




DuckDB:在手机上运行TPC-H SF100基准测试
前言
我2024年04月03日 在 我用手机验证了DuckDB外聚合的强大 文中介绍了用我的Mate60 Pro 进行了 TCP_H SF100 基准测试 和 H2O.ai 数据库操作基准测试 Query 10。
作者: Gabor Szarnyas, Laurens Kuiper, Hannes Mühleisen
原文: https://duckdb.org/2024/12/06/duckdb-tpch-sf100-on-mobile.html

excerpt: DuckDB可在iOS和Android等移动平台上运行,其TPC-H基准测试运行速度甚至超过了20年前大型主机上最先进的研究系统。
几周前,我们进行了一系列实验,旨在解答两个问题:
1. DuckDB能否在新智能手机上完成SF100数据集的TPC-H (Transaction Processing Performance Council Benchmark H) 查询? 2. 如果可以,DuckDB能否在400秒内完成运行,也就是比最初提出矢量化查询处理(vectorized query processing) 的研究论文中所述系统更快?
这次实验过程十分有趣。我们不仅完成了实验,还学习了冷启动(cold run)与极端冷启动(really cold run)的区别。接下来,我们将详细介绍实验过程。
冰火两重天
我们的第一次尝试使用的是一部iPhone 16 Pro[1]。该手机配备8GB内存和一颗6核CPU,其中包括2个性能核心(4.05 GHz)和4个能效核心(2.42 GHz)。
我们使用DuckDB Swift客户端[2]开发应用程序,并在手机上加载了30GB的基准测试数据。实验结果表明,iPhone可以顺利运行工作负载,但手机在运行过程中温度过高,导致CPU进行降频以降低发热量。最终,DuckDB耗时615.1秒,虽然不错,但未能达到我们的目标。
这促使我们思考:如果改善手机散热效果呢?于是,我们用干冰(温度低于-50℃)对手机进行冷却。

