




点击上方蓝色【数据攻略】关注+星标~
第一时间获取最新内容
哈喽大家好,我是六哥~
之前咱们讲过Hive高频函数中的
—— 窗口函数 普及篇,含:
工作中应用场景
底层语法知识梳理
以及分梯度案例:主要讲了聚合函数sum()over
<见👉:讲懂高频Hive:窗口函数(一)>
由于最近无论社招还是校招
面试考察sql,看到很多候选人
有关窗口函数考点,手撕不上来
所以本篇就来唠一唠另一大常用
—— 窗口分析函数之
🎯 lead()&lag()over

就明白 这函数 是啥?啥时候用?该咋用?
内含 面试真题+练习题巩固
(注:尾部有练习题库惊喜⭐)
------正文手动分割线------
本文结构速览:
一、应用情景
二、语法定义
三、注意事项
四、面试真题🚩
常用场景
▌窗口函数定义回忆
之前的文章提到过
其实窗口函数 & 聚合函数类似
但是最大的不同用法是:
聚合函数会隐藏正在聚合的行,最后输出一行
窗口函数在执行聚合后,依然可以访问并包括窗口内的特定行的属性,将计算结果添加到结果集中,即按照原行展示。
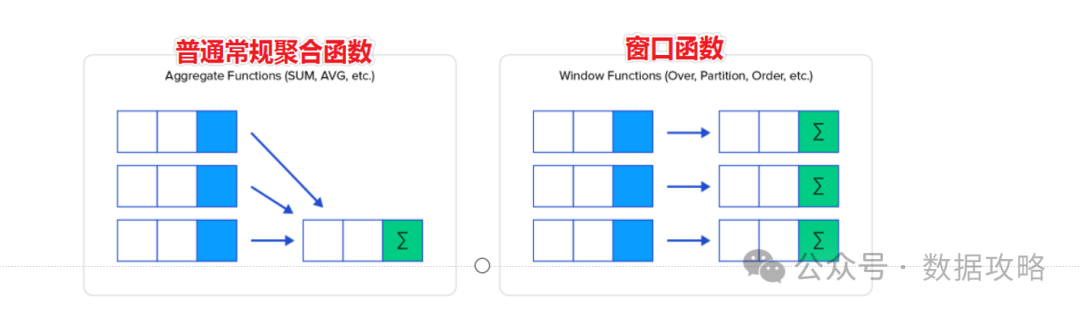
又想要展示聚合前的原行数据
这种 既要又要 的复杂要求
就可以用 窗口函数 来满足!
▌lead/lag() 应用情景
因为数据库存储特性
一般做查询处理,只能在同行数据列上操作
如果需要到在跨行之间做前后查询处理
除了利用多表join的方式来实现
也可以用到此偏移函数在一段sql中实现
在实际工作中,涉及到时间相关的处理
可能经常会用到,例如常见的分析有:
用户行为分析:分析用户行为规律变化
时间序列分析:计算某个指标的同环比
...一切涉及前后偏移查询的数据需求
语法定义
▌lead(col, n, default_val):
▼ 含义:访问窗口分区内,当前行之后第n行的值
▼ 语法:
LEAD(expression, [offset], [default]) OVER ([PARTITION BY partition_clause, ...]ORDER BY sort_clause)
▼ 参数含义:
expression:你想要从下一行获取的列名或表达式。
offset:(可选)指定从当前行开始向后的行数(即偏移量),默认值为1。
default:(可选)如果offset超出了数据范围,返回的默认值,如果不设置,通常为空值。
partition by xx:(可选)指定分区的列,用于将数据分区。类似于group by:都是将数据按照指定的列进行分组,分区列的值相同的行被视为在同一个窗口内。
order by xx:指定数据的排序方式依据。
▌lag(col, n, default_val):
▼ 含义:访问窗口分区内,当前行之前第n行的值
▼ 语法:与lead()类似
LAG(expression, [offset], [default]) OVER ([PARTITION BY partition_clause, ...]ORDER BY sort_clause)
▼ 参数含义:与lead()类似,只是访问的是前n行,而非后n行。
▼ 举例说明:
假设有一个销售数据表sales_data,包含日期、产品线、销量等列。我们可以使用lead()函数获取当前产品线前一天的销量,并进行对比分析。
SELECT dt,product,sales_num,LAG(sales_num,1) OVER (PARTITION BY product ORDER BY dt) AS last_dt_sales_numFROM sales_data;
注意事项
① 参数设置:
第三个参数是默认值(default value),非必填项,需要考虑当指定的行不存在时,默认值该如何处理
返回值类型同expr类型
② 明确范围:
操作的数据是在over后指定的范围内求,若超出分组,函数会重新计算。
不能和同级别的聚合函数一起使用。因为窗口函数是原行附上新计算结果输出,而简单聚合函数是多行变一行输出,放在一起使用,程序无法解读执行目的,故必会报错
③ 易错用法:
常用情景:求的是开窗范围下,按照特定顺序下的往前/或者往后的偏移字段,一般工作中由于数据表有时间分区,所以常用情景是和时间挂钩
易忽视点:如果涉及到求特定时间段的字段偏移量,尤其要注意,能指定的是往前or往后的指定n行,而不是指定的时间偏移分区。
举例:比如求今日dt访问用户的昨日留存,利用lag()往前偏移1行,返回的字段并非一定是相邻日期:dt-1,而是找的用户上1行访问记录,根据用户上次访问的实际日期而定。
面试真题
▼ 问题描述:
假设你现在负责某电商业务线,产品希望得知每日下单的用户规模以及平均复购时长是多少?有以下声明:
其中用户下单后,第二次购买的时间间隔成为复购时间 复购时长大于30天将直接记为流失用户,不参与复购时长计算
购买订单不包含未支付订单
▼表说明:
user_id,用户注册时生成的ID
orderid, 订单ID goodsid,商品ID paystatus,支付状态,退款,未支付,已支付 paytime,支付时间 order_amount,支付金额 goods_num, 购买的商品件数
注意:一个订单可能包含多个商品ID,该表的主键为:orderid+goodsid
首先,明确统计的粒度和范围,即维度是日期,计算的平均指标范围是支付用户,目前的数据表记录粒度和范围都更细更广,故底层需要先做过滤、去重处理
接着,搞清楚所求指标,需要得知用户当前下单距离下次下单的间隔时间,故需要用到lead()函数来获取偏移1行的字段信息
然后,进行处理计算并合并,对每一行用户当前下单时间和下次下单时间,利用datediff做时间差值计算后,再聚合统计每日这群用户的指标均值情况
另外,需要注意的是仅需统计30天的复购行为,所以计算的复购时间间隔应小于30天。
▼ 参考代码:
以下每一步骤序号,对应如上解题思路
 其实还有另外一种自关联实现方法,欢迎挑战,尾部有交流方式!
其实还有另外一种自关联实现方法,欢迎挑战,尾部有交流方式!
--[3]每个用户当前后之后时间做差后求平均SELECT pay_dt,COUNT(1) AS pay_uv,AVG(DATEDIFF(rttn_pay_dt,pay_dt)) AS avg_rttn_daysFROM(--[2]当天下单用户偏移找下次下单时间SELECT user_id,pay_dt,LEAD(pay_dt,1)OVER(PARTITION BY user_id ORDER BY pay_dt) AS rttn_pay_dtFROM(--[1]底层先做过滤、去重处理SELECT user_id,TO_DATE(paytime) AS pay_dtFROM order_infoWHERE paystatus NOT IN ('未支付')GROUP BY user_id,TO_DATE(paytime))t1)t2WHERE rttn_pay_dt<=DATEADD(pay_dt,30) --过滤掉下次下单间隔超过30天的用户GROUP BY pay_dt



 往期好文推荐
往期好文推荐 更多 『求职干货』 & 『日常学习』 原创好文
可去公众号底部tab栏,支持分类检索👇👇👇

Ps. 微信推文改了规则
看完记得设置为 『星标⭐』
不然我会消失的
点个赞&在看呐❤肝『干货』更有动力
