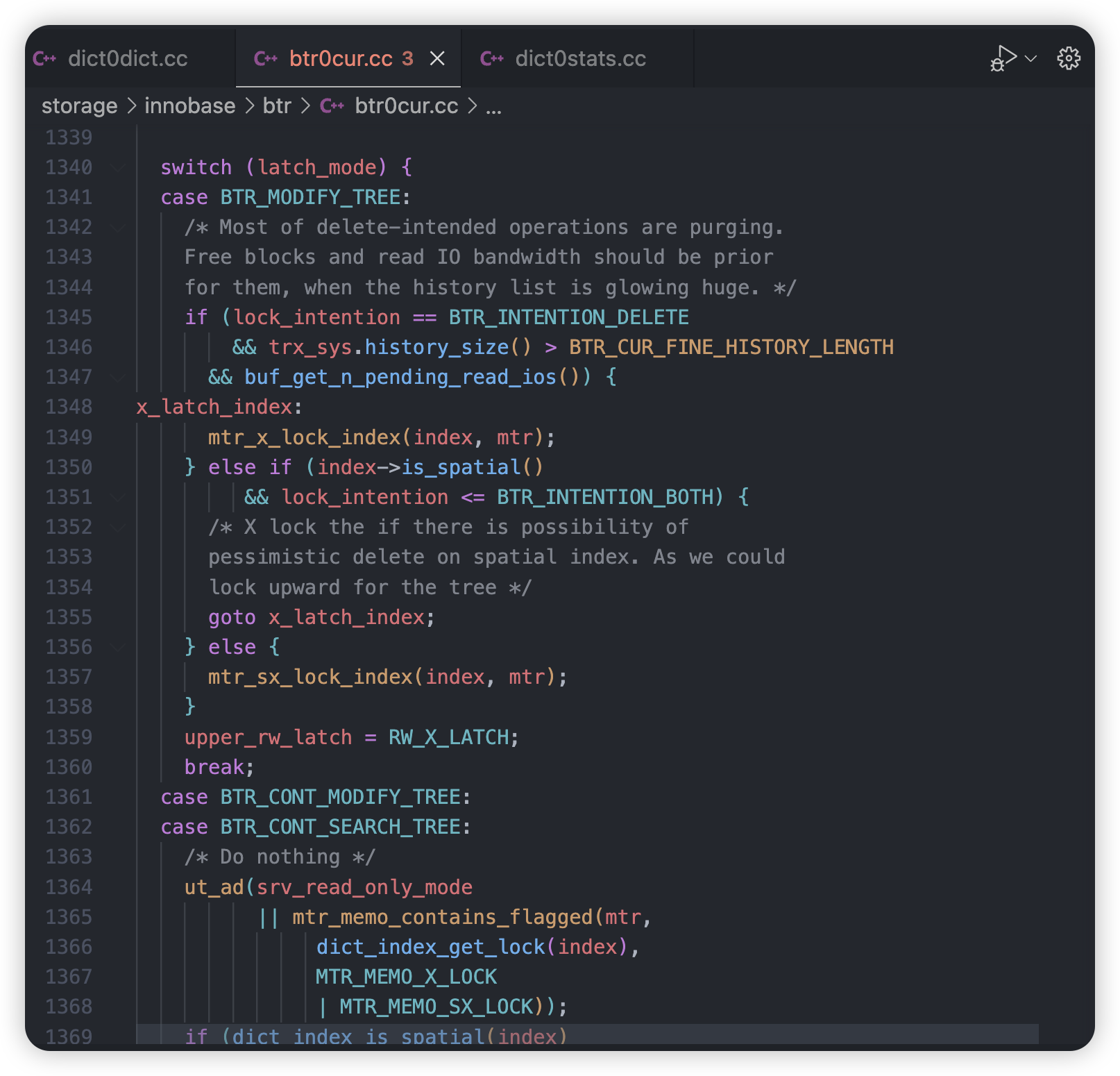
#endif /* BTR_CUR_ADAPT */new_index->page = unsigned(page_no);rw_lock_create(index_tree_rw_lock_key,&new_index->lock,SYNC_INDEX_TREE);new_index->n_core_fields = new_index->n_fields;dict_mem_index_free(index);index = new_index;return DB_SUCCESS;}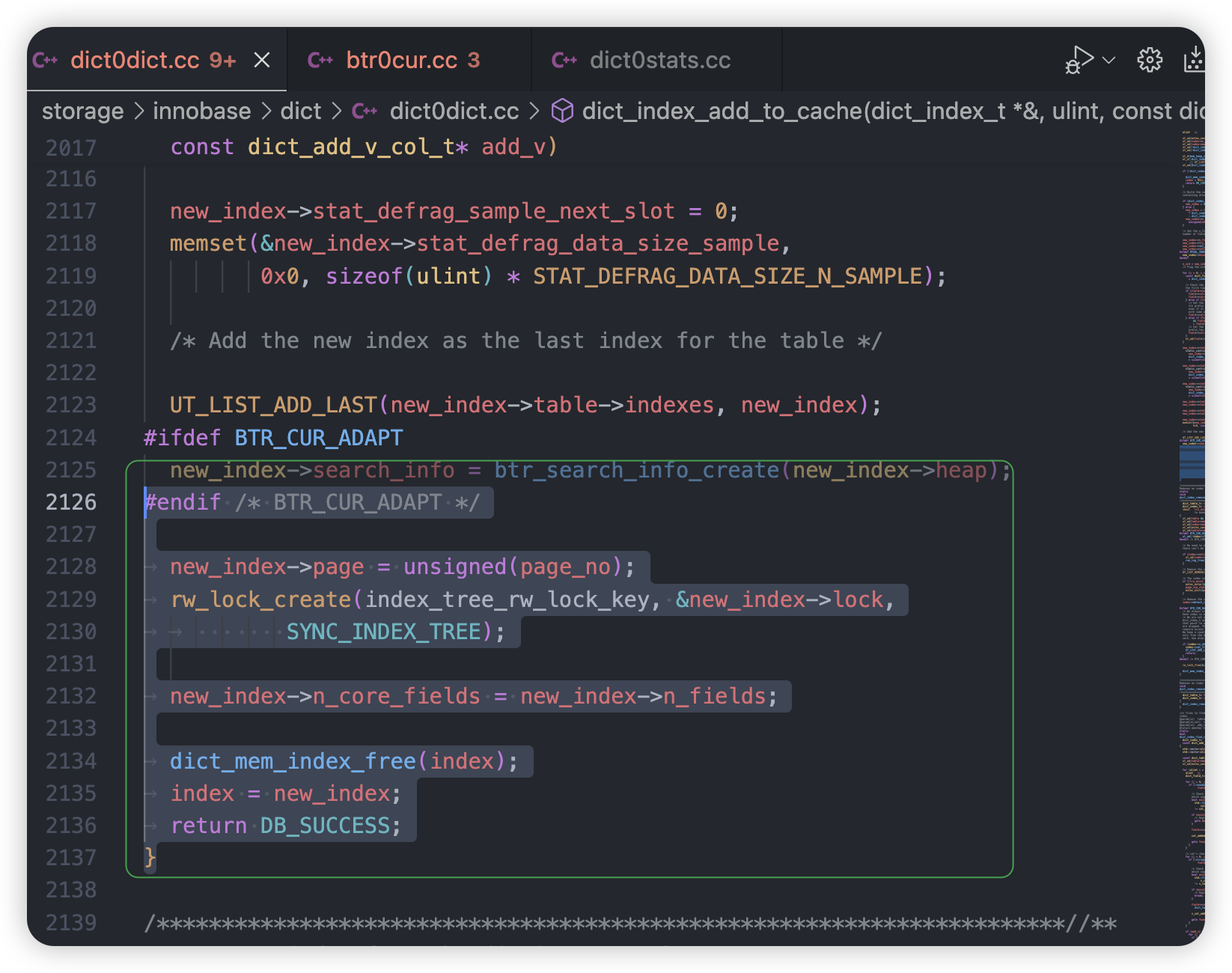
index and saves them to the indexmembers stat_n_diff_key_vals[], stat_n_sample_sizes[], stat_index_size andstat_n_leaf_pages. This function can be slow.@param[in] index index to analyze@return index stats *//* Release the X locks on the root page taken by btr_get_size() */mtr.commit();switch (size) {case ULINT_UNDEFINED:dict_stats_assert_initialized_index(index);DBUG_RETURN(result);case0:/* The root node of the tree is a leaf */size = 1;}result.n_leaf_pages = size;mtr.start();mtr_sx_lock_index(index,&mtr);root_level = btr_height_get(index, &mtr);n_uniq = dict_index_get_n_unique(index);四、解决方案
针对该故障,建议:
1)、临时解决方案:
set global innodb_stats_auto_recalc = 0;
禁用innodb禁用 InnoDB 的自动“ANALYZE TABLE”,但会导致表统计信息不准确影响sql执行计划,慎重选择。
2)、对数据量太大的表进行数据归档、冷热数据分离,降低数据量;减少堵塞时间
3)、如该现象发生太频繁对业务感知影响较明显,请尝试升级到bug修复版本以解决该问题
五、参考文档
https://jira.mariadb.org/browse/MDEV-24275