效果显著:DuckDB的运行时间缩短至478.2秒,提升超过20%,但仍未达到400秒的目标。

安卓系统可以吗?
接下来的实验,我们选择了一部运行Android 14的Samsung Galaxy S24 Ultra手机[3]。这款手机的硬件配置十分强大:8核CPU包含四种不同类型的核心(1×3.39 GHz, 3×3.10 GHz, 2×2.90 GHz, 2×2.20 GHz),12GB的超大内存,以及配备蒸汽腔[4]的先进散热系统。
我们在Termux终端模拟器[5]中运行DuckDB。我们根据Android构建说明[6]从源码编译了DuckDB CLI客户端[7],并在命令行中运行实验。
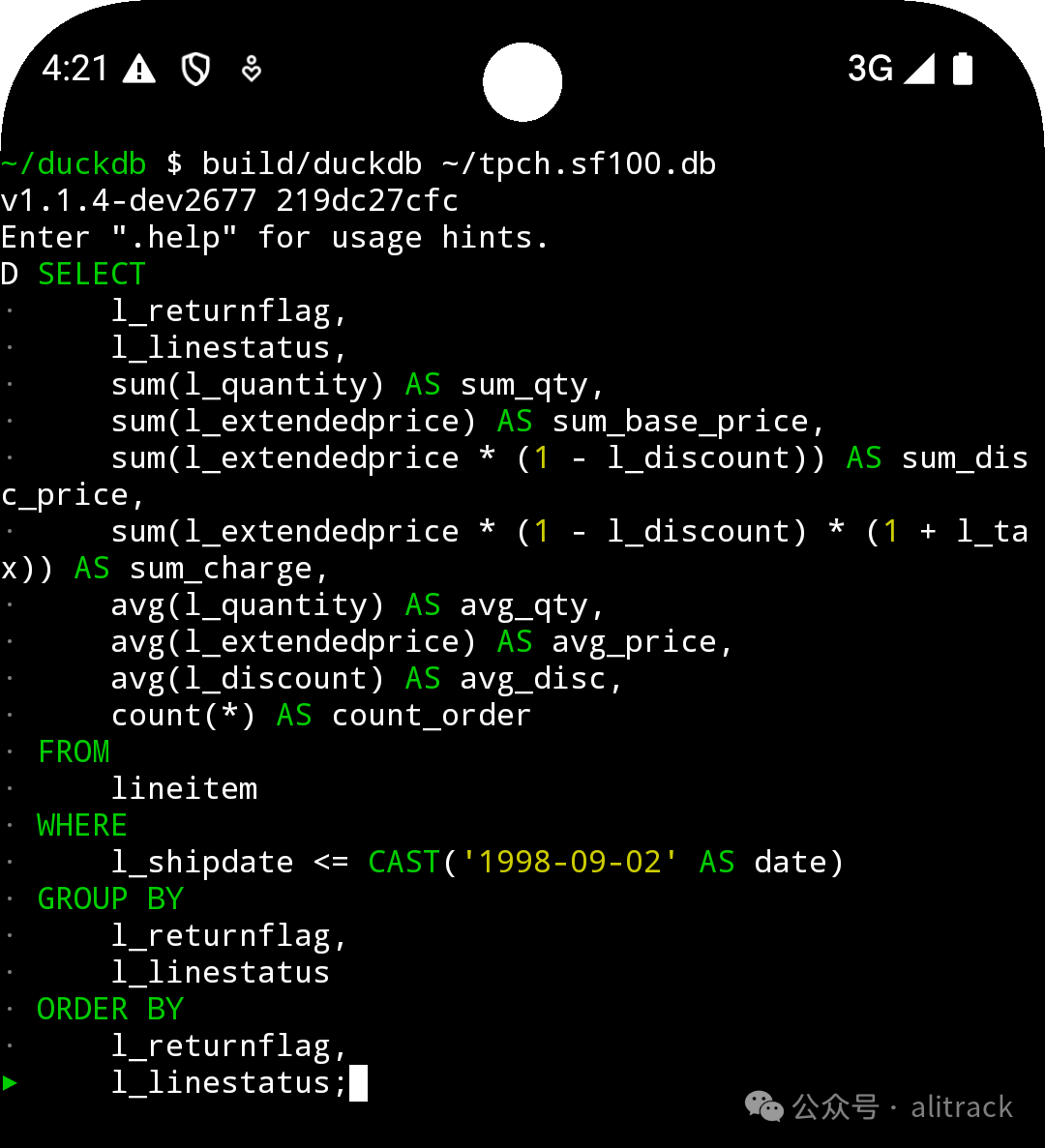
结果远超预期。这款安卓手机仅用235.0秒就完成了基准测试,性能提升约40%。
云端表现
我们也测试了云服务器的表现。我们在AWS EC2上选择了两个基于x86架构的云实例,并使用了实例附加的NVMe (Non-Volatile Memory Express) 存储。
这些云端测试的结果不如手机测试那么令人兴奋。我们在Ubuntu 24.04上启动实例,并在命令行中运行DuckDB。结果显示,r6id.large
[8]实例(2个vCPU,16GB内存)耗时570.8秒,与风冷iPhone的耗时相当。而r6id.xlarge
[9]实例(4个vCPU,32GB内存)耗时166.2秒,比手机上的任何结果都快。
DuckDB测试结果汇总
下表汇总了DuckDB的基准测试结果:
r6id.large | |||
r6id.xlarge |
历史背景
我们为什么要进行这些实验呢?
几周前,DuckDB的诞生地CWI[10]为Dijkstra研究员奖学金[11]举办了颁奖仪式。Marcin Żukowski因其在数据库管理系统开发领域的开创性贡献以及在VectorWise[12]和Snowflake[13]等系统的成功商业化应用而获得该奖学金。
DuckDB借鉴了Marcin研究中的许多理念,其中最重要的是矢量化查询处理(vectorized query processing),它使DuckDB既快速又可移植。他和合著者Peter Boncz和Niels Nes在2005年CIDR论文MonetDB/X100:超流水线查询执行[14]中首次提出了这一概念。
矢量化(vectorization)、超流水线(hyper-pipelining)和超标量(superscalar)这三个术语指的是同一个概念:分块处理数据,这在逐行处理和逐列处理之间取得了良好的平衡。DuckDB的查询引擎也采用了这一原理。
这篇论文发表在2005年1月,其完成时间大约在2004年末——距今近20年!
论文中提到,实验是在一台配备12GB内存的HP工作站上进行的(与现在的三星手机内存相同)。该工作站使用Itanium CPU。

