




数据分析求职干货不错过
哈喽大家好,我是数据攻略的六哥~
继上篇文章分享了大厂面经系列之
—— 「快手」数据分析岗面试题解析
由于总篇幅太长,共分成了3个部分
手写sql、深挖简历、开放性Case问题
本篇来兑现文末答应大家的承诺了:
来分享其中第2部分的考点+解析
老规矩,本篇内含:
原题、解析、注意事项
------正文手动分割线------
一、手写sql逻辑(2道)
 )
)对应解析部分上篇已分享,本篇重在第二部分解析)
一、手写sql
▼ 题目预览:
题目1:假设你现在负责直播电商业务,请统计今年双十一开始第一天2024.10.14,该天从零点开始累积到当天结束,进入过大促官方活动直播间的用户数量? 题目2:现有一张用户成交金额汇总表,如何不用中位数函数,求解成交订单GMV的中位数?
🔻 解析参考:
见上篇👉『快手』数据分析岗面试真题+解析(上)
二、深挖简历
▼ 题目预览:
题目1:视频的完播率,请简述检验统计量的构造思路是什么? 题目2:假如在实际工程中,遇到极大数据体量,有什么方法可以高效计算方差?
🔻 方向说明: 由于面试岗位为快手strar-数据分析岗AB实验平台方向,故围绕简历和岗位相关技能做深挖,主要考察点:
统计学基础功底 AB实验相关原理、实战评估经验
面试题目1
视频的完播率,请简述检验统计量的构造思路是什么?
绝大多数人的回答会认为,完播率这个统计量的构造和一般均值检验指标:uv价值、人均观看时长一样,选择好指标后直接进行t检验。
其实不可以。实验组和对照组的完播率计算的样本不满足样本独立性,所以实验组和对照组的完播率不服从正态分布,不可以直接计算,需要修正方差(具体理由如下)
🔻 简答参考:
首先,明确要检验的统计量-完播率定义:
其中:
完整观看视频的次数:指的是用户从头到尾完整观看了视频的次数。 视频总观看次数:指的是视频被点击播放的总次数。
其次,明确实验对象,大多实验的随机单元为用户,假设每个用户的短视频播放相互独立,根据中心极限定理可知:
知识点补充:
中心极限定理:不论总体是什么样的分布,样本的均值逐渐趋向于正态分布
所以,实验组及对照组的人均完播的视频数量均服从正态分布,根据正态分布的可加性,可得到检验统计量:
因为分子分母都是随机变量,分析单元比实验单元更精细,并非独立,所以其实不可以直接利用定义方式来求。
知识点补充:
随机单元:指进行随机分组的对象,如按用户ID随机分组,则随机化单元即为用户; 分析单元:指分析指标的粒度,如平均每笔订单的GMV粒度是订单,平均每个访问用户的GMV粒度为用户。
🔻 考点补充:
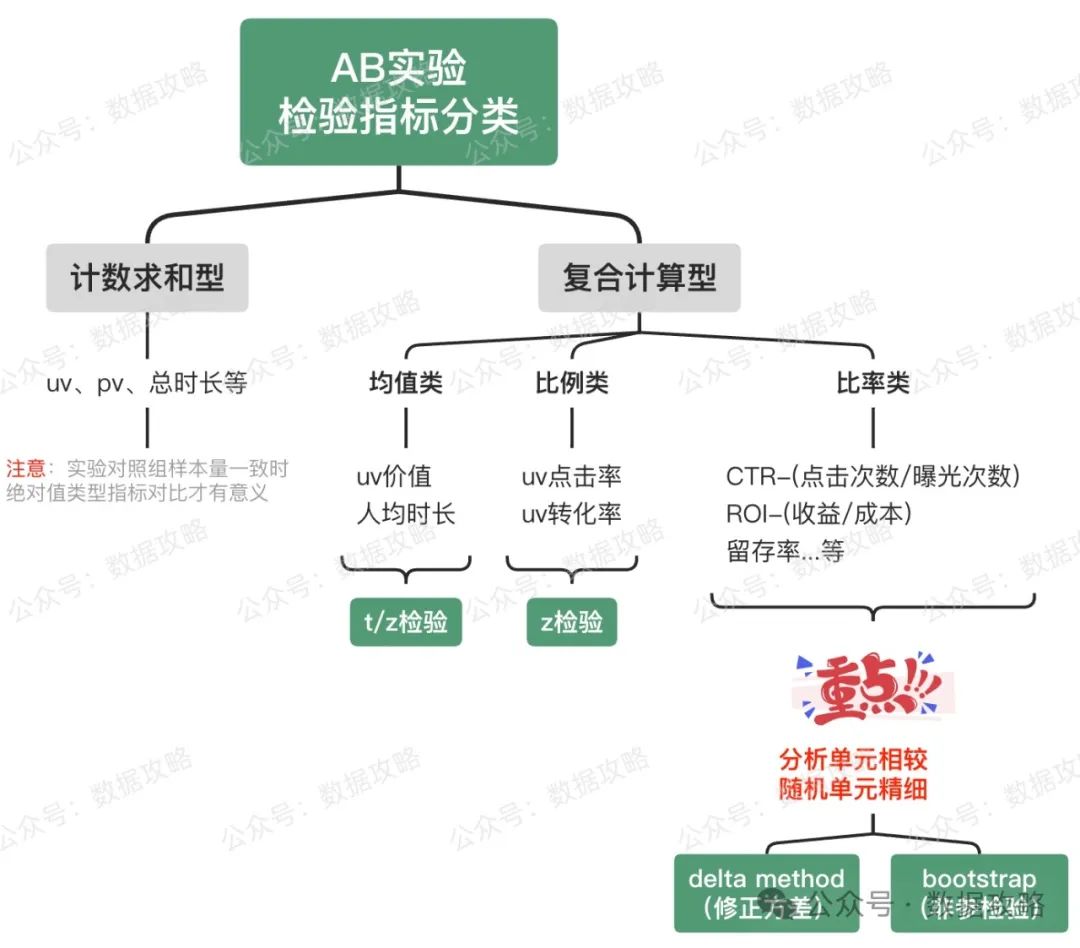
另,不同指标对于方差的计算方法略有不同,之前讲过不同指标类型(求和类、均值类、比例类、比率类)的差异情况:详见👉AB实验中评估指标傻傻分不清 | AB系列(六)
面试题目2
假如在实际工程中,遇到极大数据体量,有什么方法可以高效计算方差?
🔻 出题用意:
由于面试的岗位JD描述是AB实验平台方向,工作中要接触到大量实验的设计+分析评估,所以猜测该问题应该是在做检验评估时的情景会遇到。故在回答时应该有重心、有方向的去引导+界定问题并回答关键。
这个问题的出现可以从工程层面、统计学层面两个角度来解决,结合该岗位的JD描述,我主要回答一下在统计学层面可能有哪些解法:
原理:可以利用样本独立,方差的可加性来将数据分成若干块,分别计算每个块的均值和方差,然后合并结果。
做法:假设将数据分为个块,分别计算每块的均值 和方差 (其中 ),总体的方差为:
其中,
⭐方式二:
原理:也可以利用方差的另一公式 ② 分别计算统计量,效率上会有所提升。
做法:由于传统的方差计算方法①,需要两遍扫描数据:第一遍计算均值,第二遍计算每个数据点与均值的差的平方和,然后除以数据点的数量。这种做法在大数据环境下效率不高。
为了更高效地计算方差,可以采用计算方法 ②,只需要一次遍历的方法,同时计算出:,然后用这些信息来计算方差。
附:①->②具体变换推导如下:
⭐方式三:
原理:可以使用近似算法来估计方差。
例如,通过随机抽样方法来估计整个数据集的方差,这种方法牺牲了一定的精确度以换取计算效率:
总体方差: 样本方差:
三、开放性Case问题
▼ 题目预览(简历问题延展):
题目1:对于快手短视频,如何构建一套指标体系去监控业务的表现情况? 题目2:如何理解并定义流失用户?
第三部分的case解析咱们放到下篇讲~
本文点在看过10,下周更新此部分😎🍻
如若盼 追更 『求职类』干货系列
欢迎大家点赞、转发,最底部点点在看
你的鼓励,真的是对我最大的动力
Ps.求职季ing,如需六哥求职相关帮助
可戳此了解👉六哥的原创课程/求职服务说明
交个朋友先,不定期有一手内推资源传送 ~


 往期好文推荐
往期好文推荐 