Itanium[15]处理器于2001年发布,目标是高端服务器市场,旨在用一种新的、更注重SIMD (单指令多数据)[16]指令集的架构取代当时主流的x86架构。虽然这一目标未能实现,但Itanium在其发布之初代表着当时最先进的处理器技术。由于主要面向服务器市场,Itanium处理器拥有大量的缓存:实验中使用的1.3 GHz Itanium2处理器[17]拥有3MB的L2缓存,而同期发布的奔腾4处理器只有0.5-1MB。
论文中详细列出了运行时间:
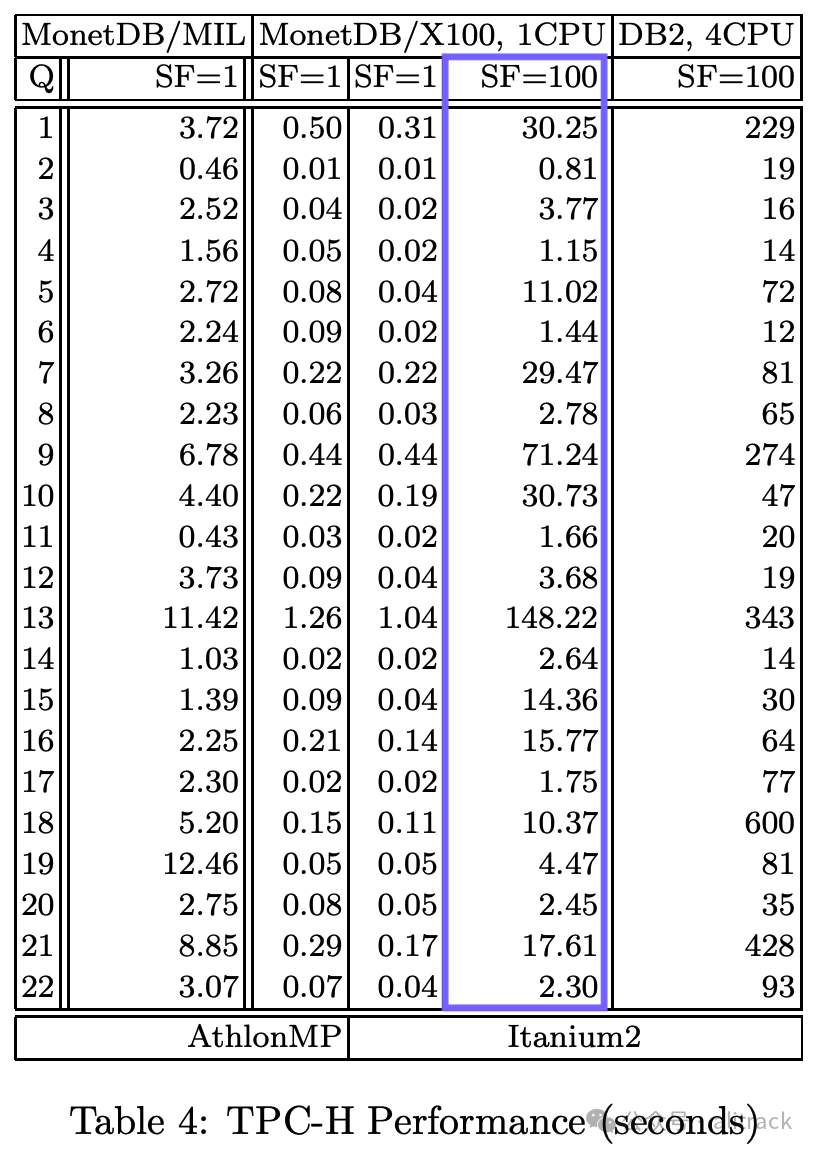
TPC-H SF100查询的总运行时间为407.9秒,这也是我们实验的基线。Hannes在颁奖典礼上介绍了这些结果:
https://www.youtube.com/embed/H1N2Jr34jwU?si=7wYychjmxpRWPqcm&start=1617
下图展示了所有结果:

总结
从最初的矢量化执行论文到在手机上运行分析型数据库,这无疑是一段漫长的旅程。许多关键创新推动了这一成果,其中硬件的进步只是其中之一。编译器优化的进步也至关重要。MonetDB/X100系统需要显式使用SIMD指令集,而DuckDB则可以依靠其精心设计的循环的自动矢量化[18]功能。
现在,让我们回顾一下最初提出的问题。答案是肯定的:DuckDB能够在手机上运行TPC-H SF100基准测试;而且在某些情况下,它甚至超越了2004年运行在高端服务器上的研究原型——这一切都发生在一款可以放进口袋的现代智能手机上。
随着更先进的硬件、更智能的编译器和未来的数据库优化技术出现,DuckDB的性能只会越来越快。
引用链接
[1]
iPhone 16 Pro:https://www.gsmarena.com/apple_iphone_16_pro-13315.php[2]
DuckDB Swift客户端:https://duckdb.org/docs/api/swift.md[3]
Samsung Galaxy S24 Ultra手机:https://www.gsmarena.com/samsung_galaxy_s24_ultra-12771.php[4]
蒸汽腔:https://www.sammobile.com/news/galaxy-s24-sustain-performance-bigger-vapor-chamber/[5]
Termux终端模拟器:https://termux.dev/en/[6]
Android构建说明:https://duckdb.org/docs/dev/building/build_instructions.md#android[7]
DuckDB CLI客户端:https://duckdb.org/docs/api/cli/overview.md[8]
r6id.large:https://instances.vantage.sh/aws/ec2/r6id.large[9]
r6id.xlarge:https://instances.vantage.sh/aws/ec2/r6id.xlarge[10]
CWI:https://cwi.nl/[11]
Dijkstra研究员奖学金:https://www.cwi.nl/en/events/dijkstra-awards/cwi-lectures-dijkstra-fellowship/[12]
VectorWise:https://en.wikipedia.org/wiki/Actian_Vector[13]
Snowflake:https://en.wikipedia.org/wiki/Snowflake_Inc.[14]
MonetDB/X100:超流水线查询执行:https://www.cidrdb.org/cidr2005/papers/P19.pdf[15]
Itanium:https://en.wikipedia.org/wiki/Itanium[16]
SIMD (单指令多数据):https://en.wikipedia.org/wiki/Single_instruction,_multiple_data[17]
1.3 GHz Itanium2处理器:https://www.intel.com/content/www/us/en/products/sku/27982/intel-itanium-processor-1-30-ghz-3m-cache-400-mhz-fsb/specifications.html[18]
自动矢量化: https://en.wikipedia.org/wiki/Automatic_vectorization
